Implementing the AWS Elastic Beanstalk worker environment pattern with Amazon ECS
In the last few months, I have talked to a couple of Beanstalk customers that wanted to explore ways to modernize their deployments. They like Beanstalk but they see the value of moving to a more container-native deployment to intercept more modern development tool-chains. This did not surprise me. Beanstalk customers have already been vocal about finding ways to leverage container-centric services to apply a strangler pattern approach for their Beanstalk environments. I talked about one such example in this blog post.
These two customers had something in common which is they are using Beanstalk worker environments. You can read all the details of Beanstalk worker environments in the documentation, but let me create some context. The worker pattern allows customers to decouple their application to run part of the code asynchronously. This often involves polling messages from a queue and act upon them. This is all fine and dandy but there may be a large set of developers that are at ease with web framework but that are not as ease at managing queues. Elastic Beanstalk took the “AWS wants to remove the undifferentiated heavy lifting” literally and introduced a mechanism that take care of reading/deleting the messages from the queue.
But what does this mean in practice? When you deploy a worker node Beanstalk creates an Amazon SQS queue (you can also bring your own, but I am digressing). Beanstalk then runs a managed daemon (called SQSD) on the EC2 “worker” instance that reads the messages from the queue and HTTP POST them to a local HTTP process the customer owns. As I said above, full details are available in the Beanstalk worker environments documentation but this is , in a nutshell, what Beanstalk workers do (right) in comparison to a traditional worker deployment (left):
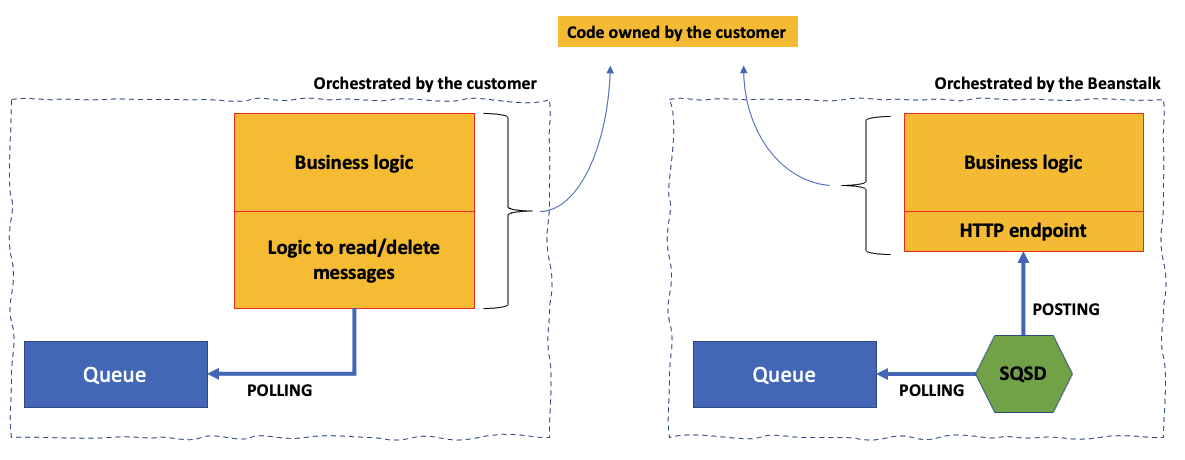
The SQSD component is AWS owned technology that ships only with Beanstalk workers and AWS does not make it available separately. One of the customers I alluded to above pointed me to an open source re-implementation of the SQSD daemon. As I explored more, I found, in a few minutes, 3 other open source re-implementations of the SQSD daemon (here, here and here). Some of these are relatively new, some are archived and they all tend to be implemented in different languages. What I did not realize is that this pattern is extremely popular and how vibrant the community is around this topic.
In an effort to exercise the art of possible I have set aside some time to implement the Beanstalk worker environment pattern using Amazon ECS and one of these open source implementations.
For my prototype, I settled on this open source implementation for a couple of reasons:
- It seems to be fairly active (the last commit is only a month old)
- It’s already packaged as a container and it’s publicly available (so I did not even have to build one - a Dockerfile exists if you want to go down that route)
Note: I am not endorsing nor suggesting using either of these projects for production usage. This is only a prototype built around community projects to prove a concept and gather feedback.
Goal of the prototype
The idea behind this exercise is that, instead of having an ECS task with a container that reads from a queue and implement some business logic, I could have an ECS task with two containers: the simple-sqsd container that reads from the queue and POST messages to an HTTP endpoint in the second container that takes these messages from the request data and implements some business logic.
To implement this prototype I had a few options. I could have authored an AWS CloudFormation template, or I could have built a CDK class but, in the end, I opted to use AWS Copilot (an open source command line interface that makes it easy for developers to build, release, and operate production ready containerized applications on AWS App Runner, Amazon ECS, and AWS Fargate).
The reason why I settled on Copilot is that it ships a number of well known architectural patterns including load balanced services as well as worker services among others. Copilot also documents how to implement a complete Pub/Sub architecture using a combination of these services:
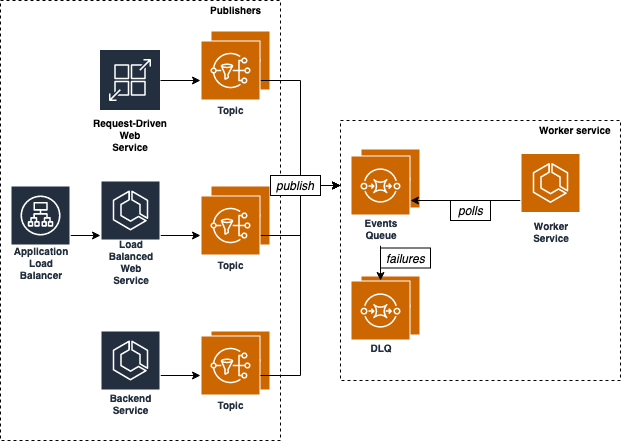
At the high level, this is not different from what Beanstalk does using a combination of web environments and worker environments. For this prototype I will focus only on the right hand part of the diagram above (what’s labeled as “Worker service”).
When you implement this pattern with Copilot there is an assumption that the code running in the worker is polling from the SQS queue. Instead, we are going to tweak the Copilot manifest to inject a sidecar (the simple-sqsd container) into the worker task so that our code can just implement an HTTP endpoint and wait for messages to be POSTed to it. Similar to the Beanstalk worker environment discussed at the beginning and described in the first visual.
We are done with the boring part, now onto the fun part: the doing!
Building the prototype
All you need is an AWS account with proper credentials available, a development environment with Docker installed (AWS Copilot requires Docker to build images) and the AWS Copilot CLI (see the installation instructions).
In an empty folder, create a file called app.py and copy and paste this code:
1from flask import Flask, request
2
3app = Flask(__name__)
4
5@app.route('/', methods=['POST'])
6def businesslogic():
7 data = request.get_json()
8 print(data)
9 ###################################
10 ## your business logic goes here ##
11 ###################################
12 return "", 200
Yep, this is our code. We do not have business logic; we just print to STDOUT so we can capture in the container logs the messages coming from the SQS queue. Note how this code only stands up a Flask HTTP endpoint and has no queue logic at all. We return a 200 if everything goes well in the function which signals simple-sqsd that we have processed the message and it can delete it from the queue. If anything different from 200 is returned to simple-sqsd, the message is not deleted and it will be put back into the queue after the visibility timeout has expired.
We need to have a requirements.txt for our Python application and it could be as simple as (I am definitely not following Python best practices here):
1flask
Next, let’s create a Dockerfile:
1FROM python:3.8-slim-buster
2
3WORKDIR /python-docker
4
5COPY app.py app.py
6COPY requirements.txt requirements.txt
7
8RUN pip3 install -r requirements.txt
9
10CMD [ "python3", "-um" , "flask", "run", "--host=0.0.0.0"
Note: if you are not into Docker, and you do not want to get into Docker, you can explore Cloud Native Buildpacks, a way to package your source code in a container image without having to resort to authoring a Dockerfile. We have a blog that talks about how to do that here. For the purpose of this exercise you have to have a Dockerfile because AWS Copilot does not support Buildpacks at the time of this writing.
We now have all that we need. Assuming you have installed the Copilot CLI, you can follow along.
Run the following command:
1copilot app init
Pick an application name when asked (I picked my-ecs-worker).
Next, we are going to create a Copilot environment.
Note: a Copilot “environment“ is not equivalent to a Beanstalk ”environment”. In Beanstalk the environment represents the application itself whereas in Copilot the environment is a piece of infrastructure that can support multiple applications (the Copilot “services”).
This command starts creating the definition and the core components of the infrastructure required our code:
1copilot env init
When asked, pick the environment name (I picked prototype-environment) and for simplicity keep everything else as default.
The next command actually deploys the environment in its entirety (this includes a new VPC, a new ECS cluster and more):
1copilot env deploy
There are no answers to provide, it will just take a few minutes to complete the preparation.
We are now ready to define our application and deploy it. Run this command to scaffold the application manifest:
1copilot svc init
When asked,
- pick
Worker Service (Events to SQS to ECS on Fargate)as the service type - choose a name for the service (out of impressive lack creativity, I picked
messages-parser) - select
./Dockerfilefor the Dockerfile location
This step should be quick. That command has created the file ./copilot/messages-parser/manifest.yml in the current directory.
This manifest describes, by default, an ECS service comprised of a task with one container. The container will run our application. If you remember, by default, this architecture assumes the application has custom code that polls from the queue. But our application is different because it expects something to POST messages on an HTTP port instead. We are going to edit the manifest file above and inject the simple-sqsd container as a sidecar.
Your original manifest should look something like this (there are lots of comments that you can ignore):
1name: messages-parser
2type: Worker Service
3
4# Configuration for your containers and service.
5image:
6 # Docker build arguments.
7 build: Dockerfile
8
9cpu: 256 # Number of CPU units for the task.
10memory: 512 # Amount of memory in MiB used by the task.
11count: 1 # Number of tasks that should be running in your service.
12exec: true # Enable running commands in your container.
Add the sidecar definition like I am doing in the new manifest below:
1name: messages-parser
2type: Worker Service
3
4# Configuration for your containers and service.
5image:
6 # Docker build arguments.
7 build: Dockerfile
8
9cpu: 256 # Number of CPU units for the task.
10memory: 512 # Amount of memory in MiB used by the task.
11count: 1 # Number of tasks that should be running in your service.
12exec: true # Enable running commands in your container.
13
14sidecars:
15 sqsd:
16 image: ghcr.io/fterrag/simple-sqsd:latest
17 variables:
18 SQSD_HTTP_CONTENT_TYPE: application/json
19 SQSD_HTTP_URL: http://localhost:5000/
20taskdef_overrides:
21- path: ContainerDefinitions[1].Environment[-] # To append
22 value:
23 Name: SQSD_QUEUE_URL
24 Value: !Ref EventsQueue
25- path: ContainerDefinitions[1].Environment[-] # To append again
26 value:
27 Name: SQSD_QUEUE_REGION
28 Value: !Ref AWS::Region
The first thing I am doing is that I am pointing to the existing publicly available container image the simple-sqsd maintainer provides. Alternatively you can build your own image off of the Dockerfile available in the GitHub repository but here I am taking a shortcut for simplicity (don’t do this at home).
The repository lists all the potential configurations the simple-sqsd code supports. Here I am using 4 of them:
SQSD_HTTP_CONTENT_TYPE: this defines the ... HTTP content type.SQSD_HTTP_URL: this tellssimple-sqsdwhere to POST the messages it reads from the queue. Because this sidecar and the main application runs in the same ECS task and they share the network stack,simple-sqsdcan reach our application vialocalhost(the application runs on port5000).SQSD_QUEUE_URL: this tells the sidecar application where the queue is. If you remember, this Copilot service type creates an SQS queue automatically so we need to reference that. In order to do this we use this taskdef_overrides to go out in the resulting CloudFormation template the Copilot manifest generates to grab the SQS queue URL.SQSD_QUEUE_REGION: the simple-sqsd application requires this variable and we are providing this using the same mechanism described for theSQSD_QUEUE_URLvariable. This is handy because it lets us avoid hard coding the region in the manifest.
We are now ready to deploy the service with the modified manifest:
1copilot svc deploy
This will take a few minutes to complete. When it’s done, you can start exploring the SQS console and search for the queue that has been created (mine is called my-ecs-worker-prototype-environment-messages-parser-EventsQueue-V2Vf0ShqBJyt). Similarly, you can explore the ECS console to find the new cluster (mine is my-ecs-worker-prototype-environment-Cluster-fI5p3VZ7qLIP). Within the cluster there will be a service and within the service there will be a task. if you dig deeper you will notice that the task is running two containers (they should be called sqsd and messages-parser if you followed this tutorial).
At the task level you can explore the Log tab. Here you can check all the logs for both containers. If you filter and you focus on the messages-parser container you should see something like this:
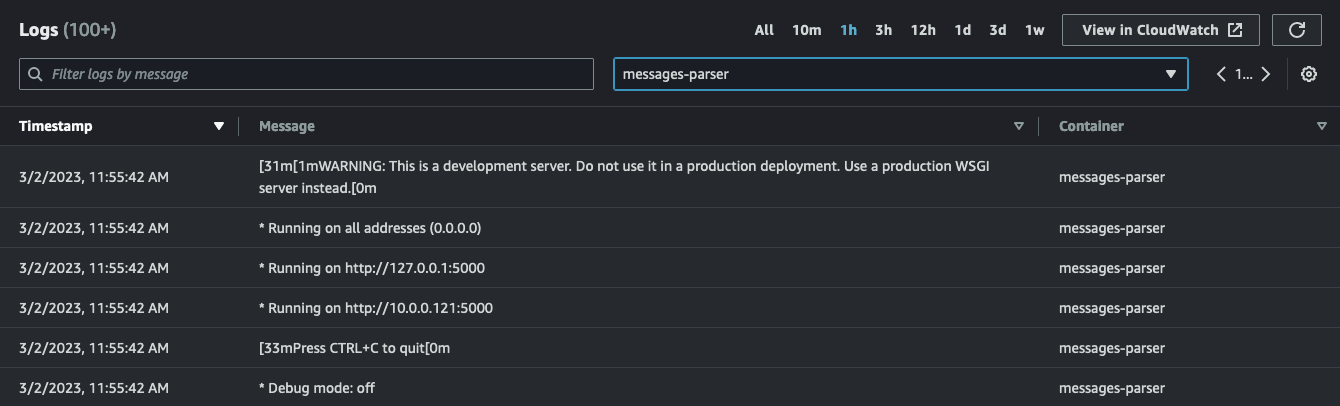
simple-sqsd and posted it to the Python application which has, in turn, printed it to STDOUT:
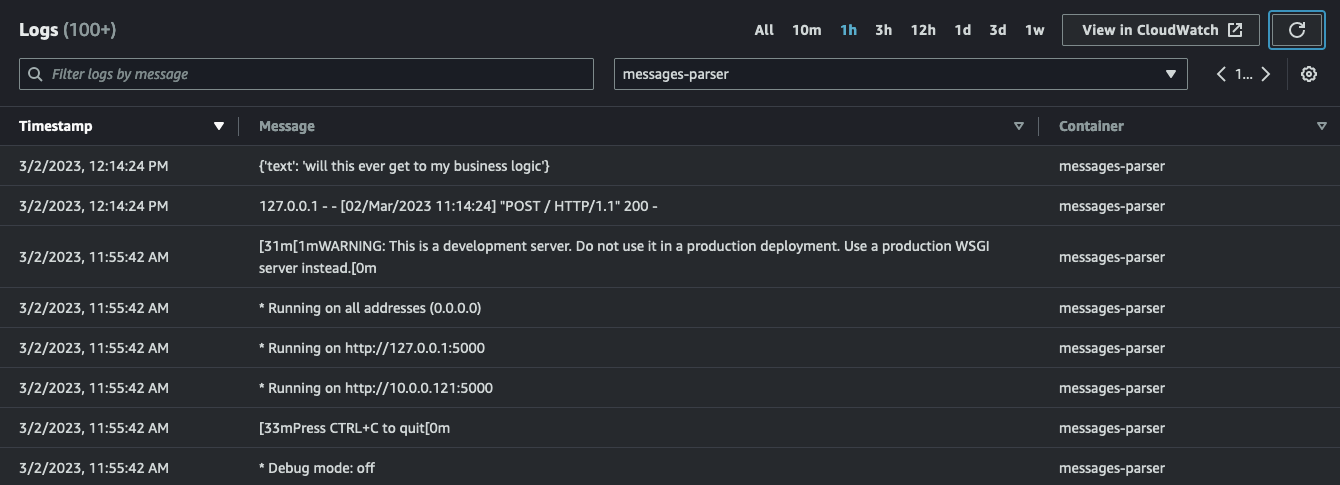
sqsd sidecar container (running the simple-sqsd application) has also received a 200 in response which signaled the code to delete the message from the queue. Without our code having to do anything.
More on why I have used Copilot to build this prototype
As I said at the beginning, Copilot is just an example of how you can implement this architecture. Nothing would stop you from writing CDK or Terraform Infrastructure as Code (IaC) to wrap an SQS queue and an ECS Service that runs the two containers above. Heck, you could even implement the same thing in Kubernetes if you want. At the end of the day what Copilot does is nothing more than turning our commands into CloudFormation IaC that gets executed in the region of choice.
The main reason why I have used Copilot is that it has an embedded out-of-the-box pattern (the “Worker service”) that is very similar to the Beanstalk pattern (the “Worker environment”).
The other reason why Copilot is interesting, which I have not covered with my prototype, is because it abstracts the complexity of scaling your tasks in and out based on metrics such as the number of messages you are receiving, the time it takes to process them and the trad-offs you want to take to size your capacity.
This brief excerpt from the Copilot Worker service documentation is a good example of how its manifest can abstract a lot of this complexity by setting “business oriented” goals that Copilots subsequently translates into auto-scaling target tracking policies (without the customer needing to be an expert in how task auto-scaling works):

Note: this model also supports scaling your tasks to zero when there are no messages in the queue by simply setting the
count.range.minparameter to0in the manifest.
Where could we go from here?
What we have discussed so far mostly assumes that there is another application producing messages in the SQS queue with our application consuming them (using the Beanstalk worker pattern).
But this really opens up an enormous number of possibilities by virtue of SQS being a target of many existing AWS service integrations. The AWS Copilot “Worker Service” pattern talks explicitly about (and make deployment easy for) the Pub/Sub architecture where the producer of events is SNS (and the target is SQS).
Amazon EventBridge is another good example of this flexibility. For example, you could configure an EventBridge rule that, upon a match, sends the matching events to the SQS queue. Thus allowing the ECS task to consume them (through SQS messages).
Possibly, even more interestingly, this opens up additional scenarios using Amazon EventBridge Pipes, a feature of EventBridge. From the doc: “[Pipes] reduces the need for specialized knowledge and integration code when developing event driven architectures, fostering consistency across your company’s applications. To set up a pipe, you choose the source, add optional filtering, define optional enrichment, and choose the target for the event data.”
This is a list of sources supported and this is a list of targets supported by EventBridge Pipes. Note how SQS is a target for Pipes.
On the back of my prototype, I have configured a pipe that connects an Amazon Kinesis stream to my SQS queue (the one created by AWS Copilot). This is how my pipe looks like in the EventBridge console:
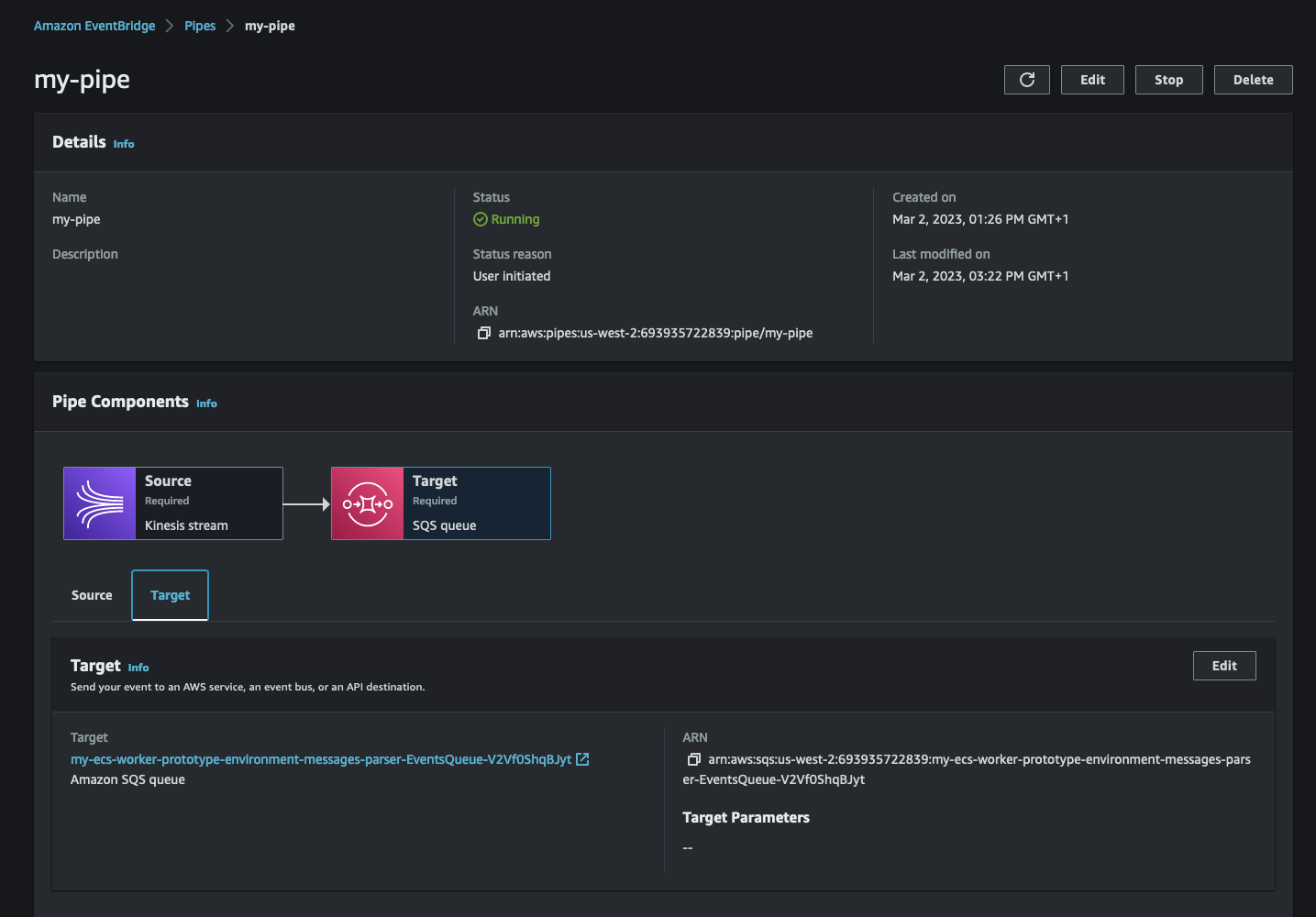
sqsd sidecar.
Note that the Kinesis stream is ordered while the queue isn’t. This scenario is only provided as an example and it may not fit your use specific case and requirements.
This is what my message-parser container log looks like while my pipe is running and my script is pumping data into the stream:
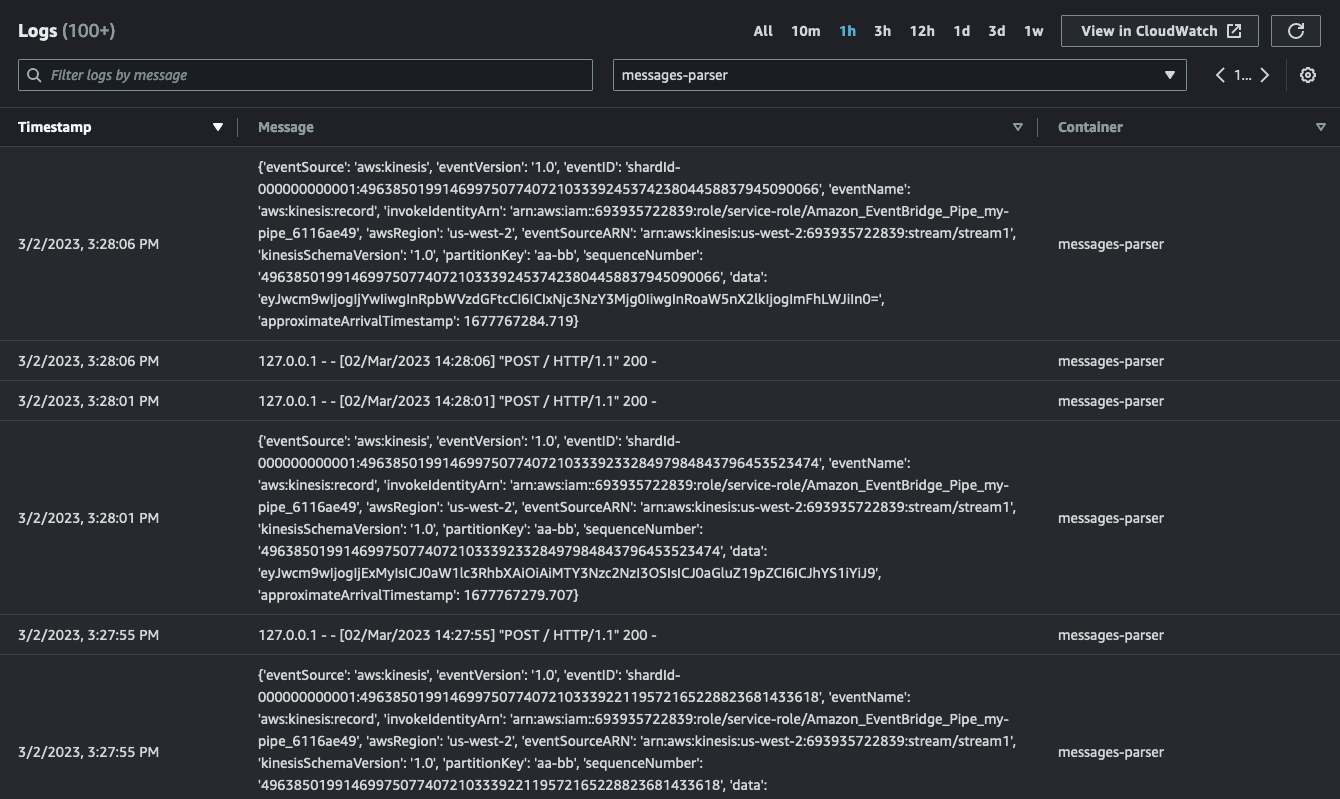
Conclusions
In this blog post I have explored how Amazon ECS can be used to implement a “worker” pattern by using the Copilot out of the box templates (with some minor tweaks). I am very eager to hear from ECS and Beanstalk customers if there is appetite to implement in ECS the SQSD model. More broadly, I'd be interested to hear how an ideal “ECS event-driven native awareness” (for lack of proper terminology) should look like for your specific needs.
Reach out if you have opinions!
Massimo.