Ad Hoc Designed Infrastructures: do they still make sense?
The topic in this article is something that I have been thinking about for a while. It's about the methodology, the patterns, the habits - if you will - associated with how new IT infrastructures are being assessed, designed, sold and - in the final analysis - acquired by end-users for their datacenters. While it might not make a lot of sense to you initially, please bear with me as I go through my "internal mental brainstorming." It seems long but, as usual, it's full of pictures.
The Italian market is pretty interesting: the vast majority of the customers are (very) small organizations distributed across the entire territory. We also have a few medium-sized businesses (although not the core economy of the country), and then we have big organizations (a mix of public customers and privately held corporations). To turn this into IT terms, the vast majority of Italian customers' datacenters are very small - in the range of 5 to 15 x86-based servers. We then have customers - such as medium-sized businesses, big banks and big public organizations - that have hundreds to a few thousand x86-based servers. Having spent most of my IT career focusing on the optimization of the x86 infrastructures, I had to deal with all these scenarios above so I think I have a pretty complete view of the spectrum. This article is going to discuss specifically a couple of points that I had to deal with during the process:
- The assessment of the legacy infrastructures from a capacity and characteristics perspective.
- The design of the target architecture of the virtualized infrastructures.
These are two different aspects, and they could deserve a dedicated discussion, but I am trying to cover both in this article anyway.
Assessing and Designing Optimized x86 Infrastructures for the Small IT Shops
At the very beginning of the virtualization era (around 2002-2003), I was using a pretty standard methodology that would require the analysis of the current datacenter in terms of number of physical x86 servers deployed, their hardware configuration and their usage (average at least, historical at best). You would then take the data and work through them to get to a specific hardware sizing that was capable of consolidating those physical servers onto a lower number of physical boxes. This has worked pretty well until a few months ago when I sat down with my good fellow Maurizio Benassi and we drafted a brand new methodology for sizing. It all started with a joke:
"The majority of customers could be consolidated on either one single mainframe (which never breaks), two Unix boxes (which very rarely break) or three x86 servers (which happen to break from time to time)."
A further analysis of the patterns resulted in an updated joke (err: statement) regarding the new pragmatic methodology:
"One x86 server could sustain the whole workload, the second x86 server is configured for high availability, the third server is used to sleep well at night."
Fun aside I guess you are starting to see a pattern here. Think about that for a moment: the fact is that the smallest x86 architecture you can configure today is capable of supporting the workload that the vast majority of customers have in place. And I am using the notion x86 architecture here on purpose since you never - ever - configure a single x86 box for any given datacenter - no matter what the workload is. What happened in the last few months is that the majority of the virtualization requests I have seen coming in could be served efficiently with a standard configuration which comprises just a couple of Nehalem-based servers tied together with some sort of shared storage. Why would you bother assessing a common pattern and reinventing the wheel (er: the architecture) every time? More on this later.
Designing Optimized x86 Infrastructures for the Medium and Big IT Shops
This is a completely different realm, however assessing, designing, selling and acquiring such infrastructures do have their own peculiarities which might contrast with the standard historical methodology I have mentioned above (deep level analysis of the installed base to produce a to-be new infrastructure). I have already discussed in the past a more pragmatic approach to sizing (virtual) infrastructures I ended up using in the last few months. I still stand behind the controversial comments in that article regarding the opportunity to go through a detailed analysis of the entire environment Vs taking a shortcut like the one I have described in the post. It's interesting also to notice that, similarly to what happens for the small shops, the layout of the to-be virtualized infrastructure doesn't dramatically change across the different situations. Sure the size might change dramatically, in fact where most if not all small shops could be doing fine with two servers, these enterprise customers might require a different number of physical servers (along with a different amount of storage and network connections); however the high-level architecture isn't so drastically different among all the configurations I have been working on. I am referring to common patterns we can learn from such as shared storage configurations, cluster(s) of virtualized servers and common network configurations.
By the way, this isn't supposed to be shocking and the pattern could be easily explained. In the old days - when physical deployments where the norm - you had to take into account each application silo, and determine the best infrastructure configuration for each. That's how you ended up with complex and heterogeneous scenarios where some applications could be deployed on physical standalone servers with no redundancy, other applications had to be deployed on physical standalone servers with some degree of redundancy, others yet had to be deployed on dedicated physical clusters - forget active / active heterogeneous application clusters - for the most demanding high availability requirements. Virtualization, at least in the context of the 100% virtualized datacenter if I can steal Chad Sakac's mantra, is changing all this complexity. First applications are no longer bound to specific physical servers so you can start thinking in "MIPS" terms for the whole infrastructure rather than sizing each vertical silo on its own. This is when my rule of thumb comes handy as you will always - most likely - end up in the average (the more servers you have the better it works).
Another side effect of virtualization is that it has raised the bar of SLAs and you can tune your service levels on the fly without having to re-work your entire hardware infrastructure underneath. A good example is the possibility of moving your workload from SATA storage to Fibre Channel storage on-line (or nearly on-line) if you need it, or creating your application high availability policies at run-time time: in a VMware infrastructure, for example, this might be No-HighAvailability, HighAvailability or even FaultTolerance. At the end of the day, designing an enterprise infrastructure boils down to sizing the aggregated workload (where aggregated is the key word here) and providing the right set of infrastructure characteristics and attributes that an organization might require (with the flexibility to apply them to selected workloads only at workload deployment time).
Do the Functional Requirements Matter During the Design Phase?
Simply put, IT is comprised of two major building blocks: Functional Requirements and Non-Functional Requirements. This is how Wikipedia defines them:
Functional Requirements: "A functional requirement defines a function of a software system or its component. A function is described as a set of inputs, the behavior, and outputs (see also software)"
Non Functional Requirement: "A non-functional requirement is a requirement that specifies criteria that can be used to judge the operation of a system, rather than specific behaviors. This should be contrasted with functional requirements that define specific behavior or functions".
So the question I have been thinking about for the last few years is simple: in a virtualization context, do I really need - during a customer engagement - to go through a deep level analysis of the applications currently being deployed or soon to be deployed? In addition, defining the new virtualized infrastructure to support the applications mentioned, do I need to analyze all those applications one-by-one (from a Non Functional Requirement perspective) or can I treat them as a whole? You can depict the answer from the following two slides which are included in a set of charts I created back in 2007.
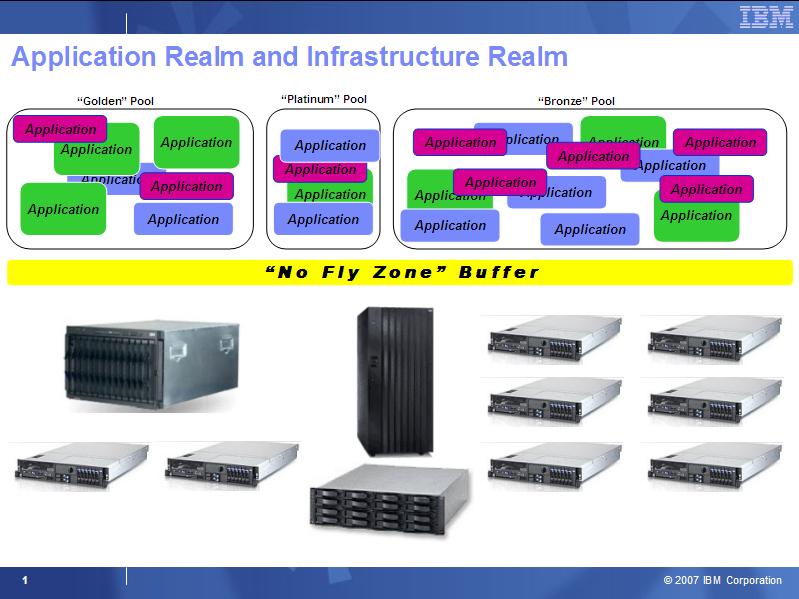

The yellow line "No Fly Zone" Buffer pretty much captures the concept I am trying to articulate here: the application realm and the infrastructure realm don't need to be strictly correlated. The infrastructure underneath needs to be designed and architected to match current and projected total workload of the functional requirements. In addition to that it needs to be designed to match the customer's policies around the required Non-Functional Requirements. None of these two items requires an in-depth analysis and assessment of the various application silos currently deployed in a non-virtualized datacenter.
Does the Public Cloud Concept Bother With Functional Requirements After All?
You have heard the buzz lately about internal and external Cloud, haven't you? And I am sure you heard the concept of Private (aka Internal) and Public (aka External) Clouds. The idea is that you can have a given workload that you can choose to execute either internally on your infrastructure or externally on a third-party infrastructure (typically that of a service provider). This should happen transparently.
It is obvious at this point that the Public Clouds out there have not been designed upfront with your own applications in mind and nor they can be. That is obviously impossible. First, they are shared infrastructures so they should be ad hoc designed against more than a single customer (impossible). Plus they are ready to use so they need to be in place before the provider could even think about assessing your internal infrastructure - assuming it makes sense, but clearly it doesn't as I said above - to be able to support it in its Public Cloud. All security concerns about running applications in a Public Cloud aside for a moment, let's agree that you can effectively run your application either internally or externally. And if that is possible, why would you need to purpose design an ad hoc internal infrastructure based on an assessment and in-depth analysis of the legacy, if the public infrastructure allows you to do that without going through that pain? That's simply because the Public Cloud infrastructures are designed against standard well-known successful patterns that have been used to design internal virtualized infrastructures for years.
This doesn't mean all Public Clouds are equal - they might vary greatly in terms of the characteristics they offer (Non-Functional Requirements). You might find Public Clouds that are optimized for costs, some others might be optimized for high availability, and others still might be optimized for Disaster Recovery scenarios. This is exactly similar, in concept, to how you would want your own private datacenter to behave: are HA and DR important to you (for all or just a selection of applications)? Is scalability important to you? Is data protection important to you? And so on. Again, this is somewhat unrelated to the fact you use IIS or Apache, Lotus Domino or Microsoft Exchange (you name your favorite application here).
The problem we have today is that, while we define Public and Private Clouds as being very similar from a "plumbing" perspective, the way they are sold/bought by vendors/customers is too different. We tend to rent a service with some characteristic on the Public Cloud, whereas most customers still buy dispersed technology parts to build a Private Cloud.
Sure there are big differences in the sense that while you "buy" a Private Cloud, you actually "rent" a Public Cloud (well, a part of it). Similarly a Private Cloud is dedicated whereas a Public Cloud is shared. Last but not least the management of a Private Cloud is on you whereas the management burden of the Public Cloud is on the service provider. However, if you look at the plumbing (the way servers, networks and storage are assembled and tied together with a hypervisor) the differences are not so drastic. What if the industry started hiding all the plumbing details of Private Clouds and started selling them like Public Clouds are sold? In a scenario like this customers wouldn't buy various pieces of technologies to assemble together; rather they'd buy and then manage a certain capacity with a certain level of Non-Functional Requirements (as opposed to rent and let the provider manage a part of a Public Cloud). What we have seen so far is hardware vendors (aka Private Clouds vendors) adding Public Clouds services offerings. I wouldn't be surprised to see service providers of Public Clouds turning into _Private Clouds vendor_s as well leveraging their know-how.
It's All About the Metadata!
As I said, I have been thinking about this concept of simplifying the way virtualized x86 infrastructures are proposed by IT vendors and, in turns, acquired by the end-users. I knew there was a single word to define all this but I was struggling to find it until I read this very interesting post from vinternals. Metadata: that's the word I was looking for. Thanks, Stu! In fact, this fits pretty nice with the VMware mantra of vApps if you think about this for a moment. Those of you that have been working on the matter have probably seen this chart many times.

The idea is that, through the OVF standard, a vApp (basically a collection of a number of virtual machines that can provide a service to the end user) publishes its Non-Functional Requirements to be satisfied. As Stu points out, while the vApp can publish its requirements, there is no structured way - as of today - for the infrastructure underneath to publish what it is capable of providing. However, if you have noticed, I am trying to push this concept a little bit further: not only infrastructure metadata for Non-Functional Requirements is a must to create the binary match between what the applications require and what the infrastructure is capable of providing, but it also could be used to revolutionize, as I said, how the new infrastructures (comprised of hardware, storage and networking) are designed, architected, built and sold/acquired. This in turns means a shorter and easier sales cycle for vendors and proven, reliable, fully supported all-in-one infrastructures for customers.
Reference Architectures: Examples
In retrospect, this is exactly what I was trying to achieve (without using the terminology and the notion I am using in this article) when I started to talk about virtualized reference architectures during customers' and partners' events in the last few months. I have used a fairly simple approach which might be the basis for a more sophisticated speculative sizing algorithm. First of all, I made a few assumptions in terms of sizing based on the rules of thumb I have published in the past (and adjusted to map onto the new technology).
The above step covers the "sizing" part but it doesn't really cover the characteristic of the configuration (i.e. what we now call Metadata in the context of this article). I then started to draft a few common scenarios (or reference architectures if you will) that I have seen being commonly and successfully used by many customers. Actual numbers and other assumptions we have used are not important in this context. I am just showing you the framework I have used and I am sure those numbers and overall assumptions might need more work to capture better patterns.
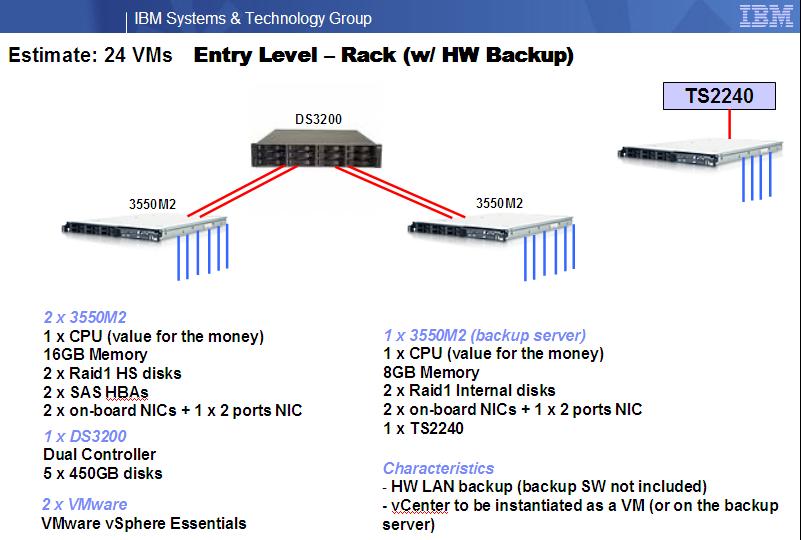
The following is the first example that I presented at a joint IBM-LSI-Intel-VMware event last spring:
This is obviously a very simplistic approach. In addition, it would be laughable (I agree) to call these two brief comments a List of Non-Functional Requirements. Although the next few examples are a bit better, by no means is this a comprehensive implementation of the potential shift in the industry that I am discussing.
The following chart illustrates another example which is a superset of the above configuration where we have added the backup solution.
The following is another example which uses the BladeCenter S as a foundation. Note: don't pay too much attention to the number of VMs a configuration like this can support compared to the others. We have used HS12 blades which are single socket blades that don't use the brand new Intel Xeon 5500 (Nehalem) CPUs so the #VMs/Core is a bit lower. Again these are just examples.

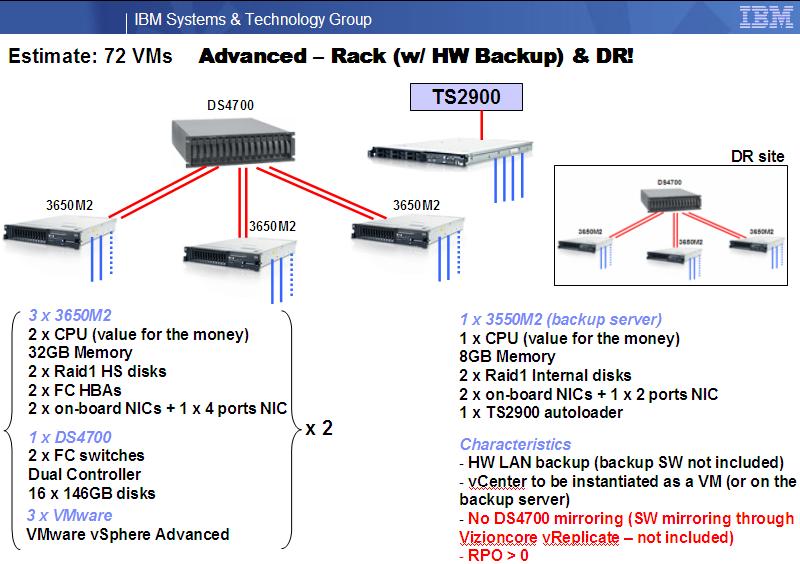
The chart below is an example of an infrastructure capable of supporting about 72 VMs and with a "DR counterpart" to be installed at a remote site. In this example, we didn't use the native Storage mirroring capabilities and we opted for a cheaper software replication alternative. Notice the RPO (Recovery Point Objective) is greater than 0 since software based replications like this do not allow a complete sync of the two storage at any point in time. This is a typical Non-Functional Requirement discussion and a design point. This should be one of the first things that Metadata should publish as a characteristic of the underlying infrastructure. If you want you can use more sophisticated and native replication technologies as I discussed in this post.
One interesting thing to notice is that the first configurations are comprised of the smallest hardware configurations you can buy today in the market. That's true for servers as well as for the storage components. Yet the workload they can sustain with this minimal configuration (expressed in estimated number of VMs) exceeds the total amount of workload with which most of the SMB customers need to deal. This underlines again that an in-depth analysis to determine the size of the target environment is, in most cases, not even required.
Conclusions
In this article, I questioned the value of two specific practices: first, assessing legacy infrastructures is becoming more and more useless because, on one hand, we have so much power available these days that for most customers in the SMB space the smallest thing vendors could design might be a bazooka to shoot a fly. For Enterprise customers, most of the time a rule-of-thumb approach (perhaps complemented with deferred purchases based on actual needs) seems to be a good compromise between quality of the output and the effort required to get to the output.
I have questioned the value of designing ad hoc infrastructures: this is true for both SMB and Enterprise shops as we have enough experience in the industry at this point to start pushing reference architectures applying best practices we have learned in the last 10 years without having to reinvent the wheel (or the architecture if you will) every time.
I know this is a bit of a stretch and, in fact, it's a sort of provocative article. However, while we are not clearly there today, my guess is that as we move toward the 100% virtualized datacenters, we might start to talk in the sense of selling and buying not just in terms of discrete components and technologies that can be used to create ad-hoc infrastructures, but rather in terms of black boxes that have a total aggregated throughput associated which could be expressed in "number of average VMs" or in any other metric that you can think of.
Additionally the black box would carry a label with a list of capabilities, or metadata, that describe the characteristics of the Non-Functional Requirements associated to that specific unit. A vendor might have more units in the catalog with different capacity and different levels of Non-Functional Requirements. The whole idea is to try to simplify the way these solutions are designed, architected and sold by people in the field on one side, and the way they are purchased by the end-users. And with virtualization, which decouples functional and Non-Functional Requirements, we might see the light out of the tunnel this time.
Massimo.