The Cloud and the Sunset of the GHz-based CPU Metric
We have known this for years but it's only when you get a slap on your face that you understand what's going on for real: the GHz metric is useless these days. I was experimenting with vCloud Director the other day and I was checking out from the catalog my Turnkey Linux Core virtual machine (I use that because it's small and I can check it in and out from the catalog very quickly - it's also a very nice distro!). This instance was launched in a cloud PoC I have recently started working on for a big SP and I noted it took quite some to boot, at least more than what it usually takes which is around 40-60 seconds. Similarly the user experience once booted was not optimal compared to what I am used to. While I haven't done any serious analysis of the problem, I am going to take a stab at what I believe it was happening behind the scene.
A little background first. This service provider opted to use some quite old IBM x86 servers to run this PoC. Since the PoC, for the moment, is focusing on functionalities - rather than performance and scaling - we thought it was ok to use these servers. For the records they are IBM System x 3850 (8863-Z1S). These are single-core 3.66GHz servers with 4 sockets. Admittedly, pretty old kits. This is how they show up in vCenter:
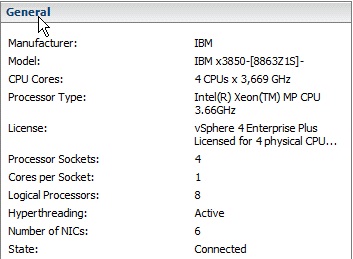
This is technology from 2004/2005 if memory serves me well. Consider that, while they
Back to the performance issue I was describing now. You should know that when vCloud Director assigns to an Organization a vDC using the PAYG model, it sets a certain "value" for the vCPU. You can think - roughly and conceptually - about this value as something similar to the AWS ECU (Elastic Compute Unit). This is a good thing to do because it provides a mechanism for the cloud administrator to normalize the capacity of a vCPU. It also allows the provider to create a mechanism to cap the workload (as you probably don't want a consumer to stuck an entire core). For the records vCD can also reserve part of that "speed" for the VM so that it can guarantee that these reserved resources are always available. The picture below shows the screen where you set this value when creating an Organization vDC (these are all the default values).
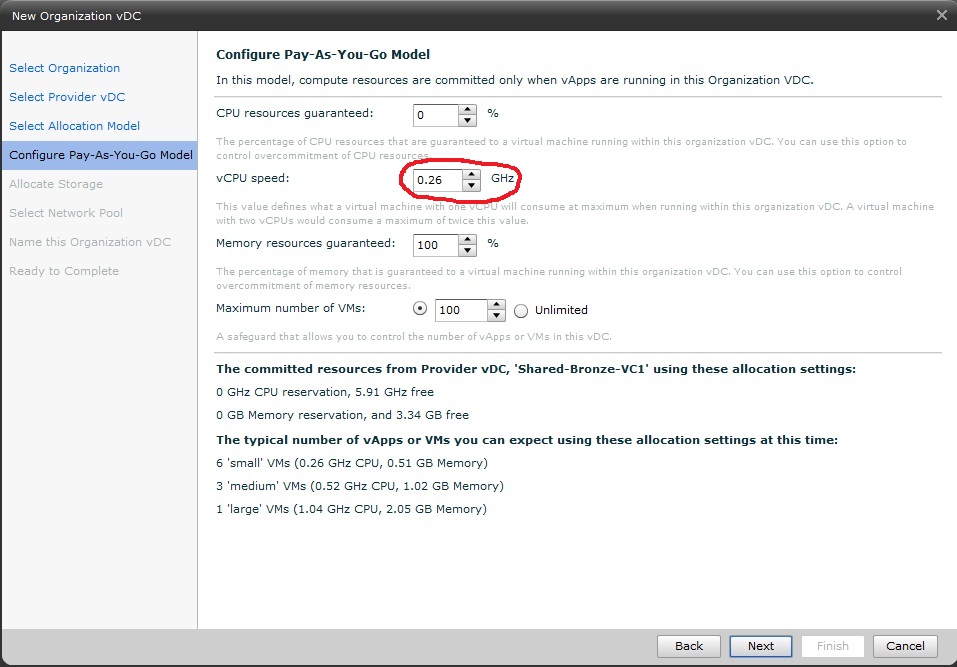
Note that the default "speed" value for a vCPU in the PAYG model is 0,26GHz (or 260MHz if you will). This means that, when you deploy a VM in this vDC, vCloud Director configures a limit on the vCPU with that value. I am not sure how Amazon enforces the ECU on their infrastructure (or if they enforce it at all) but this is how vCD and vSphere cooperatively do it:
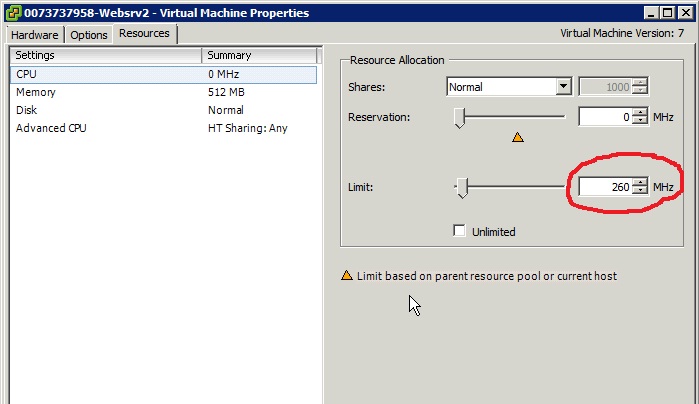
To the point now. Everybody knows that x86 boxes scaled CPU capacity exponentially in the last few years. Today, a last generation 4-socket server can have a ridiculous amount of cores (up to 80). That's one dimension of the scalability Intel and AMD have achieved. Another dimension is that the core itself has gone through some very profound technology enhancements and got better and better. Let's try to do some math and find out how much better.
To do this I am not going to do a scientific comparison (I wish I had the time). I am going to quickly leverage a couple of benchmarks to find out the different efficiency between the old and the new cores. I am going to use the TPC-C benchmark - which is a simulated OLTP workload - that may not be always relevant but it's known to be CPU bound - although it does require a couple of hundreds thousands of disk spindles to not be bottleneck on the disk subsystem (which means: don't bother trying it at home). Long story short I took a TPC-C benchmark of an IBM server equipped with the same CPUs that we are using in this cloud PoC and I compared it to a benchmark of one of the IBM servers that supports the latest generation of Intel Xeon processors:
Old Benchmark: 150,000 tpmC (4 sockets, 4 cores, 3.66Ghz)
New Benchmark: 2,300,000 tpmC (4 sockets, 32 cores, 2.26Ghz)
We are not interested in the metric (tpmC = transactions per minute C-workload) in absolute terms because we are using this metric just to compare the CPUs. So for the two systems the math would (more or less) look like this:
- Old server: 150K transactions on 4 cores makes roughly 38000K transactions per 3.66Ghz core which means roughly 10 transactions per MHz
- New server: 2.3M transactions on a 32 cores make 72K transactions per 2.26Ghz core which means roughly 32 transactions per MHz
I didn't have time to triangulate with more benchmarks so will stick with this one and we will claim that a single MHz of a new core is worth about three MHz of the old core we are using in the PoC.
Now I guess you have an idea why talking about MHz is meaningless at this point. I guess you also see why assigning "260MHz" to the CPU tells half of the story (the other half being.. ok but of which core?). Yet there still are a lot of people out there that think that a 3Ghz processor is faster than a 2.26GHz processors. I believe you also have an idea now why Amazon and VMware introduced these different metrics: it's basically a way for the provider of resources to normalize the actual capacity of the CPUs underneath to overcome the variance we have seen above). My initial performance problem was in fact solved raising the value of the "vCPU speed" in vCloud Director: I assigned more GHz to the vCPU to off-set the poor quality of the core.
Let me change gear here now. What we have discussed so far is fine when you are dealing with VMs since you can easily use a technique to buffer this variance (the "vCPU speed" or the Amazon "ECU"). However this becomes a little bit trickier when you start dealing with virtual data center capacity. How do you normalize that? The easiest (and more user-friendly) way to do this is to expose directly the capacity expressed in terms of GHz, which is what vCloud Director does today when configuring Organization vDCs in reservation or allocation mode.
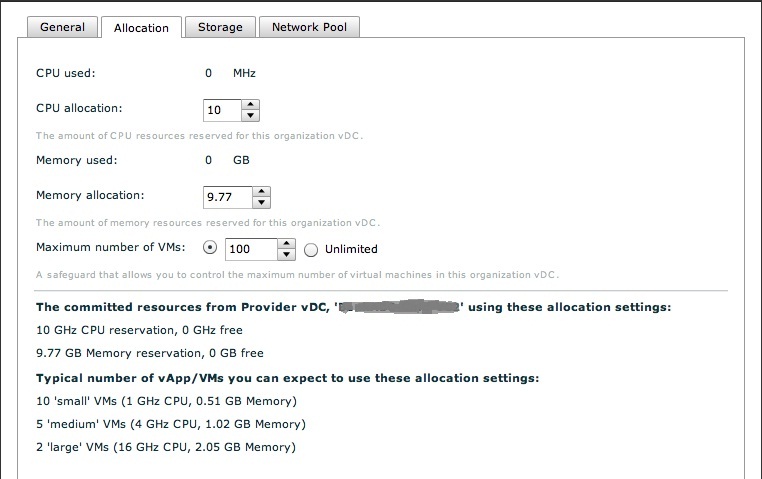
So what do we do? We all agree that 10GHz is no longer meaningful but what is the other option? You may argue that in a cloud environment you shouldn't bother about the low level hardware implementation details because the whole purpose of cloud is to hide them right? On the other hand we are talking about IaaS type of cloud here so a much higher level metric such as "application response time" wouldn't be applicable as vCloud Director doesn't really manage the middleware and application part of the stack; that would be out of its control.
GHz may sound like the right thing to expose when you are providing virtual hardware capacity in an IaaS cloud but yet the metric would need to be consistent across different providers (and we have seen this may not be the case if different providers are using different hardware technologies). An option would be to try to normalize this value similarly to how the CPU in the VM gets normalized. Sure but how? With which metric? In the VM based model you can expose a very well known metric / object: the vCPU). In that case you can pass onto the consumer the key to decrypt the amount of compute capacity of that object similarly to how Amazon does it with ECU : "One EC2 Compute Unit provides the equivalent CPU capacity of a 1.0-1.2 GHz 2007 Opteron or 2007 Xeon processor. This is also the equivalent to an early-2006 1.7 GHz Xeon processor". The keyword here being "equivalent". This means you can use any CPU technology you want, someone will tweak a parameter so that your performance experience will always be the same. Which is hat I have done above to fix my performance problem in the PoC for example.
The vCloud Director challenge is slightly different than the Amazon challenge though in the sense that vCD is a technology that enables service providers to stand up cloud backbones quickly and efficiently... whereas Amazon is indeed a Service Provider. So coordination and standardization for them isn't an issue (as a matter of fact ECU doesn't really have any industry-wide meaning outside of the context of the AWS platform).
Similarly to how the industry is looking for standard APIs to consume cloud resources across different providers, I believe there is a need to standardize the metrics that describe the capacity that those resources can deliver. Can this metric be an industry standard benchmark like TPC-C (for example)? Or should it be more like a brand new synthetic value that combines a number of benchmarks covering a wider range of workload patterns? Or should it just be a normalized GHz number? Ironically enough this problem can only be worse in a PaaS context because it is supposed to be playing at a level of the stack where the hardware infrastructure is completely hidden (and exposing GHz wouldn't make any sense at all). However PaaS doesn't expand its reach to a level where higher level of metrics (such as application response time) can be used because the application code falls into the consumer responsibility and not in the PaaS provider set of responsibilities. Which means you could have a PaaS layer that "screams" but an application layered on top of it that is a piece of junk (performance wise).
I'd like to point out also that you may consider having an end-to-end governance of your entire stack where you can monitor high-level metrics for the services / applications and you let the "governance system" deal with the monitoring and capacity planning of the virtual hardware and all other layers above it. While I admit this would be a desirable state we are not quite there at the moment.
However, if you think at the separation of duties and roles that this multi-layer cloud stack brings in - a stack made of many different services interfaces each of which has a provider and a consumer - we also need to make sure each of these interfaces has a way to be measured consistently. In other words, it may not be a human being having to deal with the measurement of these IaaS metrics, it may be a "governance system" that automatically does that for the human being, but yet we need to instrument these interfaces so that the "governance system" can deal with them.
Imagine for example a situations where a SaaS provider may be the consumer of external IaaS resources, this end-to-end monitoring becomes difficult to achieve hence the need to create more detailed SLA metrics between the various layers and their interfaces in the stack. In this specific example how is the SaaS provider subscribing IaaS resources? How are these virtual hardware resources going to be measured, monitored and enforced from a performance perspective by the two parties when the two parties are separate entities with separate duties? How do you define those boundaries from an SLAs perspective? That's what we are debating here.
To GHz or not to GHz? That is the problem. All in all, the GHz based capacity planning and monitoring is dead. However it seems we are still flooded with IT tools that are leveraging it pretty heavily.
I'd like to hear what you think and if you have any opinion on how to address this problem.
Massimo.