Building a Generative AI application using AWS Step Functions
The original title of this blog post was "Building a Generative AI application to fight WhatsApp vocal messages".
I hate WhatsApp vocal messages, and I am not hiding it:
As I try to experiment more with what the good Gen AI can do for this world, I thought I'd start by solving a use case that have been bothering me since WhatsApp introduced vocal messages support.
The tweet describes the process I took to turn a vocal message into a polished, to the point, and concise text message. This was done in a ClickOps way though. I have created an Amazon Transcribe job in the AWS console to generate the raw text file off of the vocal message, and then I have used the Amazon Bedrock playground to trim the raw text into a summary of half the size using the Anthropic Claude Large Language Model (LLM).
I thought this was a good use case (that could apply beyond WhatsApp) and I started to figure how I would turn this ClickOps approach into a ... Generative AI application instead.
As a learning exercise I have looked into LangChain, but that framework doesn't support Amazon Transcribe jobs as part of its integration arsenal. At that point I thought that, this being a workflow that chains multiple tasks (transcription and summarization), I could try to implement it using one of my favourite AWS services: AWS Step Functions.
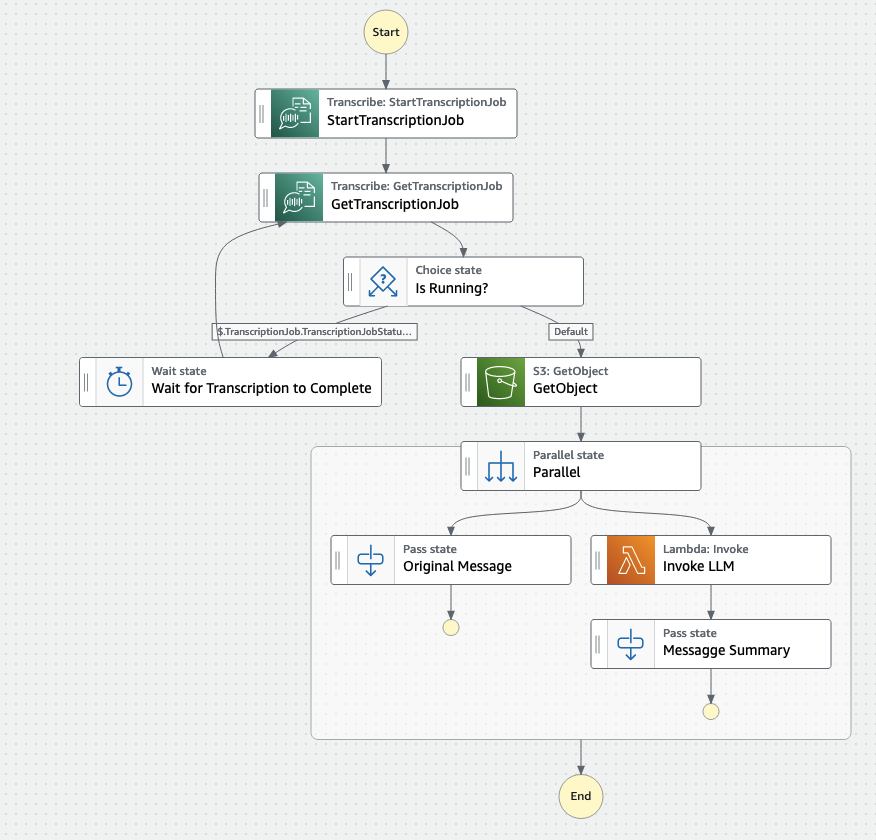
And so I did. The architecture of this workflow is fairly simple:
- there is a
sourceS3 bucket that is where audio files are uploaded - the bucket is configured to generate events on Amazon EventBridge
- EventBridge has a rule defined to trigger the Step Functions state machine upon creation of an object on said bucket
- The state machine:
- runs a Transcribe job and save the raw text in a
outputbucket - reads the raw text file from that
outputbucket (and pass it as an input to a Lambda function) - runs a Lambda function that prompts, in its current implementation, OpenAI for the summarization.
- runs a Transcribe job and save the raw text in a
This is how the state machine looks like in the Step Functions canvas:
This is the source code of the state machine (as it is implemented today):
1{
2 "Comment": "A state machine that fights for good to eliminate the plague that are WhatsApp vocal messages",
3 "StartAt": "StartTranscriptionJob",
4 "States": {
5 "StartTranscriptionJob": {
6 "Type": "Task",
7 "Parameters": {
8 "Media": {
9 "MediaFileUri.$": "States.Format('s3://{}/{}', $.detail.bucket.name, $.detail.object.key)"
10 },
11 "IdentifyLanguage": "true",
12 "OutputBucketName": "whatsapp-mrf-output",
13 "TranscriptionJobName.$": "$.id"
14 },
15 "Resource": "arn:aws:states:::aws-sdk:transcribe:startTranscriptionJob",
16 "Next": "GetTranscriptionJob"
17 },
18 "GetTranscriptionJob": {
19 "Type": "Task",
20 "Parameters": {
21 "TranscriptionJobName.$": "$.TranscriptionJob.TranscriptionJobName"
22 },
23 "Resource": "arn:aws:states:::aws-sdk:transcribe:getTranscriptionJob",
24 "Next": "Is Running?"
25 },
26 "Is Running?": {
27 "Type": "Choice",
28 "Choices": [
29 {
30 "Variable": "$.TranscriptionJob.TranscriptionJobStatus",
31 "StringEquals": "IN_PROGRESS",
32 "Next": "Wait for Transcription to Complete"
33 }
34 ],
35 "Default": "GetObject"
36 },
37 "GetObject": {
38 "Type": "Task",
39 "Next": "Parallel",
40 "Parameters": {
41 "Bucket": "whatsapp-mrf-output",
42 "Key.$": "States.Format('{}.json', $.TranscriptionJob.TranscriptionJobName)"
43 },
44 "Resource": "arn:aws:states:::aws-sdk:s3:getObject",
45 "ResultSelector": {
46 "Body.$": "States.StringToJson($.Body)"
47 },
48 "OutputPath": "$.Body.results.transcripts[0]"
49 },
50 "Wait for Transcription to Complete": {
51 "Type": "Wait",
52 "Seconds": 5,
53 "Next": "GetTranscriptionJob"
54 },
55 "Parallel": {
56 "Type": "Parallel",
57 "End": true,
58 "Branches": [
59 {
60 "StartAt": "Original Message",
61 "States": {
62 "Original Message": {
63 "Type": "Pass",
64 "End": true,
65 "OutputPath": "$.transcript"
66 }
67 }
68 },
69 {
70 "StartAt": "Invoke LLM",
71 "States": {
72 "Invoke LLM": {
73 "Type": "Task",
74 "Resource": "arn:aws:states:::aws-sdk:lambda:invoke",
75 "OutputPath": "$.Payload",
76 "Parameters": {
77 "Payload.$": "$",
78 "FunctionName": "arn:aws:lambda:us-east-1:693935722839:function:openai:$LATEST"
79 },
80 "Retry": [
81 {
82 "ErrorEquals": [
83 "Lambda.ServiceException",
84 "Lambda.AWSLambdaException",
85 "Lambda.SdkClientException",
86 "Lambda.TooManyRequestsException"
87 ],
88 "IntervalSeconds": 2,
89 "MaxAttempts": 6,
90 "BackoffRate": 2
91 }
92 ],
93 "Next": "Messagge Summary"
94 },
95 "Messagge Summary": {
96 "Type": "Pass",
97 "End": true
98 }
99 }
100 }
101 ]
102 }
103 }
104}
This is the source code of the Lambda function (as it is implemented today). Note the prompt I am using:
1import openai
2import json
3import requests
4import os
5
6def lambda_handler(event, context):
7
8 # Sourcing the openai API key from Secrets Manager
9 headers = {"X-Aws-Parameters-Secrets-Token": os.environ.get('AWS_SESSION_TOKEN')}
10 secrets_extension_endpoint = 'http://localhost:2773/secretsmanager/get?secretId=openai'
11 r = requests.get(secrets_extension_endpoint, headers=headers)
12 secret = json.loads(r.text)["SecretString"]
13 key = json.loads(secret)["key"]
14 openai.api_key = key
15
16 prompt = event["transcript"]
17
18 response = openai.ChatCompletion.create(
19 model = "gpt-3.5-turbo",
20 temperature = 1,
21 max_tokens = 1000,
22 messages = [{"role": "system", "content": "You are a helpful assistant.Your role is to summarize the message the user is going to provide."},
23 {"role": "system", "content": "The goal is to cut the size of the following original message in half without losing information"},
24 {"role": "user", "content": prompt }]
25 )
26 return response.choices[0].message.content
Note: for this experiment I have conveniently used OpenAI for the summarization task because Amazon Bedrock is currently in private beta, and it would have required Lambda code hacks to make it work given Bedrock support doesn't ship yet in the publicly available SDKs.
The current implementation isn't very efficient and straightforward and introduces a level of undifferentiated heavy lifting that I would not like to own. For example:
- I had to build my own OpenAI Lambda layer off of this OSS project
- I had to create a secret in AWS Secrets Manager to host the OpenAI API keys
- I had to add another Lambda managed layer (
AWS-Parameters-and-Secrets-Lambda-Extension) to use the code to extract the secrets
Note: I wanted to use the
AWSLambdaPowertoolsPythonV2managed layer instead and use PowerTools to extract the secrets. However, I found that that layer was conflicting with the OpenAI custom layer for some reasons (I was hitting this apparently known problem)
As you can see, there is a number of bumps. While the state machine works I am definitely not satisfied with this setup given all the work required. Hence, I am not working on the IaC to deploy this solution.
I may revisit this solution and refactor the Lambda setup when Bedrock goes GA in order to avoid this "more complex than it should be" setup. At that point I will be able to add the proper permissions to the state machine IAM role and I won't need any AWS Secrets Manager external API key nor any additional Lambda layer.
The idealist in me is also looking forward to Step Functions AWS SDK service integrations adding support for Bedrock at some point so that I could get rid of the Lambda altogether and simplify my entire solution to a hundred-ish lines of IaC. Because I am still convinced that the code you own is a liability.
Massimo.