Compute abstractions on AWS
When I joined AWS last year, I was trying to find a way to explain, in the easiest way possible, all the options the platform offers to our users from a compute perspective. There are of course many ways to peal this onion and I wanted to create a “visual story” that was easy for me to tell. I ended up drafting an animated slide that I have presented at many customers meetings and public events. I have always received positive feedbacks so I thought I would offer to tell the same story on my blog.
I spent a large chunk (if not all) of my career working on the compute domain. I personally define the compute domain as “anything that has CPU and Memory capacity that allows you to run an arbitrary piece of code written in a specific programming language”. It goes without saying that your mileage may vary in how you define it but this is a broad enough definition that should cover a lot of different interpretations.
A key part of my story is around the introduction of different levels of compute abstractions this industry has witnessed in the last 20 years or so.
In the remaining of this blog post I will unfold the story as I usually try to represent it to AWS customers.
Separation of duties
The start of my story is a line. In a cloud environment, this line defines the perimeter between the consumer role and the provider role. In the cloud, there are things that AWS will do and things that the consumer of AWS services will do. The perimeter of these responsibilities varies depending on the services you opt to use. If you want to understand more about this concept I suggest you read the AWS shared responsibility model documentation.
This is the first build-up of my visual story:
The different abstraction levels
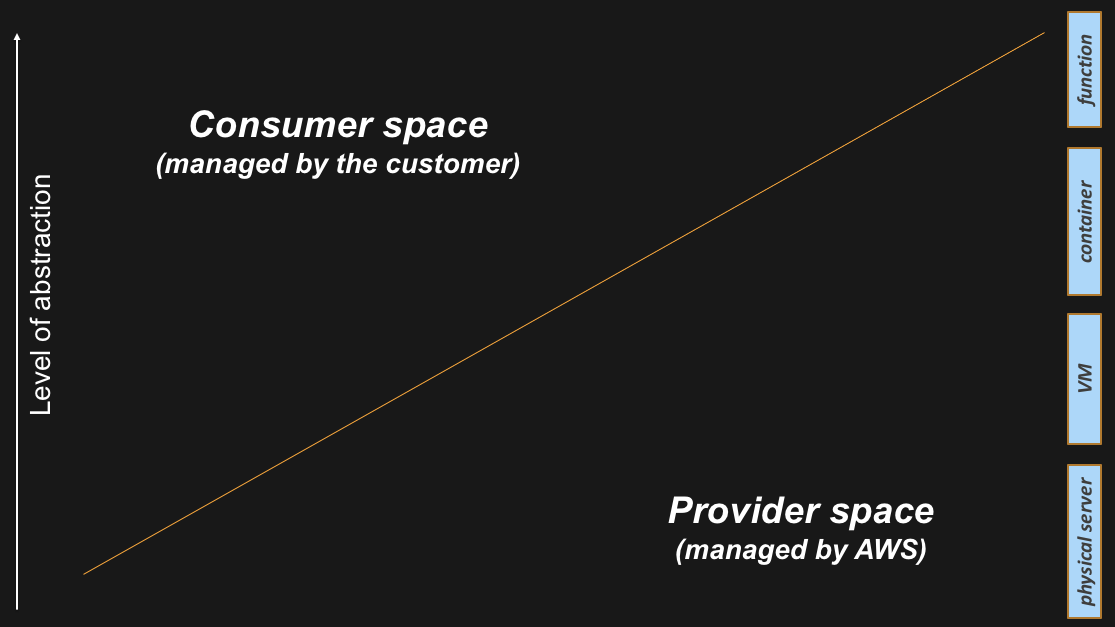
The reason for which the line above is oblique, is because it needs to intercept different compute abstraction levels. If you think about what happened in the last 20 years of IT, we have seen a surge of different compute abstractions that have changed the way people consume CPU and Memory resources. It all started with physical (x86) servers back in the eighties and then we have seen the industry adding a number of abstraction layers over the years (i.e. hypervisors, containers, functions).
As you can depict from the graphic below, the higher you go in the abstraction levels, the more the cloud provider can add value and can offload the consumer from non-strategic activities. A lot of these activities tend to be “undifferentiated heavy lifting”. We define “undifferentiated heavy lifting” as something that an AWS customers have to do but that doesn’t necessarily differentiate them from their competitors (because those activities are table-stakes in that particular industry).
This is how the visual keeps building-up during my story:
In the next few paragraphs I am going to call out some AWS services that intercept this layout. What we found is that supporting millions of customers on the platform requires a certain degree of flexibility in the services we offer because there are many different patterns, use cases and requirements that we need to satisfy. Giving our customers choices is something AWS always strives for.
A couple of final notes before we dig deeper: the way this story (and its visual) builds up through the blog post is aligned to the announcement dates of the various services (with some duly noted exceptions). Also, all the services mentioned in this blog post are all generally available and production-grade. There are no services in preview being disguised as generally available services. For full transparency, the integration among some of them may still be work-in-progress and this will be explicitly called out as we go through them.
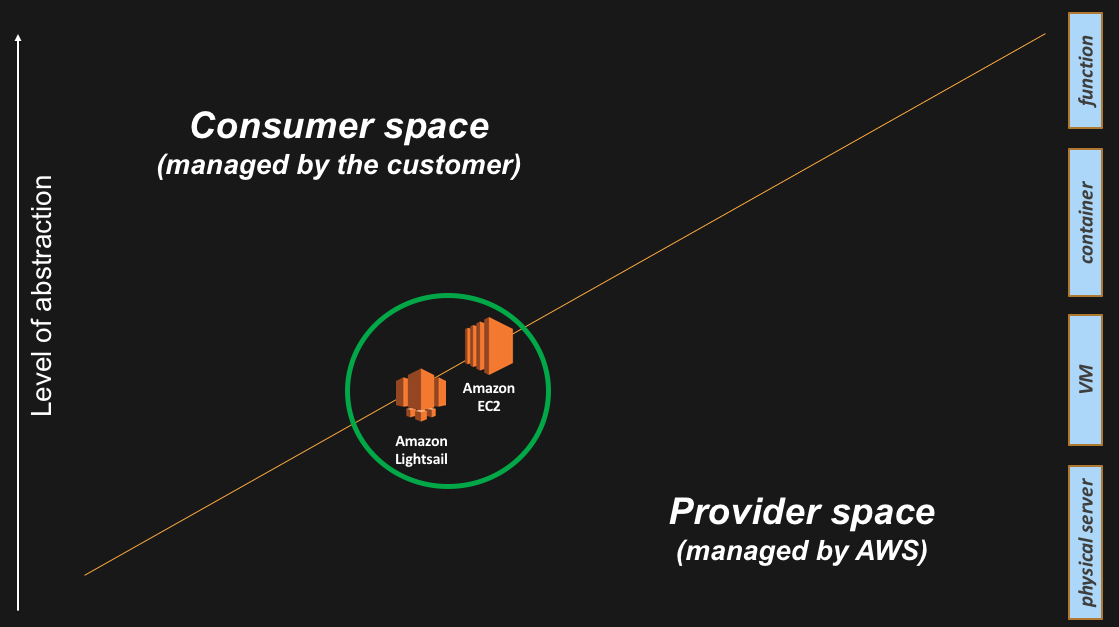
The instance (or virtual machine) abstraction
This is the very first abstraction we introduced on the AWS platform back in 2006. Amazon Elastic Compute Cloud (Amazon EC2) is the service that allows AWS customers to launch instances in the cloud. When customers intercept the platform at this level, they retain responsibility of the guest Operating System and above (middleware, applications etc.) and their life-cycle. Similarly, customers leave to AWS the responsibility for managing the hardware and the hypervisor including their life-cycle.
At the very same level of the stack there is also Amazon Lightsail. Quoting from the FAQ, “Amazon Lightsail is the easiest way to get started with AWS for developers, small businesses, students, and other users who need a simple virtual private server (VPS) solution. Lightsail provides developers compute, storage, and networking capacity and capabilities to deploy and manage websites and web applications in the cloud”.
And this is how these two services appear on the slide:
The container abstraction
With the raise of microservices, a new abstraction took the industry by storm in the last few years: containers. Containers are not a new technology but the raise of Docker a few years ago democratized access to this abstraction. In a nutshell, you can think of a container as a self-contained environment with soft boundaries that includes both your own application as well as the software dependencies to run it. Whereas an instance (or VM) virtualizes a piece of hardware so that you can run dedicated operating systems, a container technology virtualizes an operating system so that you can run separated applications with different (and often incompatible) software dependencies.
And now the tricky part. Modern containers-based solutions are usually implemented in two main logical pieces:
- A containers “control plane” that is responsible for exposing the API and interfaces to define, deploy and life-cycle containers. This is also sometimes referred to as the container orchestration layer.
- A containers “data plane” that is responsible for providing capacity (as in CPU/Memory/Network/Storage) so that those containers can actually run and connect to a network. From a practical perspective this is (typically) a Linux host or (less often) a Windows host where the containers get started and wired to the network.
Arguably, in a specific compute abstraction discussion, the data plane is key but it is as important to understand what’s happening for the control plane piece.
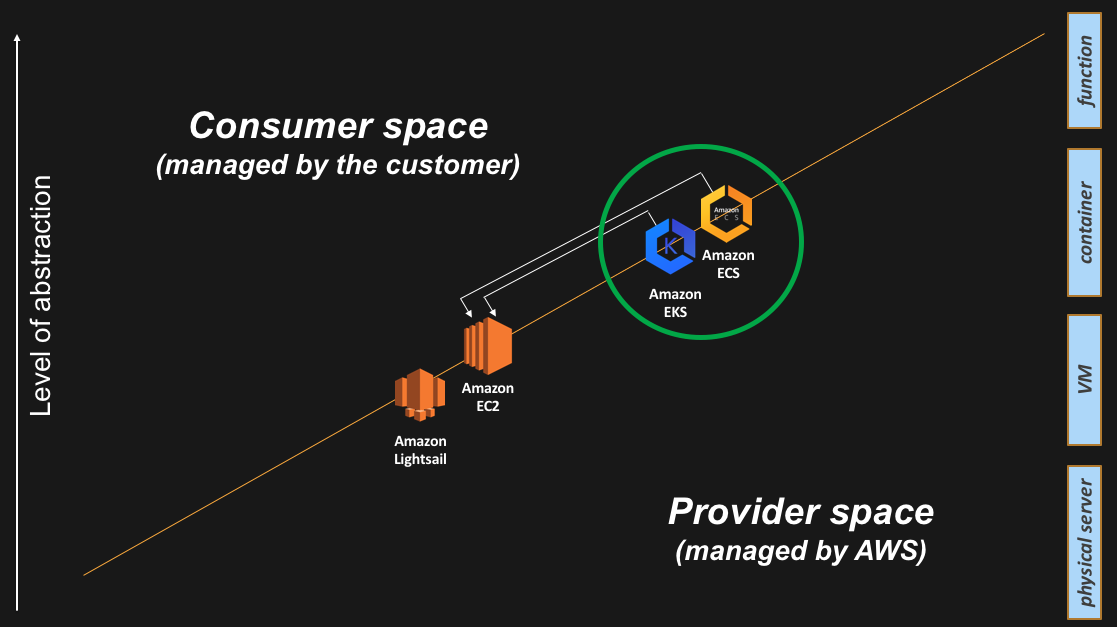
Back in 2014 Amazon launched a production-grade containers control plane called Amazon Elastic Container Service (ECS). Again, quoting from the FAQ, “Amazon Elastic Container Service (ECS) is a highly scalable, high performance container management service that supports Docker ……. Amazon ECS eliminates the need for you to install, operate, and scale your own cluster management infrastructure”.
In 2017 Amazon also announced the intention to release a new service called Amazon Elastic Container Service for Kubernetes (EKS) based on Kubernetes, a successful open source containers control plane technology. Amazon EKS has been made generally available in early June 2018.
Just like for ECS, the aim for this service is to free AWS customers from having to manage a containers control plane. In the past, AWS customers would spin up a number of EC2 instances and deploy/manage their own Kubernetes masters (masters is the name of the Kubernetes hosts running the control plane) on top of an EC2 abstraction. However, we believe many AWS customers will leave to AWS the burden of managing this layer by either consuming ECS or EKS (depending on their use cases). A comparison between ECS and EKS is beyond the scope of this blog post.
You may have noticed that everything we discussed so far is about the container control plane. How about the containers data plane? This is typically a fleet of EC2 instances managed by the customer. In this particular setup, the containers control plane is managed by AWS while the containers data plane is managed by the customer. One could argue that, with ECS and EKS, we have raised the abstraction level for the control plane but we have not yet really raised the abstraction level for the data plane as the data plane is still comprised of regular EC2 instances that the customer has responsibility for.
There is more on that later on but, for now, this is how the containers control plane and the containers data plane services appear on the slide I use to tell my story:
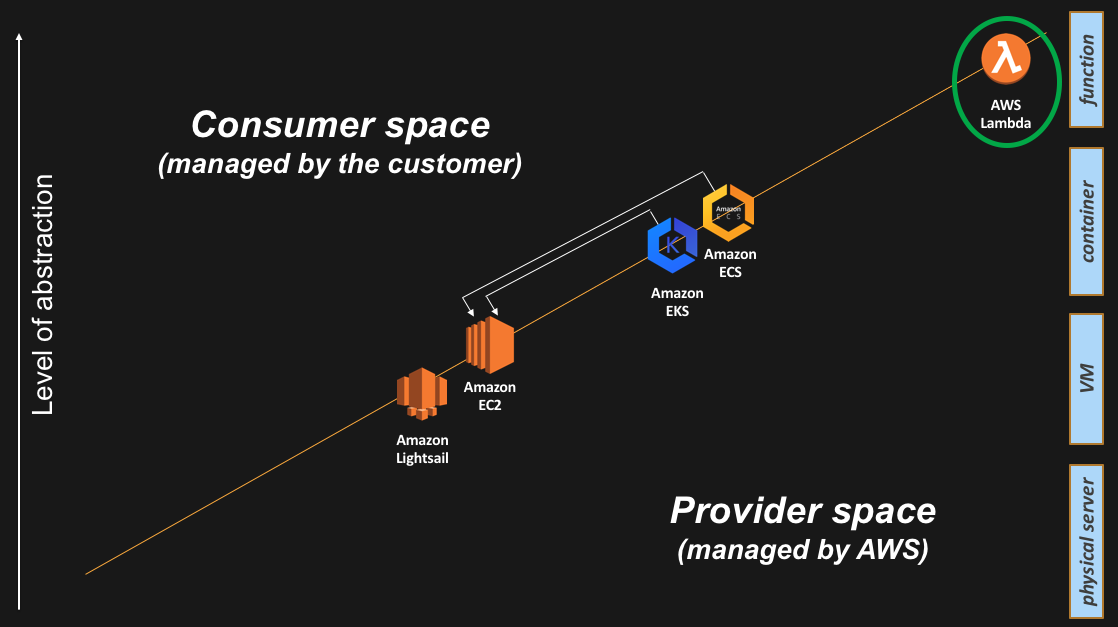
The function abstraction
At re:Invent 2014, AWS also introduced another abstraction layer: AWS Lambda. Lambda is an execution environment that allows an AWS customer to run a single function on the AWS platform. So instead of having to manage and run a full-blown OS instance (to run your code), or instead of having to track all software dependencies in a user-built container (to run your code), Lambda allows you to upload your code and let AWS figure out how to run it (at scale). Again, from the FAQ: “AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume – there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app”.
What makes Lambda so special is its event driven model. As you can read from the FAQ, not only can you invoke Lambda directly (e.g. via the Amazon API Gateway) but you can trigger a Lambda function upon an event in another AWS service (e.g. an upload to Amazon S3 or a change in an Amazon DynamoDB table).
In the context of this blog post, the key point about Lambda is that you don’t have to manage the infrastructure underneath the function you are running. No need to track the status of the physical hosts, no need to track the capacity of the fleet, no need to patch the OS where the function will be running. In a nutshell, no need to spend time and money on the undifferentiated heavy lifting.
And this is how the Lambda service appears on the slide:
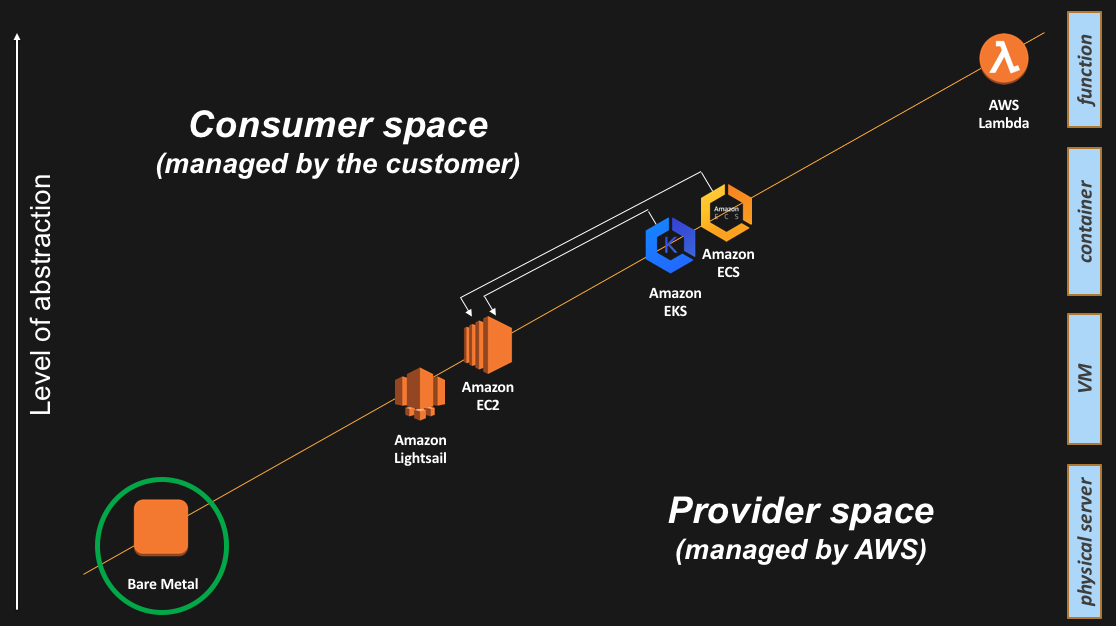
The bare metal abstraction
Also known as the “no abstraction”.
As recently as re:Invent 2017, we announced (the preview of) the Amazon EC2 bare metal instances. We made this service generally available to the public in May 2018.
As alluded to, at the beginning of this blog post, this announcement is part of the Amazon’s strategy to provide choice to our customers. In this case we are giving customers direct access to hardware. To quote from Jeff’s post “…. [AWS customers] wanted access to the physical resources for applications that take advantage of low-level hardware features such as performance counters and Intel®VT that are not always available or fully supported in virtualized environments, and also for applications intended to run directly on the hardware or licensed and supported for use in non-virtualized environments”.
This is how the bare metal Amazon EC2 i3.metal instance appears on the slide:
As a side note, and also as alluded by Jeff in his blog post, i3.metal is the foundational EC2 instance type on top of which VMware created their own “VMware Cloud on AWS” service. We are now offering the ability to any AWS user to provision bare metal instances. This doesn’t necessarily mean you can load your hypervisor of choice out of the box but you can certainly do things you wouldn’t be able to do with a traditional EC2 instance (note: this was just a Saturday afternoon hack).
More seriously, a question I get often asked is whether users could install ESXi on i3.metal on their own. Today this cannot be done and I’d be interested in hearing your use case for this as opposed to using the “VMware Cloud on AWS” service.
The full container abstraction (for lack of a better term)
Now that we covered all the abstractions, it is now time to go back to the whiteboard slide and see if there are other further optimization we can provide for AWS customers. When we discussed above the container abstraction, we called out that, while there are two different fully managed containers control planes (ECS and EKS), there wasn’t a managed option for the data plane (i.e. customers can only deploy their containers on top of customers owned EC2 instances).
Some customers were (and still are) happy about being in full control of said instances.
Others have been very vocal that they wanted to get out of the (undifferentiated heavy-lifting) business of managing the life cycle of that piece of infrastructure.
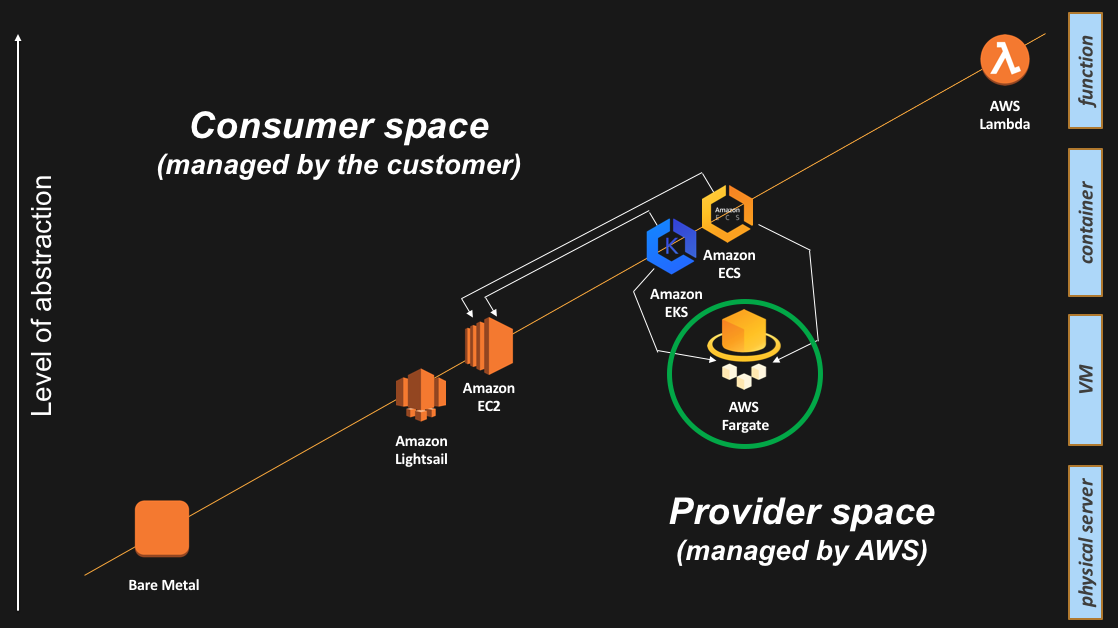
Enter AWS Fargate. AWS Fargate is a production-grade service that provides compute capacity to AWS containers control planes. To quote from the Fargate service home page: “With AWS Fargate, you no longer have to provision, configure, and scale clusters of virtual machines to run containers. This removes the need to choose server types, decide when to scale your clusters, or optimize cluster packing. AWS Fargate removes the need for you to interact with or think about servers or clusters. Fargate lets you focus on designing and building your applications instead of managing the infrastructure that runs them”.
Practically speaking, Fargate is making the containers data plane fall into the “Provider space” responsibility. This means the compute unit exposed to the user is the container abstraction, while AWS will manage transparently the data plane abstractions underneath.
This is how the Fargate service appears on the slide:
As alluded to in the slide above, now ECS has two so called “launch types”: one called “EC2” (where your tasks get deployed on a customer managed fleet of EC2 instances), and the other one called “Fargate” (where your tasks get deployed on an AWS managed fleet of EC2 instances).
For EKS the strategy is very similar albeit, to quote again from the Fargate service home page, “AWS Fargate support for Amazon EKS will be available in 2018”. For those of you interested in some of the exploration being done to make this happen, this is a good read.
Conclusions
In this blog post we covered the spectrum of abstraction levels available on the AWS platform and how AWS customers can intercept them depending on their use cases and where they sit on their cloud maturity journey. Customers with a “lift & shift” approach may be more akin to consume services on the left-hand side of the slide whereas customers with a more mature cloud native approach may be more interested in consuming services on the right-hand side of the slide.
In general, customers tend to use higher level services to get out of the business of managing non-differentiating activities. I was for example recently talking to a customer interested in using Fargate. The trigger there was the fact that Fargate is ISO, PCI, SOC and HIPAA compliant and this was a huge time and money saver for them (that is, it’s easier to point to an AWS document during an audit than having to architect and document for compliance the configuration of a DIY containers data plane).
As a recap, this is the final slide I tend to show with all the abstractions available:
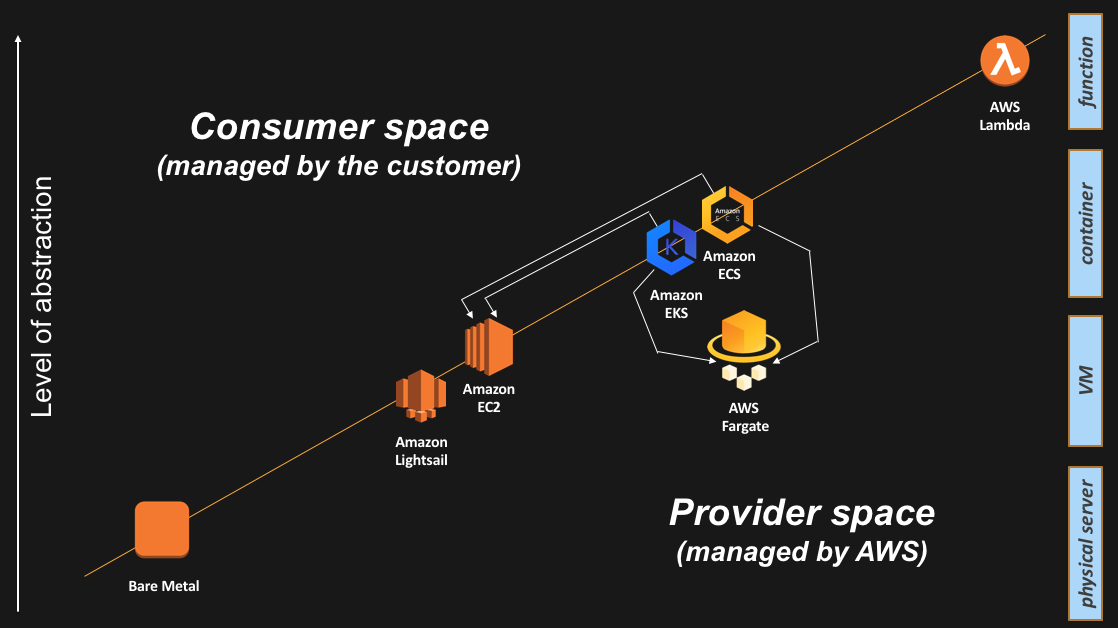
I hope you found it useful. Any feedback is obviously greatly appreciated.
Massimo.