VMware HA Vs Microsoft Cluster Server: we are at the inflection point
Lately, there have been many discussions on the Internet and on various forums regarding the implementation of HA clustering technologies (namely and primarily Microsoft Cluster Server) within virtual machine environments (namely and primarily VMware infrastructures). Many customers are still treating virtual machines as if they were standard Windows servers (or Linux for what that matters) so this does make sense.
However there is a trend in this industry that is shifting typical infrastructure services from the multi-purpose operating systems into the virtual infrastructure. The top of the iceberg of this trend is called Virtual Appliances. While many view Virtual Appliances as a starting point of something big and new I really see them as the natural result (big and new) of this trend that is... turning the hypervisor into a so called Data Center OS. I have discussed this trend in a presentation that I did at VMworld 2007 in San Francisco and that you can access here.
If you stop for a minute and think about what it is happening in this x86 virtualization industry, you'll notice that many infrastructure services that were typically loaded within the standard Windows OS are now being provided at the virtual infrastructure layer. An easy example would be network interface fault tolerance: nowadays in virtual environments you typically configure a virtual switch at the hypervisor level, comprised of a bond of two or more Ethernet adapters and you associate virtual machines to the switch with a single virtual network connection. What you have done in this case is that you have basically delegated the virtual infrastructure of dealing with Ethernet connectivity problems. This is a very basic example and there are many others like this such as storage configuration/redundancy/connectivity.
These two pictures should graphically outline this trend:
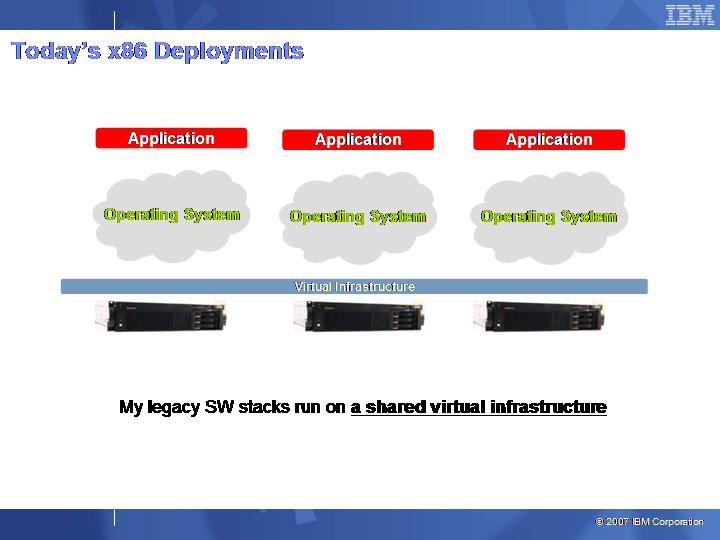

(for higher quality pictures please refer to the presentation linked above)
Back on track, one of these infrastructure services that is about to migrate from within the multi-purpose OS where the application runs all the way down into the virtual infrastructure is the High Availability service. In the VMware vocabulary this is called VMware HA and this is a piece of code/intelligence that is part of the VI3 offering and whose purpose is to protect virtual machines from host failures. Basically what happens in this case is that, should a host fail, all virtual machines running on top of that failed host get automatically restarted on surviving nodes being part of the same VMware HA Cluster. However many readers would point out that there are at least a couple of very important architectural differences in how VMware HA compares to Microsoft Cluster Server implemented within virtual machines:
- In the case of VMware HA there is a single instance of the virtual machine (with the application) to be protected. The VM is being started on a given node of the cluster given the status of the others (availability and resource utilization). Many people still think that the software stack loaded in the virtual machine is a Single Point Of Failure (imagine a Service Pack upgrade that goes wrong for example and you will have an unplanned downtime of the VM and in turn of the application). On the other hand a "virtual" MSCS solution requires two independent Windows nodes (virtual nodes in this case) so that should any problem occur within the software stack of a node it won't affect the availability of the application that can be restarted on the other virtual node.
- In the case of VMware HA, you are really only monitoring the status of the physical server. Should a physical server go down the virtual machine is restarted on another node of the cluster. This scenario doesn't cover the software stack status within the VM nor, obviously, the application status within the VM (it must be noticed that VI3.5 introduced experimental support for monitoring the status of the OS within the VM via VMware Tools heartbeat check-points). On the other hand in a Microsoft Cluster Server solution you would typically be able to be protected by physical host failures (obviously) and you also would be able to monitor the application status so that a given service can be restarted onto another MSCS node should it fail to start on the "primary" node even if the node has not failed.
This picture should outline the differences of these two approaches:
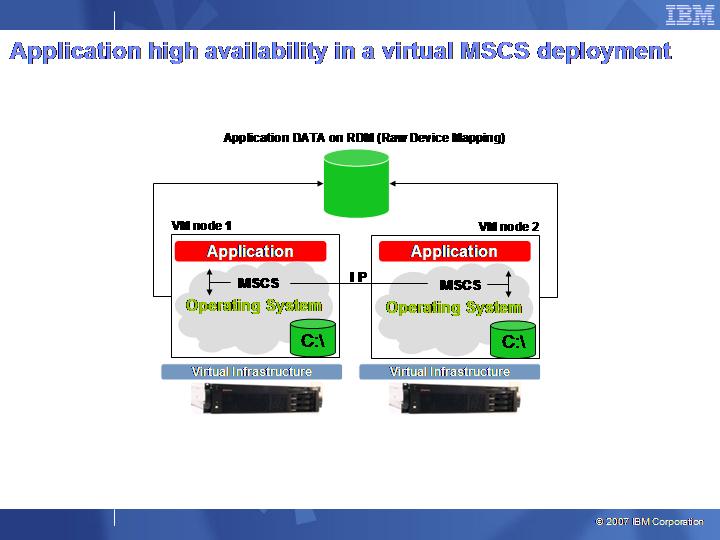

I guess you can easily depict the philosophical differences between the two approaches. The first one is more traditional and tends to treat virtual machines as we have been treating physical servers in the last 10 years, applying the same practices and technologies. In the second picture, the philosophy is more innovative and tends to treat a VM as a simple object which leverages the new virtual infrastructure capabilities.
We are clearly at an inflection point now where many customers that used to do standard cluster deployments on physical servers (which was the only option to provide high availability) are now arguing how to do that. They now have the choice to either continue to do so in virtual servers as opposed to physical servers (thus applying the same rules, practices and with little disruption as far their IT organization policies are concerned) or turning to a brand new strategy to provide the same (or similar) high availability scenarios (at the cost of heavily changing the established rules and standards). The reason I am saying we are at an inflection point is because I really believe that the second scenario is the future of x86 application deployments, but obviously as we stand today there are things that you cannot technically do or achieve with it. Plus, there is a cultural problem from moving from an established scenario to the other.
The following table tries to summarize advantages / disadvantages of both approaches:
| Characteristics | HA Cluster within the VM | HA Cluster at the virtual infrastructure level |
|---|---|---|
| Easy deployment | no | yes |
| SW stack redundancy | yes | no |
| Application Monitoring | yes | no |
| "Guest OS independent" high availability | no | yes |
| Allows to apply traditional practices and IT standards | yes | no |
| Allows to decouple application functionalities from high availability functionalities | yes | no |
| Easy to implement / inherit DR properties | no | yes |
- no: Not True / can't be achieved
- yes: True / can be achieved
These are a few of the characteristics many users are currently debating. Again you can depict from the above that delegating this infrastructure service (i.e. HA) to the virtual infrastructure is a better way to implement a data center...at least in my opinion. Assuming proper and effective backup/restore procedures can be implemented for your virtual environments, assuming that you don't need strict application monitoring (or that HA clusters at the virtual infrastructure will improve over time) and assuming an IT organization can adapt easily to new deployment methods and standards... it's obviously where you want to go in the long term.
It is interesting to notice that there are a number of limitations in deploying an MSCS solution in a VMware VI3 environment: one is the fact that the VMDK files corresponding to the C:\ drive of the virtual machine nodes need to reside on a local, non-shared VMFS volume of a given ESX host - which is typically a small partition on the local hard drives that also contains the hypervisor code. On top of this there are a number of other limitations but it suffices to say how bad and not very flexible a Microsoft Cluster Server solution implemented on top of VMware VI3 can turn out to be, with no VMotion of the virtual nodes themselves given the non shared disks.
Another problem associated with the usage of HA software packages within virtual machines is that VMware tends to randomly pull in and pull out support for this at every minor and/or major infrastructure release update. Sometimes I am wondering whether these limitations imposed by VMware are due to technical challenges or to strategic politics from VMware to undermine the minds of those customers that want to keep their traditional practices. In fact this underlines the nature of the VMware strategies which is clearly not only that of introducing a hypervisor between your physical box and your legacy software stacks, practices and standards... their strategy is to literally scramble the entire data center in terms of software stacks, practices and standards. And it's not necessarily a bad thing if you think that these stack, practices and standards are not optimal (as I do).
At this point I also must remind readers that MSCS is an example that might be confusing for the simple fact that this is the very same technology that MS will be using to cope with this new trend. The idea is that, instead of using MSCS within a couple of virtual machines as we described above, they will be using MSCS to act as the High Availability mechanism for Hyper-V similarly to what VMware HA does for ESX. These pictures should clarify the idea:

Last but not least I also should mention that VI3 and MSCS are respectively examples of an implementation of an HA solution at the virtual infrastructure level (VI3) and an example of an HA software package at the virtual machines level (MSCS) that I have been using throughout this document to describe the concept. There are other technologies that can be mapped to the same concept and the list hereafter is an attempt to mention some of these options:
| Virtual Infrastructure solutions w/ HA capabilities** | High Availability Software Packages for setup in Virtual Machines |
|---|---|
| VMware Virtual Infrastructure | Microsoft Cluster Server (MSCS) |
| Microsoft Virtualization (Hyper-V w/ MSCS) | Veritas Cluster Server |
| VirtualIron Extended Enterprise | ...... |
| Citrix XenServer (HA module in roadmap) | |
| ............. |
This oversimplifies a very complex matter; for example one could notice that VCS (Veritas Cluster Server) could be used either within a virtual machine environment (as reported in the table above) or as an alternative to VMware HA at the virtual infrastructure layer - similar to how MSCS can be used either within virtual machines or in conjunction with the Hyper-V parent partition. Interestingly enough, in such a context (i.e. used at the virtual infrastructure layer), VCS is potentially able to monitor application status provided the proper Veritas agents are loaded within the virtual machine guests...although this challenges the benefits of a deployment like this being potentially Guest OS agnostic.
Obviously all this discussion strictly pertains to typical HA scenarios where you have an application that deals with and manipulates data, and for which you need a shared storage solution. In all situations where the application is stateless and high-availability can be achieved load balancing multiple instances of it (a good example is a farm of web servers), then both high-availability and scalability is inherited by the layout of the application deployment and doesn't require any "infrastructure HA assist" (be it at the virtual infrastructure level or within the virtual machine).
In the end my suggestion is that users try to evaluate the pros and cons of the "legacy" option vs. the pros and cons of the "new trend", which leverages virtual infrastructure capabilities so that they can take educated decisions. Emotionally I do like the second option much more because it's.... better. But I perfectly understand many IT organizations have their own problems jumping on the wagon right away. By the way, I am totally for virtualization, but realistically I wouldn't rule out the potential situations of keeping some particularly critical x86 workloads on a physical MSCS cluster if that is required. Some organizations also like the idea of implementing N+1 clusters where you can protect N independent physical servers using a single virtualized host on top of which run N virtual images which are the MSCS nodes counterparts of the physical systems to be protected. While this sounds like an interesting scenario - and it is for some situations - it involves the same supportability and limitation concerns we have discussed above.
As a matter of fact, closing this long post, I have realized that I am ok with everything .... but with using HA software packages within virtual machines running on top of virtual infrastructures.... It's just too complicated, too risky, too cumbersome... too "no way."
Massimo.