The "dark zone" between the magic GenAI experience and the Large Language Model
In the last few months, the "generative AI" discussions have been dominated by LLMs (or Large Language Models). We ended up short-cutting the (magical) experience you can get and the models that make it possible... as if there was nothing in between. I am going to argue that there is a ton in between (that is not being talked about a lot on Twitter). I am calling this space "Mordor", not because it's "bad" but because it's a dark zone, unknown to the "average user Joe" and it's rarely talked about.
To be completely fair, you don't want to talk about it because Mordor is an implementation detail in the context of the user (or developer) AI assisted experience. The point I am trying to make is that it's not (just) the model that is providing that magical feeling because Mordor is a great chunk of the value you perceive (whether you see it or not).
I define Mordor as the aggregate of things like prompt engineering, orchestration, agents, contexts routing, the ReAct (Reasoning + Acting) logic and plugins just to name a few. These are all concepts that sit between the raw LLM model and the experience you see when you use generative AI interfaces (such as CodeWhisperer in an IDE or ChatGPT in a browser). Part of Mordor is also a set of tools, more often than not open source, that implements some of these concepts. Among the dozens that exist, and that are popping up every day, I have started to play with Langchain and FlowiseAI.
One of the challenges of figuring out what Mordor does, or why it even exists, is due to the fact that people are biased and spoiled by things like ChatGPT (emphasis on Chat is mine). Many associates ChatGPT to the GPT family of Large Language Models but ChatGPT really is a chatbot implementation that happens to use the GPT model as its backend engine. LangChain, for example, has a documented use case for "Chatbots" on their website at this link. As you can see there is "some Mordor" in addition to the core "model" (which is at the foundation). The ChatGPT application goes a step further with the notion of [Plugins] which OpenAI defines as "... tools designed specifically for language models with safety as a core principle, and help ChatGPT access up-to-date information, run computations, or use third-party services". Here, there is "a lot of Mordor".
In my imaginary the LLM is like a car engine and the end-user experience is the car itself. Of course the car has an engine, but what defines the car is much more than that. Please note that Mordor isn't just about putting a nice "web UI" on top of an LLM (in the case of GPT, the OpenAI API playground would provide that). Mordor provides way more value than that. I found this blog post from Avra interesting in this context. Note Avra's blog builds on this repository from Jasper.
If you are interested in this matter I strongly suggest that you go through this simple exercise that shows how LangChain's SimpleSequentialChain can be used to, completely transparently for the user, refine the accuracy of the answer a model can provide.
The "facts checking" example Jasper built queries the model based on a simple user prompt, and then it subsequently creates a workflow that breaks the first answer into assumptions. As part of the chain, the code then challenges the model on those assumptions to figure out if they were correct in the first place. It's somewhat common for a model to provide an answer and, when challenged, confirming the answer was incorrect. Funny enough this is what happened to me when I asked the model What is the biggest clock in the world?. This was its reasoning (this is from the logs of the Streamlit application built following Avra's blog):
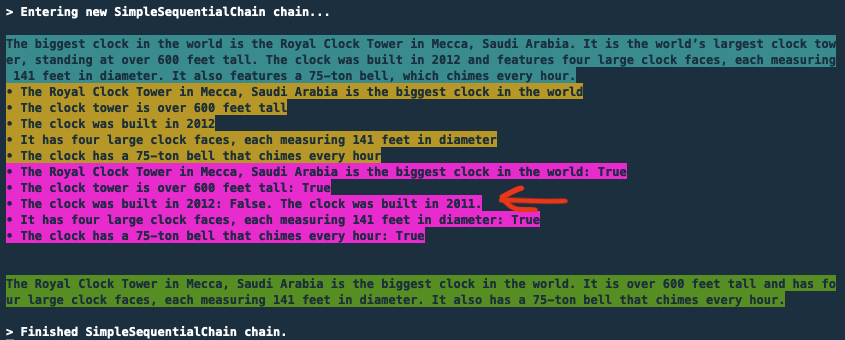
Note how the very first answer (never displayed to the user) included The clock was built in 2012. A subsequent step of the chain asked to validate the assumptions and the model admitted, in its second pass:
• The clock was built in 2012: False. The clock was built in 2011.
It then passes this analysis back to the model that refines the answer. In this case it decided to strip out the date the clock was built.
One other side experiment I did was to query separately and directly ChatGPT and the raw chat OpenAI APIs asking the same question.
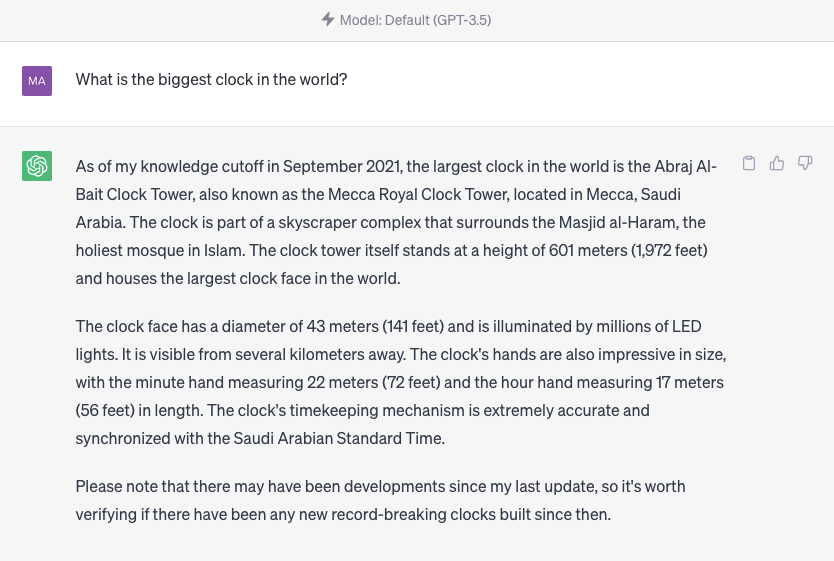
This is what ChatGPT responded:
This is what the raw OpenAI APIs responded:
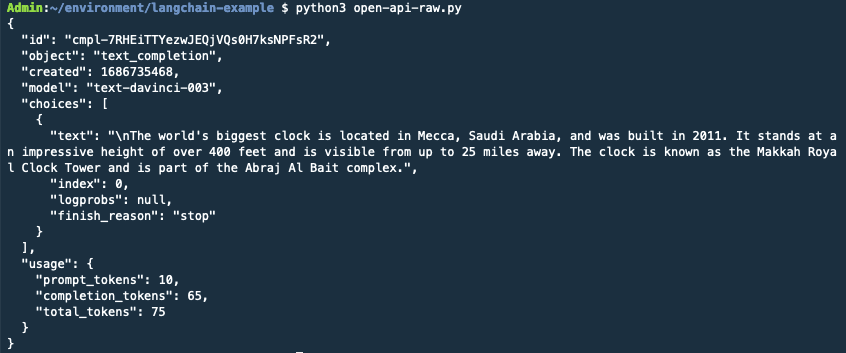
Note how the ChatGPT answer is different and more refined compared to the raw chat API answer.
Also note how this chat API answer is different from the first answer we obtained using LangChain. This is another aspect of LLMs: there is a ton to learn in terms of how predictability, consistency and reproducibility work in the context of generative AI (another reason for Mordor to exist - as we have seen in the facts check example above). Some of these differences could be also explained by the parameters used such as temperature, presence_penalty, and so forth (a discussion that is outside the scope of this short post). Think of ChatGPT as an AI application (a chatbot application in this case) built on top of the GPT family of models where "Mordor" has been abstracted away (as it should).
Of course this was a mere and basic example of the value this "dark zone" between the user experience and the "raw" LLM can provide, but hopefully it was useful to get a perception of how 4 letters can make a difference ("GPT" Vs. "ChatGPT"). Also note that this is not meant to imply that answers re-worked by Mordor are "perfect". They just happens to be "better" (correctness of and trust in the answers provided by generative AI is another topic that is way outside the scope of this post).
Note Mordor is supposed to be filling a lot of other needs such as interfacing the model with data that were not part of the corpus used to train it, modelling the output in specific ways that the LLM would not be able to do, and many, many more. Talking about this, on my short-term to do list there is a task to experiment with the use case documented in this blog post which is about "Building your custom knowledge base chatbot". This one has a lot "more Mordor" than Avra's facts checking example.
Or implementing this much needed workflow as an AI assisted application that can solve for real-life problems:
[ Note to self ] If you are interested in building generative AI applications and experiences, and you are making your baby steps into those, it is likely that Mordor (and what it can do for you) is something you may want to spend time on and fully understand.
Massimo.