Cloud Native Applications (for Dummies)
There have been attempts lately to describe "modern applications" or "modern workloads".
A good attempt is The Twelve-Factor App.
It's a great way to describe such workloads but I think those concepts would need to be dumbed down an order of magnitude to get the average Joe to digest them properly.
That's what I would like to do in this blog post. We will lose some important details by doing so but that's ok.
Let me go straight to the point: at the very (and I mean very) high level a cloud native application is an application that has a clear separation between "infrastructure" and "data". There is no way, in my opinion at least, to design a cloud native application without drawing this clear separation.
I am using data as a very loose term here. You are probably thinking about a "data-base" (which is ok) but that should really include things like "configurations".
An alternative way to describe this separation could be "capacity" and "state". More on this later.
Let's start right away with a picture to graphically depict this concept:
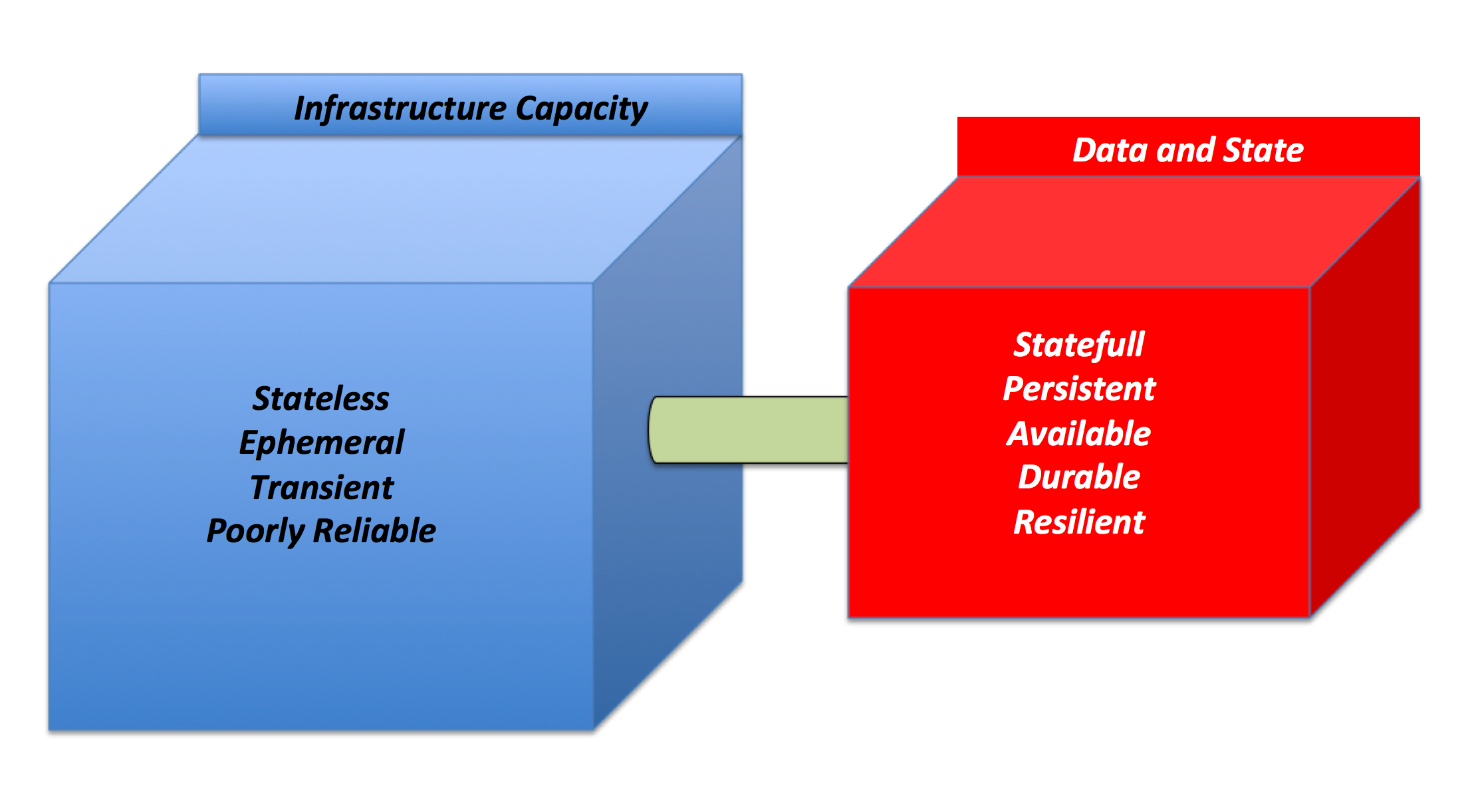
Note the characteristics of these two domains.
The infrastructure capacity doesn't have a state of its own (stored locally at least) that you need or want to protect.
It's completely stateless, you can (re)create it easily through automation and, as such, it doesn't need to be resilient.
On the other hand the domain that hosts your persistency (in every possible shape and form) has completely different characteristics as it needs to be reliable, highly available, durable and all that.
At this point, you may wonder how this is different compared to traditional patterns in 3 Tier web applications. In my opinion, cloud native applications push the envelope to the extreme when it comes to splitting traditional "application tiers" from traditional "data tiers".
The Infrastructure Capacity Domain
This is where the virtual machines (aka instances) hosting the code of our cloud native application live. They are completely stateless, they are an army of VMs all identically configured (on a role-basis) and whose entire life cycle is automated. In such an environment traditional IT concepts often associated to virtual machines do not even make any sense. See below for some examples.
- You don't install (in the traditional way) these servers, because they are generated by automated scripts that are either triggered by an external event or by a policy (e.g. autoscale a front end layer based on user demand)
- You don't operate these servers, for the same reason above.
- You don't document what those servers do and how to provision them, because the code that generates them is the documentation.
- You don't backup these servers, because they don't have state. If you lose them, you re-instantiate them from scratch.
- You don't migrate these servers from one place to another, for the same reason above. You re-instantiate them from scratch.
- You don't protect these servers with high availability features provided at the cloud platform level. There is nothing to protect and if they fail, you re-instantiate them.
- You don't size an infrastructure for these servers, you pay for what you consume at any given point in time.
You essentially configure the infrastructure that runs your code as a piece of code itself. Have you ever heard about the "infrastructure as code" concept? That is it.
As of today it is fairly common to see these type of patterns being implemented using a combination of provisioning tools that then hand off control to configuration management tools.
The idea is to provision VMs and let the configuration tools create the proper personalities and roles inside the guests.
AWS Cloudformations, HashiCorp Terraform, VMware Application Director, RightScale CMP are examples of tools that focus on the programmatic initial provisioning of instances.
Puppet, Chef, Ansible (and many others) are configuration management tools that focus on making sure the instances converge, through automation, to a given consistent configuration and state.
This is pretty much the current status (and best practices) as of late 2014.
However a couple of new trends and patterns are on the rise. They may ultimately converge and, in a way, you may look at them as one single trend.
The first one is referred to as immutable workloads. What we have discussed so far is referred to as mutable workloads, meaning that their configurations can change overtime as the configuration management tools configure and reconfigure them as needed to make them converge to a desired end-state. In other words current best practices for cloud native applications suggest to provision a base template and use configuration management tools inside the OS to make that core template converge to a specific configuration. The philosophy behind immutable workloads suggests instead that instances should be immutable and, if you need to reconfigure an instance (e.g. to update the application code), you should destroy it and redeploy it with the up-to-date configuration baked into the template right away.
The second trend is towards the simplification of the entire stack that comprises these workloads. At the moment the common practice is to use virtual machines as a placeholder for the run-time (e.g. AWS EC2 instances or VMware virtual machines). There is a new school of thoughts these days that say virtual machines are too big, too bloated and too heavy for cloud native applications and that containers are a better way to package and deploy cloud native applications. I am sure you have heard about Docker and the momentum (or tech bubble?) around it. This also aligns well to another trend (microservices) but this would be too much for a single blog post.
Interestingly, many also see this containerization trend as just an intermediate step towards something even bigger (err, or smaller should I say?). At Re:Invent 2014 AWS has introduced a new service called Lambda that allows a cloud native applications developer to write code and stick it to a piece of data. When data changes, the event triggers the code to run. There is no virtual machine, there is no container you deal with, the code just runs, out of the blue. In other words, the infrastructure doesn't get simplified, it just disappears.
The following picture describes graphically this concept:
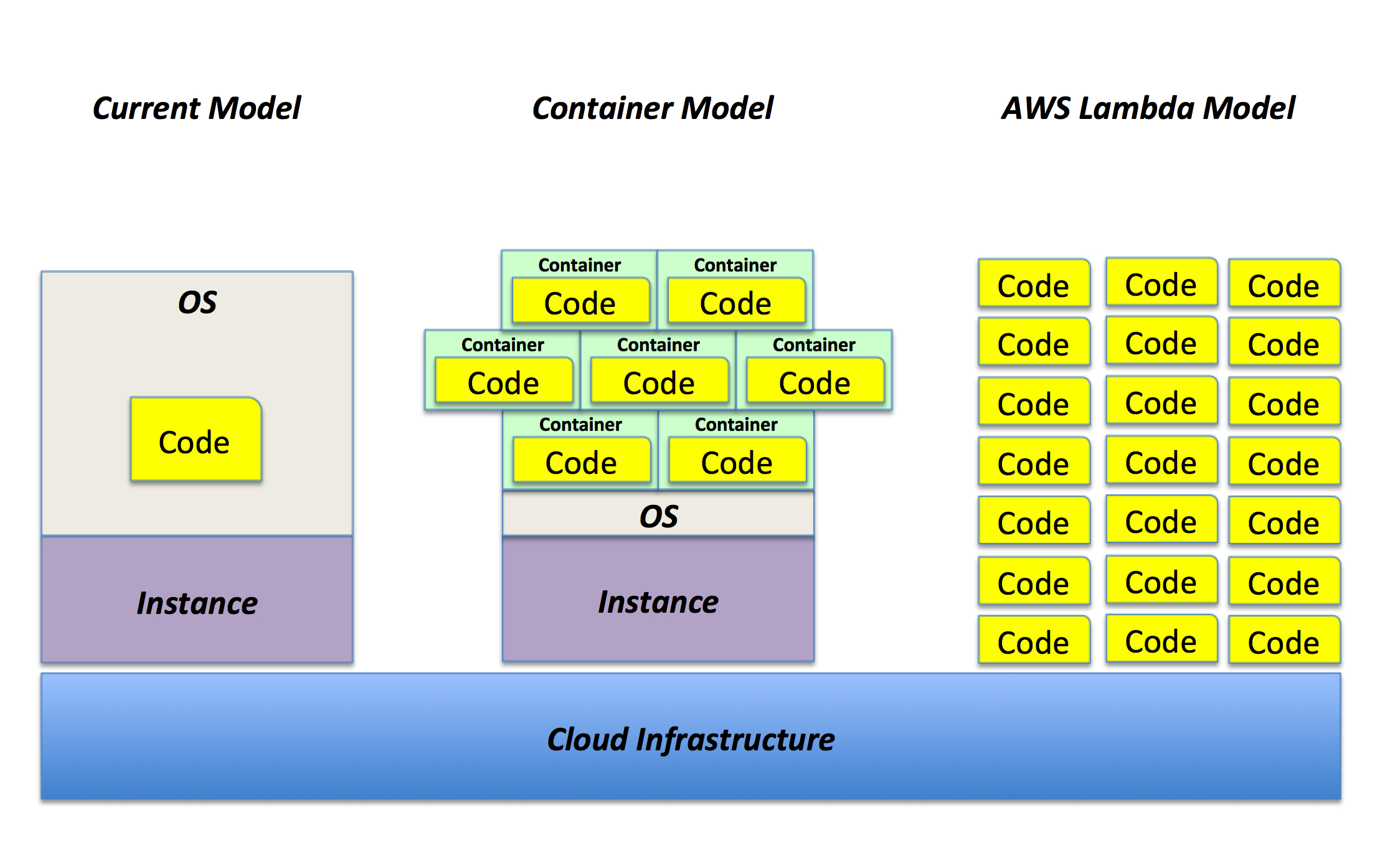
As you can imagine some of these concepts leads the conversation into a more PaaS-ish model.
The Data and State Domain
Teletransport yourself into another dimension now.
Switch your mindset.
Here persistency and resiliency do matter. A lot.
There are a few things that fall into this domain.
The most important one is where you host your user data. Think of a traditional (relational) database but it could also be a repository of non structured data (e.g. object storage, NoSQL). More often than not these services are offered as managed services by the cloud providers. While nothing would stop someone writing a cloud native application to deploy and manage their own database (relational or not), it's way more common to leverage managed services like AWS RDS or AWS DynamoDB.
The advantage of this (optional but valuable) approach is that you have your persistency and reliability guarantees while not spending time to make that happen yourself.
In the end, a cloud provider that manages hundreds if not thousands of instances in a completely automated way does a better job than someone that invent himself or herself as a part-time DBA. Particularly if this someone is a developer.
The peculiarity of these cloud managed services is that they (often) scale linearly and horizontally.
Think about an object storage for example where you can host an unlimited (or the perception thereof) amount of data.
Think about services such as AWS DynamoDB where you only have to subscribe to performance SLAs and the cloud provider will manage the capacity required (behind the scene) to deliver that SLA.
Traditional relational data bases (albeit managed, such as AWS RDS) do not usually provide this perception of infinite scalability because they often scale up (not out) and there are practical limits on how big a cloud instance backing a managed data base can be.
Depending on what you choose there will be a variable degree of visibility into the infrastructure and core operational procedures but all of these solutions alleviate a lot the burden of making the persistency domain scalable, highly available and resilient.
The second set of persistencies that fall into this domain is the description of how the infrastructure, along with the application stack, needs to be deployed, scaled and operated. I call it the infrastructure state.
Here you describe things like:
- how the core infrastructure should look like (aka "infrastructure as code")
- the repository of your application to instantiate
- the application configuration.
Digression: separating application code from application configuration is a best practice described in The Twelve-Factor App manifesto. By doing so you can instantiate different environments (development, test, staging, production) by simply pointing to a different application configuration. Modularity (at any level) rules in cloud native applications.
This second set of persistencies in the data and state domain could be implemented in different ways. It could be one of (or more likely many among):
- a set of AWS Cloudformations templates that describe how your infrastructure capacity is modeled
- Puppet, Chef, Ansible, Saltstack and/or Terraform assets that make your VMs converge to a given configuration at run-time
- a service such as GitHub that hosts the "code" of your application
Note that the infrastructure state is only conceptually tied to the user data in that they share the same requirements (consistent, reliable, durable, etc). However these services could be physically separated.
While these days it is fairly common to go all-in with a single cloud provider to keep all these environments together (infrastructure capacity domain and the data and state domain) one could also think at them as loosely coupled environments (e.g. infrastructure capacity delivered by 2 cloud providers, business data hosted in a third cloud provider and infrastructure state hosted somewhere else).
Let's Put It All Together
If you try to put all of the above together into a more detailed picture this is how a cloud native application would look like.
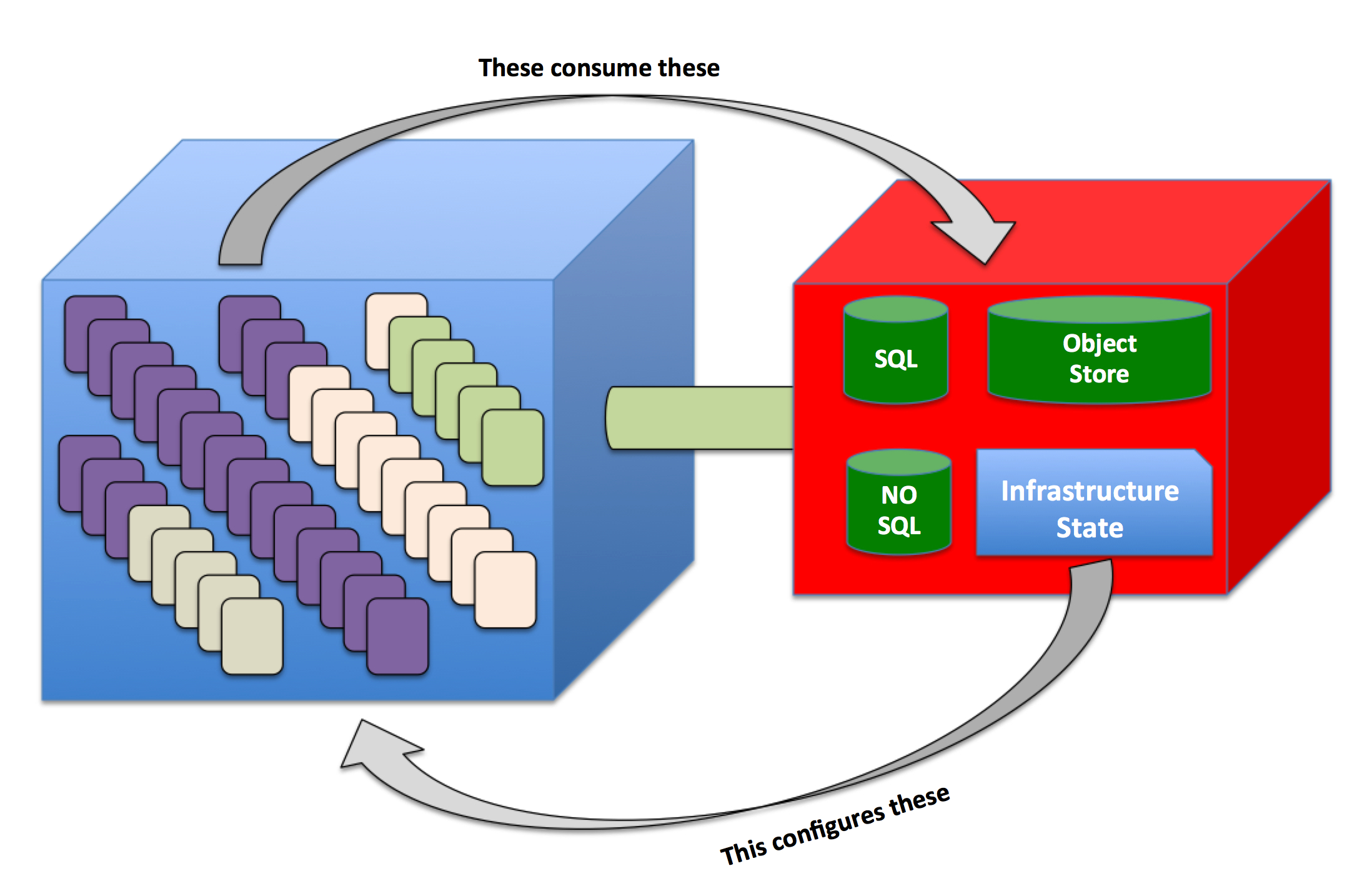
The infrastructure gets instantiated (and operated) per the logic in the infrastructure state described above and, at run-time, the application deployed in the capacity starts to consume and interact with the user data (e.g. databases, object stores, etc).
What's missing from this picture (among many other things) is the scalability nature of these two domains. This is another core tenet of a cloud platform that I am not focusing enough in this post. Both environments can naturally grow and shrink based on external triggers (such as a growing number of application users or a growing set of data to be managed).
As a result the application owner will pay for the actual resources that are being used by the application.
Where Do You Stand Today?
We have just described how a cloud native application looks like.
But where do you stand here?
It is very likely that, unless you are a Netflix style organization, you are not (yet) doing what I pitched above.
Very likely your workloads may look more or less like this:
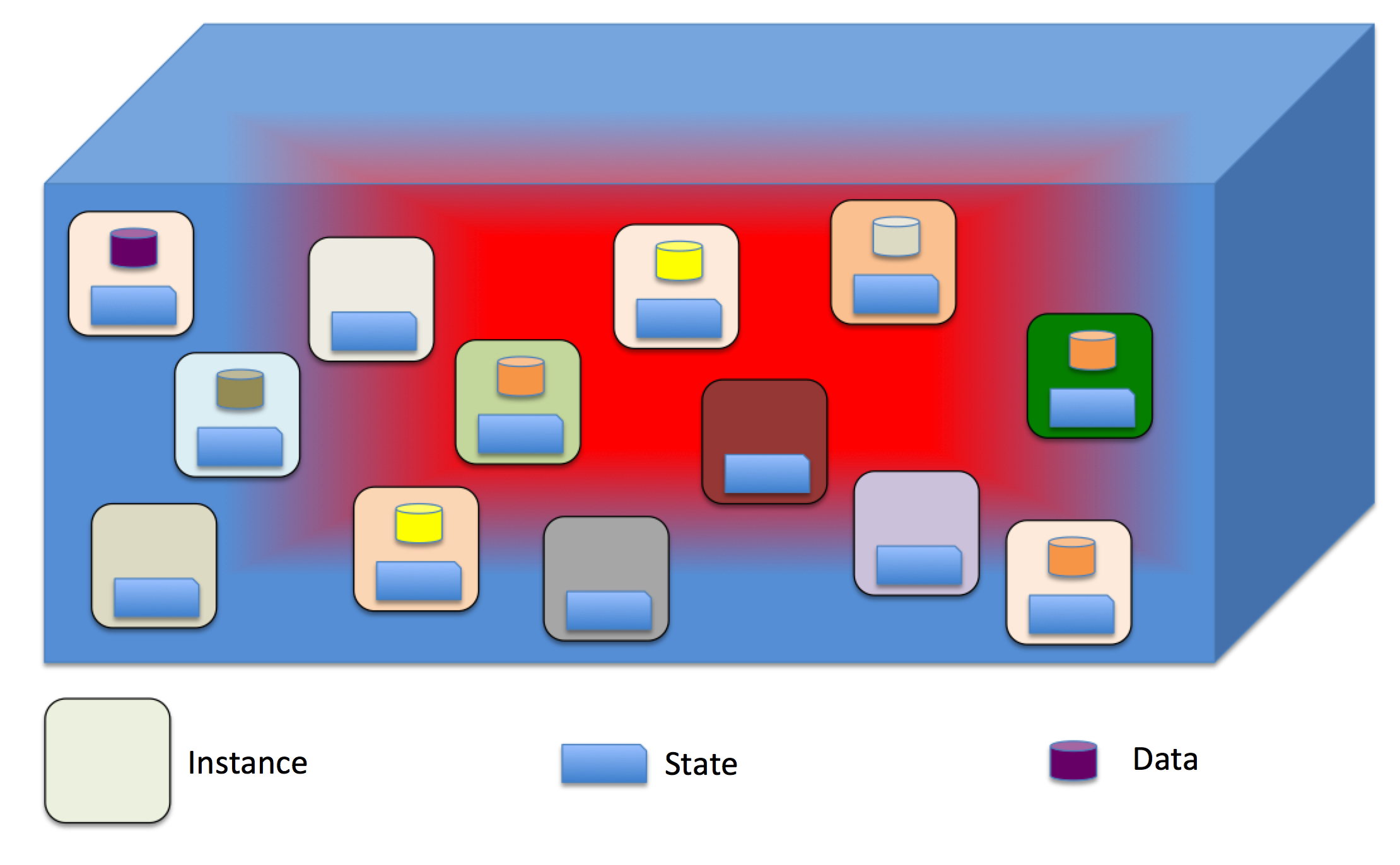
Do you remember the Pets and Cattle story?
I am not going to repeat the usual pitch again. You can read it on that blog post.
Note also how you can't really draw a line between infrastructure capacity and data. Let alone the infrastructure state.
95% of organizations out there (totally made up number which, however, won't fall far from truth in my opinion) are essentially dealing with a bunch of pets that they call by name, all of which have their own unique personality and state (saved locally, this time) and when they die you cry out loudly.
A traditional (i.e. not cloud native) application requires you to install, operate, document, backup, migrate and protect your workloads. Which is the exact opposite of what you'd do with a cloud native application.
In addition to that, there is no particular separation between capacity and state. All of the workloads have state saved on the local disk of each instance.
At best, that state has been backed up in a Word or Excel document. If (or when?) a workload goes belly up, an operator usually re-install it manually from a vanilla template following the Word/Excel "run-book".
Some of those workloads also host user data in the form of databases or files. They require additional care which complicates even further reliability and scalability.
A good litmus test to see if you are running a legacy application or a cloud native application is as follows.
Invite me to your data center at 11AM on a Monday morning to turn off and destroy 20% of the instances you have in production.
If your application deployment self-fixes itself without any work on your part and if there was minimal to no disruption in your end-user experience then you are running a proper cloud native application.
If, on the other hand, you go like "Oh my god what did you do? I have a week of work in front of me now!" all while your phone is ringing like crazy then welcome to the real world along with the remaining 95% of the people.
Remember that automation and self-healing is a key tenet of a cloud native application. I remember meeting with a customer that had an application (compute capacity and data) spread across data centers all architected to survive a complete site failure with no interruption. Unfortunately they told me that, should a failure happen in a data center, it would take them weeks if not months to recreate manually the environment. Not very cloudy if you ask me.
Conclusions
There are many other characteristics of a cloud native applications that I am not covering here. If you are an advanced developer into this game you are probably better off reading The Twelve-Factor App manifesto right away.
In this post I wanted to dumb down a bit these concepts to make them consumable by a larger audience (particularly an audience that doesn't have a cloud or developer background).
In this context, and to summarize, I think that the strong separation between capacity and state is one of those powerful cloud mantras that happen to drive the majority of the advantages (and challenges?) compared to traditional IT.
This separation is a core tenet at any level of a true cloud infrastructure. In this post I touched on the large picture of an entire and complex cloud native application.
However, even if you take the smallest atomic unit of a cloud environment (i.e. an instance) this separation between capacity and state is still core. Look at how Amazon draws the picture of a basic workload comprised of an EC2 instance with a couple of EBS disks (aka persistent disks):
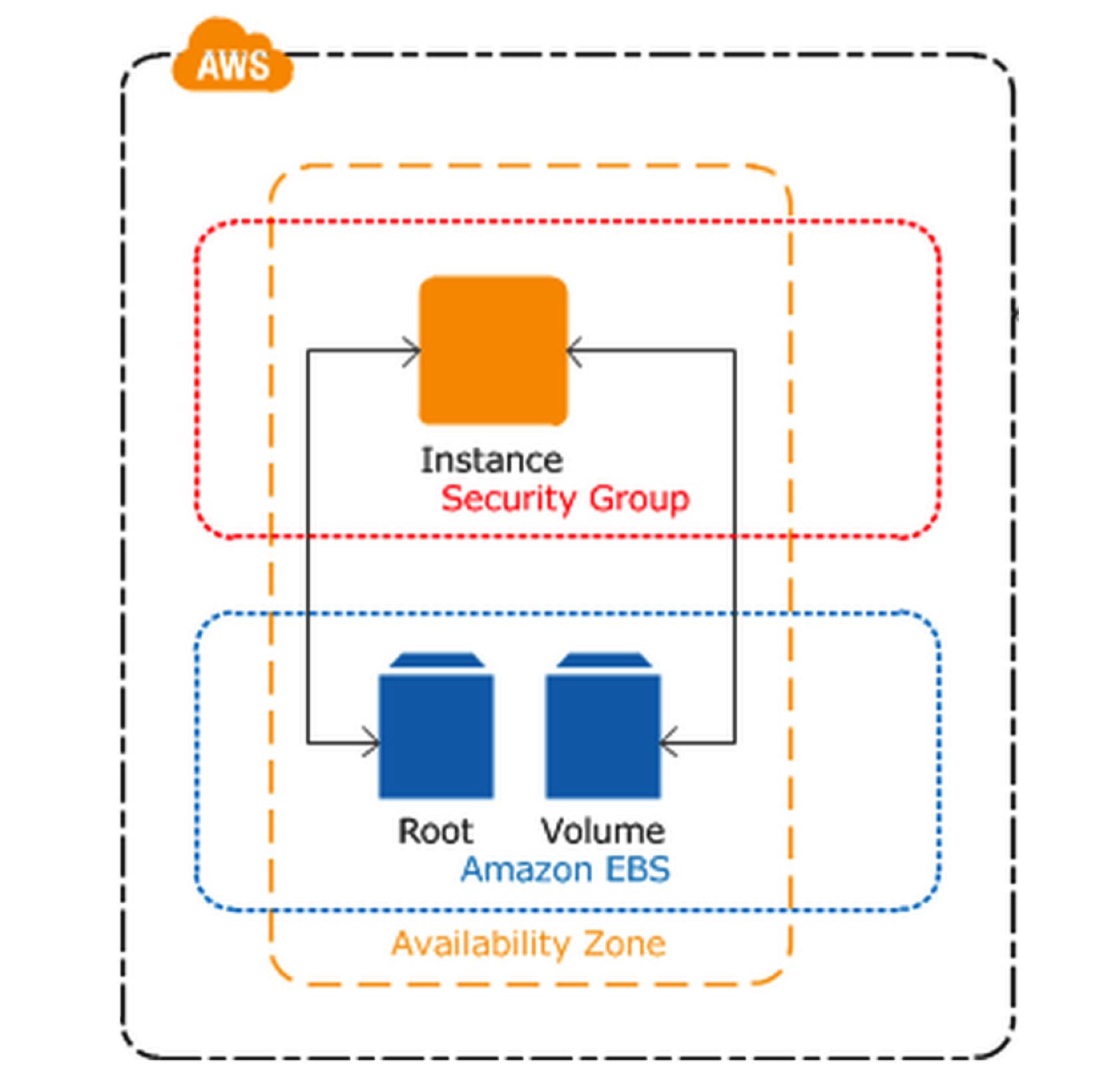
At a much smaller scale it conveys the same message (and graphic) that I have tried to convey in this post. Modularity is core at any level in the cloud.
Digression: ironically, EC2 defaulted to ephemeral disks that so well serve the cloud native application pattern (which does not require state stored at the instance level). However, in order to better serve traditional non cloud native applications, Amazon introduced the notion of an EBS (which is persistency at the single instance level). One could go as far as saying that instances with persistent disks are an anti-cloud pattern. I will leave it at that.
In closing, as you may have guessed, everything you have read in this article regarding cloud native applications leads the way into other buzzwords such as agile, DevOps, continuous development, continues deployment and many more.
In fact, there is no way to do all of that without a properly designed cloud native application.
Massimo.