Serverlessconf 2016 – New York City: a personal report
Warning: social media experiment ahead.
Two weeks ago I attended Serverlessconf in NYC. I’d like to thank the organization (Stan and the acloud.guru crew) for the tremendous job (and for inviting me to attend).
I originally wanted to write a (proper) blog post but then I figured that:
- I have already written much of what I wanted to say in an “internal report” that I shared with my team
- I don’t really have time these days to write a (proper) blog post
- The “internal report” doesn’t really have much of “internal” / confidential stuff anyway (just a few comments).
So why not sharing a copy/paste of that report?
I did indeed remove (see
Below you will find some high level conclusions (first) and then some personal notes on a few sessions.
This is my way of giving back (a little bit) to the community I serve. I hope you will find it (somewhat) useful.
What you will read below this line is the beginning of my original report (and informal notes).
__________________________
Executive summary and general comments
Event website: http://serverlessconf.io/
Industry state of the art (according to what I see)
This event left me with the impression (or the confirmation) that there are two paces and speeds at which people are moving.
There is the so called “legacy” pace. This is often characterized by the notion of VMs and virtualization. This market is typically on-prem, owned by VMware and where the majority of workloads (as of today) are running. Very steady.
The second “industry block” is the “new stuff” and this is a truly moving target. #Serverless is yet another model that we are seeing emerging in the last few years. We have moved from Cloud (i.e. IaaS) to opinionated PaaS, to un-opinionated PaaS, to DIY Containers, to CaaS (Containers as a Service) to now #Serverless. There is no way this is going to be the end of it as it’s a frenetic moving target and in every iteration more and more people will be left behind.
This time around was all about the DevOps people being “industry dinosaurs”. So if you are a DevOps persona, know you are legacy already. You could feel this first hand on Twitter where DevOps experts where trying to minimize the impact (and viability) of Serverless while the Serverless proponents where all:
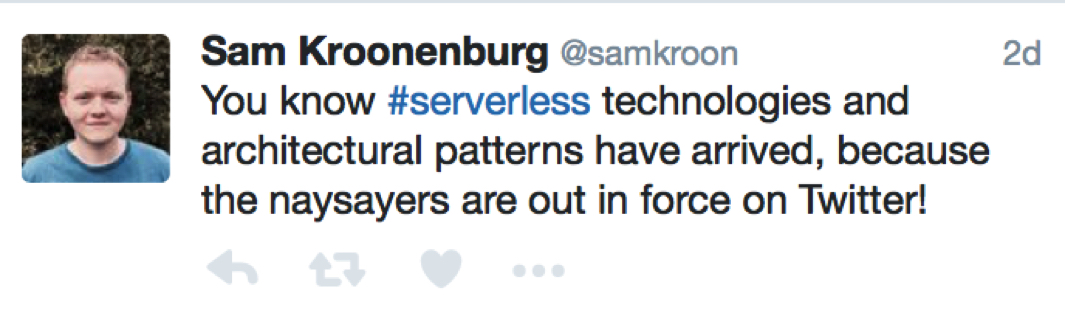
Where / when this will stop is hard to predict at this point.
What’s Serverless anyway?
The debate re what #Serverless is still on and it ranges from “oh well but we were doing these stuff 5 years ago but we called it something else” all the way to “this is futuristic stuff”.
I think it’s fair to look at AWS to define this market (as they have basically been the first to talk about these stuff) and so I’d suggest you read the “Keynote Day 1 (AWS)” section below carefully.
IMHO I see Serverless as some sort of “PaaS on steroids” (or should I say “PaaS on a diet”?)
I see Serverless being different compared to PaaS in two (major) areas:
- The unit of deployment. In PaaS you deploy an “application” (which could be as small as you want) whereas in Serverless you deploy a “function” (of an application) which is small by definition.
- The consumption pattern. PaaS is often pitched in the context of an application with an interface (called either by the user or another application). While this is one of the legit patterns for Serverless as well, the other pattern that is specific to Serverless is that the function is being triggered by external data-driven events (e.g. “run this function when this happens in the data”). This is the pattern I was focusing describing when I made a parallel between Lambda and Stored Procedures.
An interesting description of one of the Serverless vendors when I challenged him with “how isn’t this PaaS anyway?”:
“****It is sort-of like a PaaS. I usually avoid the term PaaS because (1) people might associate it with a traditional PaaS, where apps have a three-tier architecture with a DB offering already chosen for you and (2) PaaS usually includes more services around the execution bit.
Serverless patterns
As suggested in the section above there are two emerging and re-occurring patterns that industry pundits are seeing WRT Serverless:
- Write a function (or a set of those) and expose them via an API (in the AWS world this would be AWS Lambda + AWS API Gateway) that a user / program can interact with.
- Write a function that is triggered by a data-driven event.
“Composable applications” (for lack of a better term)
This is not strictly related to Serverless (as described by industry pundits) but it’s interesting to see how much these new applications are being developed on top of Internet delivered laser focused services that provide application components that wouldn’t differentiate software products. Examples of these are Auth0 and Firebase (they were front and center during the entire conference, to the point that you could feel a good chunk of the audience would favorite them Vs equivalent AWS services such as Cognito and DynamoDB).
Basically your entire application consists for 80% of a mix/collage of third party web services that deliver specific value in a specific domain (e.g. authentication, data persistency, etc) and 20% of the “business logic” which defines what your application does. The key point is that only this 20% will differentiate you so that you can outsource commodity / generic services that are undifferentiating.
This pattern was very clearly described during the “10X Product Development” breakout session. See below. IMO the best session of the event.
This doesn’t have much to do with the concept of Serverless (as framed during the event) but nonetheless it was front and center for the whole 3 days (including the workshop – see below for more info on the workshop).
DevOps Vs NoOps
This has been debated throughout the conference. While the average consensus was that “with Serverless the need for Ops disappears” was strong, there were a few sessions during the event that underlined the importance of Ops (and DevOps).
It wasn’t however clear what the world of Ops would be in the Serverless world (as painted). The level of abstraction is so high in this model that other than having developers writing code/functions there is little left to be done. Surely there are challenges (e.g. designing proper application architectures) but typically all of these challenges are Dev challenges and not so much Ops challenges.
Monetization strategies
There were no such discussions during the conference. I will note though that all the players in this arena seems to be providing web services (where a tiered monetization strategy seem to be a viable option and somewhat accepted as a valid go to market). IMO the mood around software (in these contexts) is still very much 1) it must be free and 2) it must be open source.
Kelsey Hightower summarized it pretty well:
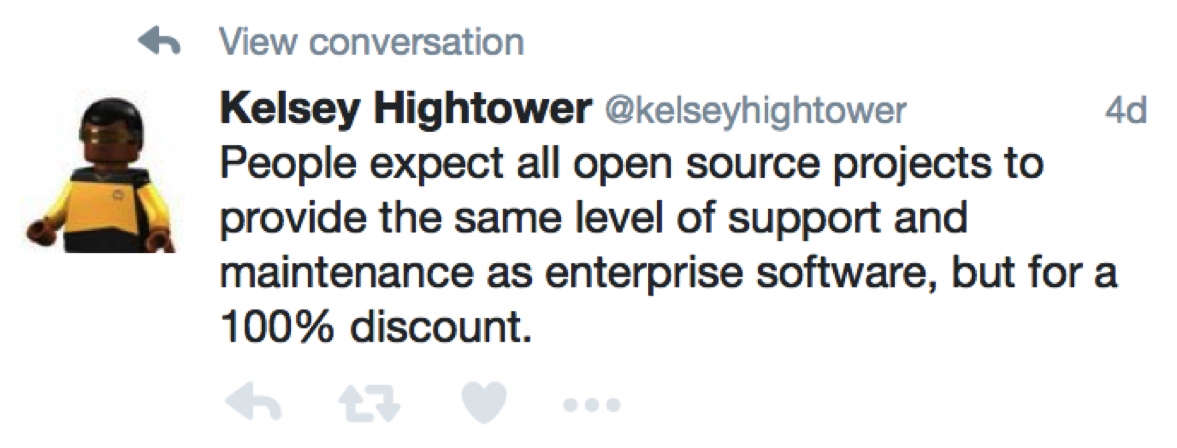
On the topic of (services) monetization, it is important to take note of the AWS march towards self-destroying and cannibalizing their lucrative revenue streams (arguably a strategy that is working very well for them).
Similarly to how they cannibalized (part of) S3 when they introduced Glacier, they are now cannibalizing the very lucrative EC2 product for a much cheaper compute alternative. There is no doubt that they are doing this for long term longevity and a stronger “lock-in” with their customers (it will be easier to leave AWS if you use EC2 than if you use Lambda). Having that said there are few vendors around that are taking better long term decision trading off short term revenue streams. Kudos to AWS in this sense.
Implications for Docker
This was another interesting aspect of the conference. Clearly Docker was being marginalized to a mere packaging format that everyone (except AWS?) is using in the backend as a mechanism to run the function code BUT it’s never ever exposed to the end-user. This is great news for Docker (the OSS project) but it’s disastrous news for Docker (Inc. the company).

I myself added to the cynic approach of the conference and I did shoot a couple of “bombs” (one of which was picked up by not less than Salomon in person):
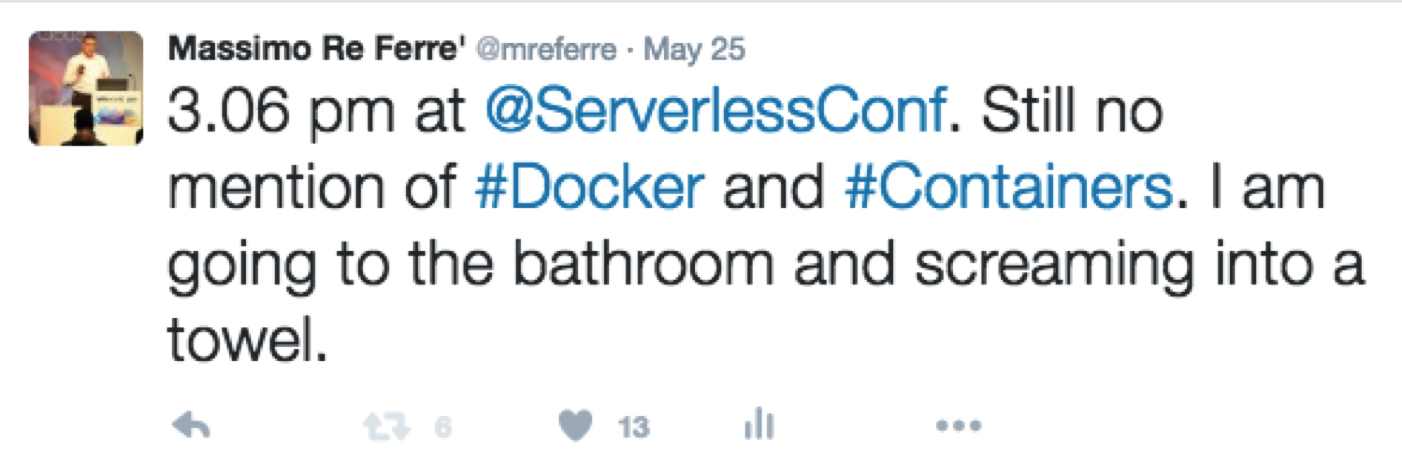
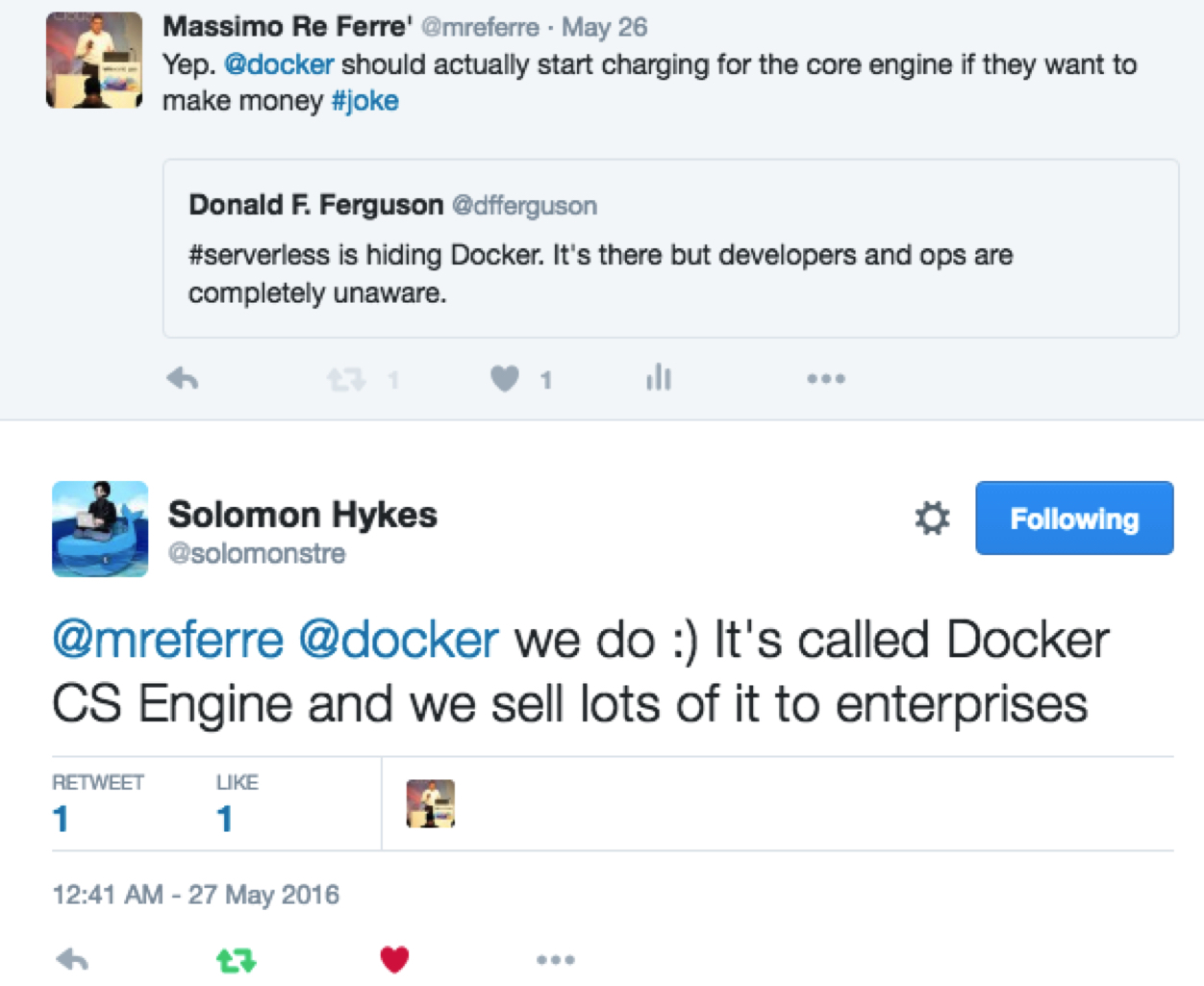
Containers are more and more marginalized to being a run-time detail.
Workshop
Serverlessconf was a full 2-day event fronted by a hands-on workshop (the day before).
I attended the workshop and I found it quite interesting. This was an instructor led lab whose documentation is still available on Github: (https://github.com/ACloudGuru/serverless-workshop).
[Note: the repository has been taken down after the workshop]
I do suggest that, anyone interested in the topic, goes through this hands-on workshop. Physical presence was a nice-to-have but not a strict requirement. Documentation is well organized and DYI is certainly possible.
The content is based on Lambda but it’s a good way to experiment first hand with some of the #serverless logic and patterns. Eveything suggested in the workshop could probably easily be achieved / applied to other #serverless implementations such as Azure Functions and Google Cloud Functions.
The workshop also includes some interesting “composability” patterns such as using external web services to off-load and simplify your own code (some services that have been leveraged include Auth0 and Firebase).
Other than the content of the workshop itself, it was interesting to see some of the real-life challenges associated to consuming and compose third party services. For example the workshop was based on some Firebase consumption models associated to default accounts behaviours that literally changed overnight (before the workshop) so people creating new Firebase accounts for the workshop would experience a drift of behaviour from the documentation.
This underlines the challenges for these cloud services to honour backward compatibility contracts as well the challenges for consumers to deal with the fact that
All in all it was an interesting workshop.
Keynote Day 1 (AWS)
Tim Wagner (AWS GM for Lambda and API Gateway) starts by physically smashing a few (fake) servers on stage. That sets the tone.
Serverless allows “democratizing access to scale”. Not everyone is an expert in distributed systems hence Serverless represents the OS of the giant computer that the cloud represents.
DevOps is described as “the punch card of 2016”. The speaker was alluding to the ecosystem of skills required to do DevOps (and punch cards in the early days) Vs the transparent experience of #Serverless. There surely was also the intent of downplaying/denigrating DevOps as people pushing Serverless are trying to claim DevOps is not needed / irrelevant.
The speaker hints: “isn’t this like PaaS? No: PaaS is too curated, too intrusive but more than anything… it uses the wrong unit of scale (monolithic applications).”
I am wondering what Pivotal will have to say re this.
A hint from Andrew Clay Shafer:
Speaker makes the point that “the less in serverless is really server software, not server hardware".
The Serverless manifesto is shown.

How do you run a 1-hour task?
Old school: 1 x 60 minutes task
New school: 60 x 1 minute tasks
He stresses on the “you don’t pay for idle” concept leveraging on the fact that it’s known that majority of compute capacity (in cloud or on-prem) is often idle (and you pay for that). This is indeed a known problem for wrongly sized EC2 instances that sit idle most of the time.
It is amazing to see how they have 0 problems cannibalizing EC2 (arguably what makes most of their revenue right now).
Lambda uses containers to run functions. They figured the challenging of scheduling, packaging (fast) user’s code etc.
In an effort to push Serverless and get more vendors on the same page, the speaker announces Flourish which is an effort to create an industry wide way to describe the app model and a way to group those different functions into a real application.
He points out this is not to go back to the “monolith” (single functions can still be updated independently etc).
More on Flourish here: http://thenewstack.io/amazon-debuts-flourish-runtime-application-model-serverless-computing/
The speaker makes four predictions:
- All data will stream (driven by speed requirements)
- Natural language interfaces will permeate man-machine interaction
- Serverless is going to confer economic advantages for the organizations that are embracing it (thus allowing those organizations to be differentiated)
- Code stays in the cloud (Vs on the laptop and moved to the cloud eventually)
10X Product Development
This talk was also super interesting.
The narrative was about “how do you make your devs 10x more productive”.
He shows https://www.commercialsearch.com/ and then it shows the architecture: basically it’s a composition of a series of on-line services (firebase, algolia, auth0, cloudinary, etc).
It took 4 months, 2 developers, 13000 lines of code to build it.
95% of developer efficiency (developer efficiency is "how much time you worked on “business” code" Vs. "how much time you worked on non differentiating code")
Second project: https://www.propertytourpro.com/
Similar architecture. They use the same online services as before plus things like DocRaptor, Auth0 Webtasks.
Interesting comment: ironically, now the biggest chunk of code you are writing is front-end code (not back-end code, because MOST of the backend stuff are being delegated to external on-line services). There is going to be some glue that needs to happen between these services (and here you can use Serverless functions aka Lambda or even implement some of the logic in the front-end code if need be).
The speaker then talks about why they do not use AWS. AWS is about back-end processing, which they have largely outsourced (note: they outsourced to laser focused startups solving a single domain problem Vs to the counterpart AWS services).
It’s amazing how in this event startups like Auth0 and Firebase were seen as “the new cool thing” Vs there were seeds of AWS being started to be seen as the 800 pounds gorilla that doesn’t pay attention to users etc.
They need Auth0 etc more than they need “a place to execute code” (i.e. Lambda). And according to the speaker, Auth0 Webtasks are way more than enough if they need a Lambda-like solution.
AWS Serverless is complicated: to achieve a similar online service experience you need to collate 3 or 4 or 5 different AWS services.
The “Serverless Framework” (http://cloudacademy.com/blog/serverless-framework-aws-lambda-api-gateway-python/) is, in the opinion of the speaker, testament of how limited AWS Lambda is (if you need external libraries for a good experience than it means Lambda is too limited).
Firebase
They started as a no SQL database. Then they added Authentication and “Hosting” capabilities.
It recently become a Suite of 50-ish features/services.
Firebase is positioned by Google as a “Backend as a Service” (between App Engine [PaaS] and Google Apps [SaaS]).
Now they show a demo that involves uploading a picture to Object Storage via Firebase and Firebase then runs a check against the Cloud Vision APIs and they render the picture on the website with the results from the Vision APIs.
(this was similar to the demo AWS did for Lambda at re-invent 2 years ago where they took a picture of the audience, upload it to S3 and a Lamnda function would create a thumbnail of that picture that landed on another S3 bucket).
“This is how you resize an image in a bucket” is becoming the new “This is how you can run WordPress in a Docker container”.
SERVERLESSNESS, NOOPS AND THE TOOTH FAIRY
This talk was delivered by Charity Majors, one of the early employees of Parse (acquired and later shut down by Facebook).
Major was one of the few people talking about the importance of Ops. Her talk was also centered around the process people should go through to assess what services you could outsource and what services you should keep control of (surely the Parse experience taught her one thing or two).
Charity is starting to collect her thoughts in some blog posts if you are interested:
https://charity.wtf/2016/05/31/wtf-is-operations-serverless/
https://charity.wtf/2016/05/31/operational-best-practices-serverless/