An example of the importance of prompt engineering
If you have been deep into generative AI, you probably heard about the notion of "prompt engineering". In a nutshell, it's the science that masters how to interact with Large Language Models (LLMs), how to "ask for things". I found this to be a good learning and reference resource.
In this post I wanted to share a basic example of how important prompt engineering is based on a real-life experience.
Background
I have long being saying that the main difference between a traditional Web search and generative AI is that, with the former, you are the knowledge integrator while, with the latter, the LLM is the integrator. Let's say you have a very specific goal or requirement in mind, and it's around deploying a NodeJS program to Lambda that reads from an SQS queue and print the messages on the console (STDOUT).
In the old days you'd search on the web iteratively for your goal, you would find links that talk about how to deploy a Lambda function, other links that talk about how to scaffold a NodeJS Lambda, other links that talk about how to read an SQS queue using NodeJS (probably unrelated to Lambda) and yet other links that show how to print a variable to STDOUT (in case you were not familiar with NodeJS and you needed all the basics).
With generative AI, you'd expect all these pieces to come together "generated" into a single place: the answer to your prompt. For scenarios like these, beyond being accurate and correct, you may want your answer to be very detailed and complete. An answer that allows you to go "from nothing to job-done". I often say that having to click on additional links would be a generative AI anti-pattern because it means the answer was not exhaustive and complete and I have used generative AI as a "search on steroids". You almost want a... "tutorial" that is purposely built around your exact need and use case.
Tests setup and metrics
For my prompting tests I have used Amazon Bedrock because it allows me to get a direct path into a vanilla LLM, an easy way to control and monitor the parameters of my prompt including input/output tokens metrics and Configurations (Temperature, Top P, Maximum Length of the answer,etc.). For these tests I have used Claude V2.1 as the LLM, Temperature = 1, Top P = 1, Top K = 250 and Maximum Length = 2048.
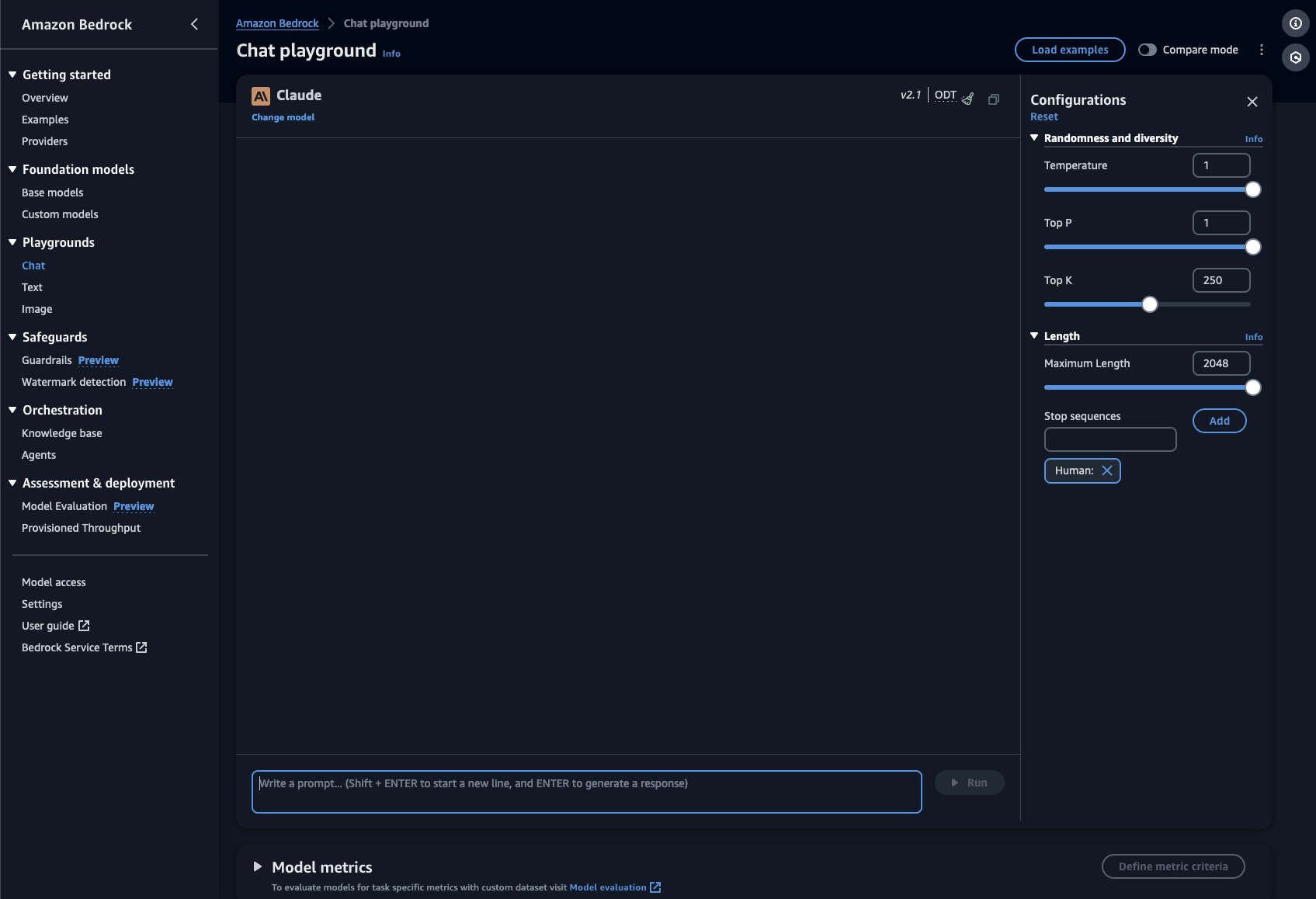
In the remaining of this blog I will only focus on the prompt I have used and on the size of the answer from the LLM (expressed in output tokens as reported by Bedrock). I will not focus on and I will not report the exact text of the answer for all experiments. I will use the number of output tokens as the proxy metric to measure how complete, exhaustive and detailed the answer was. You can run these prompts yourself using Bedrock and see the results first hand.
Prompting exercises
Let's start with the following "basic" and obvious prompt. This is what (understandably) most users would prompt:
1How can I deploy a NodeJS application to AWS Lambda that reads from an SQS queue and print the message to STDOUT?
This produces an underwhelming answer that sits around the ~300 tokens. Not really a "tutorial".
I have then started to massage the prompt to ask for more details and more structure. I did a lot of iterations on this one with lots of trials and errors (or trials and meh?). The best I could figure was the following:
1How can I deploy a NodeJS application to AWS Lambda that reads from an SQS queue and print the message to STDOUT?
2Be as verbose as possible.
3Provide as many information as possible to answer the question.
4Be as exhaustive and detailed as possible.
5Organize the response in separate sections.
6Lay down all the details in each section.
7Provide code examples where possible.
This produces a somewhat better (on the metrics I set above) answer that sits at around ~550/600 tokens. This was almost double the size of the basic one, but I was still wondering if I could do better than this. Something around ~1000 tokens is what I was trying to shoot for. Talking to a few engineers over at Anthropic one of the suggestions was to have an example of a ~1000-tokens answer provided as part of the prompt. This is what's referred to as "few-shot prompting" and it's essentially a way to steer the LLM towards modeling the answer by giving it examples. You can read more about this prompting technique here. Interestingly enough adding a 900 tokens example answer produced a negative effect of only producing an answer around 450 tokens. This was clearly going backwards (despite increasing the input tokens and hence the cost of the prompt)!
After additional researches with the Anthropic team, someone came up with a streamlined, and ridiculously more simple prompt that looked like this:
1Write a long illustrative answer to the following question:
2"How can I deploy a NodeJS application to AWS Lambda that reads from an SQS queue and print the message to STDOUT?”.
3This answer should fill multiple pages and give all relevant information including code snippets.
This simple prompt (with no examples) produces answers in the range of ~900-1000 tokens. Apparently just signaling keywords like long illustrative and multiple pages changed radically how the LLM internals worked and the level of the answer it provides.
Should we all become prompt engineers?
Well, yes and no? This is for sure a nascent discipline and I can see this being a big opportunity for IT professionals. Much in the same way DevOps has been for the last 20 years. But just like for DevOps, not all developers need to be DevOps experts (albeit being one may help). A lot of this prompt engineering could be abstracted away from "consumers" of these technologies. For example this is a simple prototype that I built that has specific prompting behaviours based on some high level user choices and preferences:
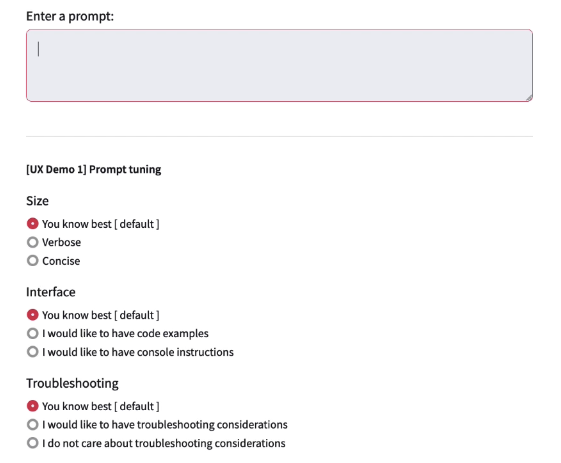
This is rough, but I hope it makes the point come across. Also, I have never claimed to be a UX expert. In this example, based on the preference the user expresses (via those radio buttons) the prompt gets assembled to achieve those goals. If a user prompts a "how-to" question setting the preference for the answer to be Verbose, the prompt to be sent to the LLM would be constructed as follows (thus abstracting the need for the user to understand how to prompt to get a complete, exhaustive and detailed answer):
1prompt = 'Write a long illustrative answer to the following question: "' + user_prompt + '". This answer should fill multiple pages and give all relevant information including code snippets.'
While I haven't spent time optimizing the proper prompting for the Concise option, the following produces an output of ~200 tokens:
1prompt = 'Write a short answer to the following question: "' + user_prompt + '". This answer should be a single paragraph summary.'
I am incredibly fascinated by this prompt engineering world. And if you are getting started with generative AI, it's worth spending time on learning more about this science.
Massimo.