Using AWS Step Functions to mitigate code liability
Code is a liability. That’s not only the code you write but also (and predominantly!) the code that you need to operationalize for your own business logic to work. In this blog post I would like to demonstrate how it is possible to reduce, for relatively simple use cases, that liability by many orders of magnitude.
Background
At re:Invent 2021 I presented a session whose title was You have a container image: Now what?.
This was one of the key take-away slides I presented:
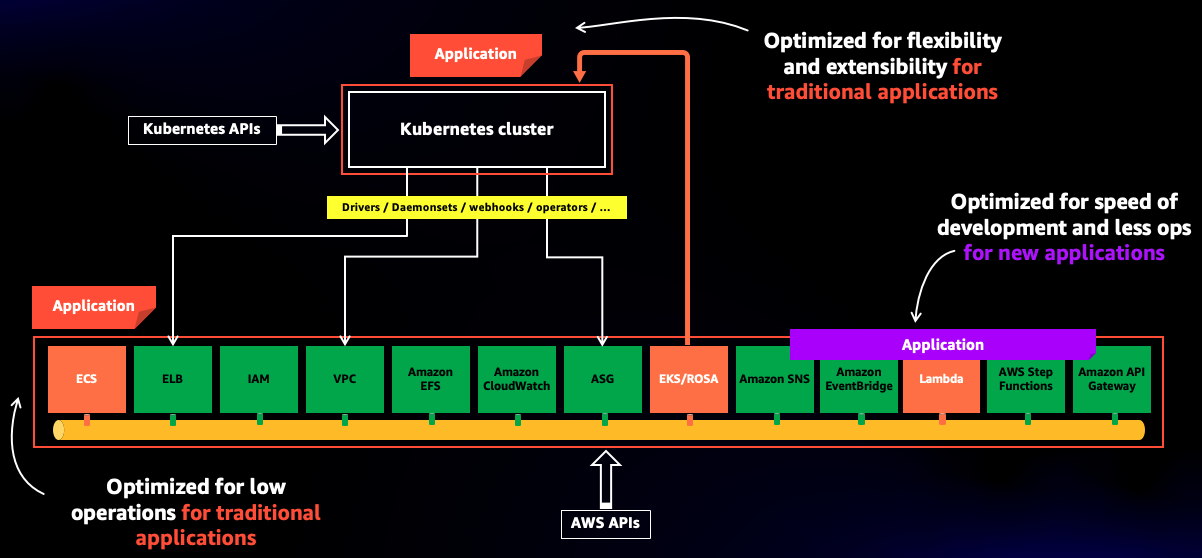
Among closed friends circles, the way I informally like to talk about this slide and the concepts behind it is that there are 3 options (or philosophies) you can use to deploy code if you have the AWS infrastructure as your target. You can deploy your code...
- ... on Kubernetes (you want to use a Kubernetes API to deploy containerized applications, think EKS)
- ... on AWS (you want to use an AWS API to deploy containerized applications, think ECS)
- ... in AWS (you want to use AWS as the framework and runtime to build applications, think Lambda, Step Functions, API Gateway and more)
These options provide a different degree of flexibility and operational burden. Deploying your code on Kubernetes allows you to be more in control, but it also means you are taking over a large operational surface. On the other side of the spectrum, you can build and deploy your code in AWS with a serviceful approach. Here you have more opinions and less configuration flexibility, but you leverage AWS to provide security, scalability performance and operational excellence to your application.
To measure the operational efficiency I coined the term MTBU (Mean Time Between Updates) to track the burden of how frequently you need to update/upgrade the software stack to be able to operate with the highest degree of security, supportability, scalability, reliability and feature enhancements. While you want the provider to continuously do these updates behind the scenes (e.g. you always want more features), ideally you want your MTBU to be infinite (
firedeploy and forget). However, in reality your MTBU is measured in weeks or months (very rarely in years) depending on the options you use.
[UPDATE] Someone pointed out that a better way to describe this operational efficiency metric would be MTBM (Mean Time Between Maintenance). I like that! While I won't try to fix this entire article with it, I may be using that variant in the future! Thanks Phillipp.
The remaining of this post focuses on how to optimize operations and how to achieve an MTBU that tends to infinite by running code... in AWS.
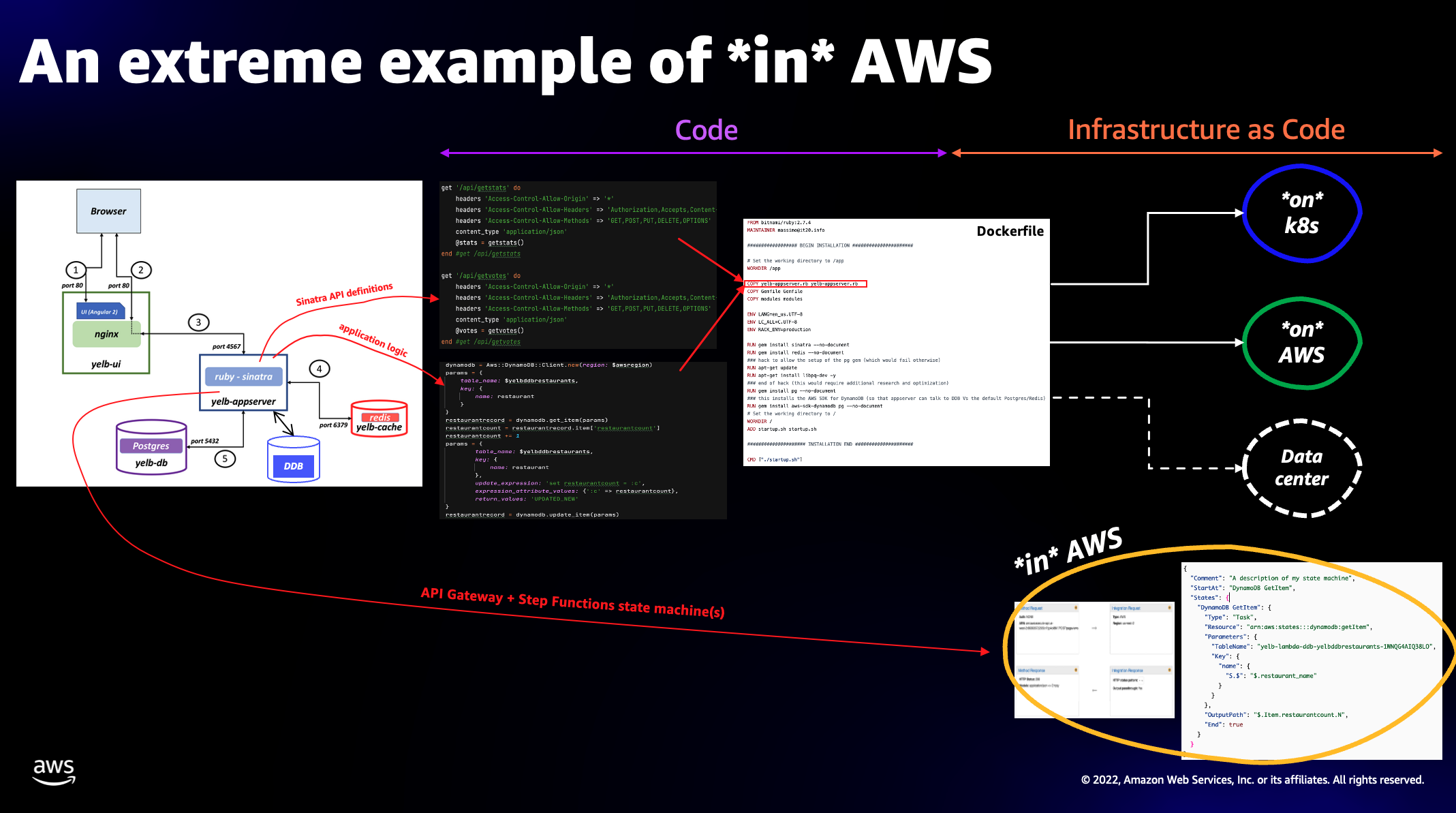
The on Kubernetes and on AWS are concepts that are often easy to grok (if nothing, because they are just slightly different mechanics to deploy the same container image) but the in AWS is sometimes hard to define and describe. That is why I want to use a practical example to describe this option. Let’s dive in.
Yelb
Yelb is a sample application that I have used for the last 6+ years to experiment with various technologies. The core of Yelb is an application server written in Ruby/Sinatra that stores votes (and page views) in a backend database that could be either a combination of Postgres and Redis or DynamoDB. Yelb also ships with a user interface written in Angular. Yes Yelb is just yet another voting application.
You can check the Yelb high level architecture on the home page of the project on GitHub and you can navigate all the deployment options at this page (being able to experiment all new deployment options over the years with an existing application was one of my main goals for Yelb). For example, you can follow these instructions to deploy Yelb on ECS and these instructions to deploy Yelb on EKS.
Let’s focus on the ruby component. You can explore the application server source code in its own folder here. The main artifact is the yelb-appserver.rb file. This program imports the Sinatra framework to create the various APIs that the app server exposes (e.g. to vote for a particular restaurant or to retrieve votes among other things). Also note that the business logic has been split into different files and functions. This was done to enable re-using these modules with AWS Lambda leveraging the “adapter pattern” that Danilo has talked about in this blog post. In the same folder there is the Dockerfile that is used to create the container image for the Yelb application server.
What stood out over the years from experience is that the amount of code that I am responsible for (e.g. the base container image, the ruby runtime and my own code) is incredibly disproportional when compared to the amount of business logic I need. In fact, if you think about that, the business logic for a voting application is very much A=A+1. That’s all the logic I need, really.
At the time of this writing the latest version of the app server image on Docker Hub is 224MB (compressed!). 224MB of software I have to maintain and operate to do A=A+1. This is bonkers!
This is the flexibility price I need to pay to be able to run the Yelb application server either on Kubernetes or on AWS. This model is very convenient (and there is no surprise the majority of applications are built this way), but the MTBU in this case is measured in weeks or months because that container image needs to be curated. And if you use Kubernetes you also need to curate the platform you built on it, lowering further the MTBU.
There has got to be an easier way if I don’t want the liability of 224MB of code to increment a counter!
AWS Lambda to the rescue
The obvious way to reduce the operational burden (and increase the MTBU) would be to run the code in AWS by leveraging a set of Lambda functions to host the business logic fronted by an AWS API Gateway to expose the app server APIs. This reduces substantially the code surface I need to own because I no longer need to use Sinatra (the API Gateway, a fully managed AWS service, is responsible to expose my APIs) and Lambda can manage the Ruby runtime for me. I am effectively only bringing to Lambda the Ruby functions (along with their library requirements).
This is a great approach and one that a lot of AWS customers are adopting to reduce the operational burden and get access to a world where they let AWS dealing with the majority of the undifferentiated heavy lifting.
However, this model is not perfect either, and it can lead to events that lower your MTBU. For example, Lambda has recently deprecated the Ruby 2.5 runtime I had used for the port I did 3 years ago and that generated some additional work on my part. The long story short is that this change caused my original zip artifact to diverge from the runtime and the zip file with the functions and the libraries had to be re-built for the proper Ruby version. You can read more about the details of the changes I had to implement in this blog post.
This was largely more of an annoyance than a problem, and it was primarily due to my own bad practices and lack of proper automation. For example, not pinning specific versions in the various libraries, makes the build scripts very fragile over time. For a customer with proper versions pinning in place and good build pipelines in operation this would definitely not be a problem.
Note: Lambda has introduced support for container images years ago and I already have a container image for the application server. I am indeed considering leveraging that as the artifact to pass to the Lambda functions instead of building an ad-hoc zip like I am doing now. While the zip is more efficient, and it allows me to offload the runtime responsibilities to AWS, I consider the container image to be more convenient for my specific use case. Yes, in doing so, I am essentially subscribing to maintain and operate 224MB of code in Lambda, which may not be the best option if you want to increase the MTBU.
Again, Lambda is a great solution that allows a developer to push much of the operational and software stack complexity to AWS. It also allowed me to forget about maintaining that stack for about 3 years before having to update it. A 3-years MTBU! Not bad! But can I do more? Can I reduce the amount of liability in a way that is proportional to my business logic (A=A+1)? And, by doing so, can I extend the MTBU to something that is close to infinite?
Enter AWS Step Functions
I have always seen Step Functions as being a “glue” (or the skeleton) for complex workflows that tie together various pieces of a distributed application. The states would transition from running a piece of code to another piece of code. This code would run in Lambda functions or in Fargate tasks, for example, and Step Functions would coordinate the flow.
However, over time, I started to see Step Functions under a different (or additional) angle as the service started to evolve.
First and foremost Step Functions includes a lot of the core and basic features of a programming language to allow developers to write if-then-else statements, create for loops and more from within the ASL (Amazon States Language):

Second, Step Functions includes a certain number of intrinsic functions that allows developers to manipulate and transform data in a way that is similar (albeit obviously limited compared) to a traditional programming language. And these functions keep improving over time: a few weeks ago the Step Functions team has introduced 14 new intrinsics.
Third, Step Functions has since introduced the notion of Express Workflows. From the documentation: “Express Workflows are ideal for high-volume, event-processing workloads such as IoT data ingestion, streaming data processing and transformation, and mobile application backends. They can run for up to five minutes. .... This makes Express Workflows ideal for orchestrating idempotent actions such as transforming input data and storing by way of a PUT action in Amazon DynamoDB.” Do you see where I am going here with this?
Last but not least, the Step Functions team has expanded service integrations to more than 200 AWS services via the new AWS SDK Service Integrations that we released in 2021. This feature allows developers to interact with the majority of AWS services from the Amazon States Language as they would when leveraging the AWS SDK from a traditional programming language:

These capabilities mean, for all practical purposes, that instead of writing a traditional program, a developer can use the ASL in Step Functions to natively interact with AWS services like they’d do using SDKs, manipulate data with intrinsic functions and leverage basic conditionals and loops flows.
As a bonus, you get to do all this with the easy-to-use Workflow Studio for a nice low-code experience. As an example, this is the implementation of one of the application server APIs (getvotes) re-implemented in Step Functions using Workflow Studio:
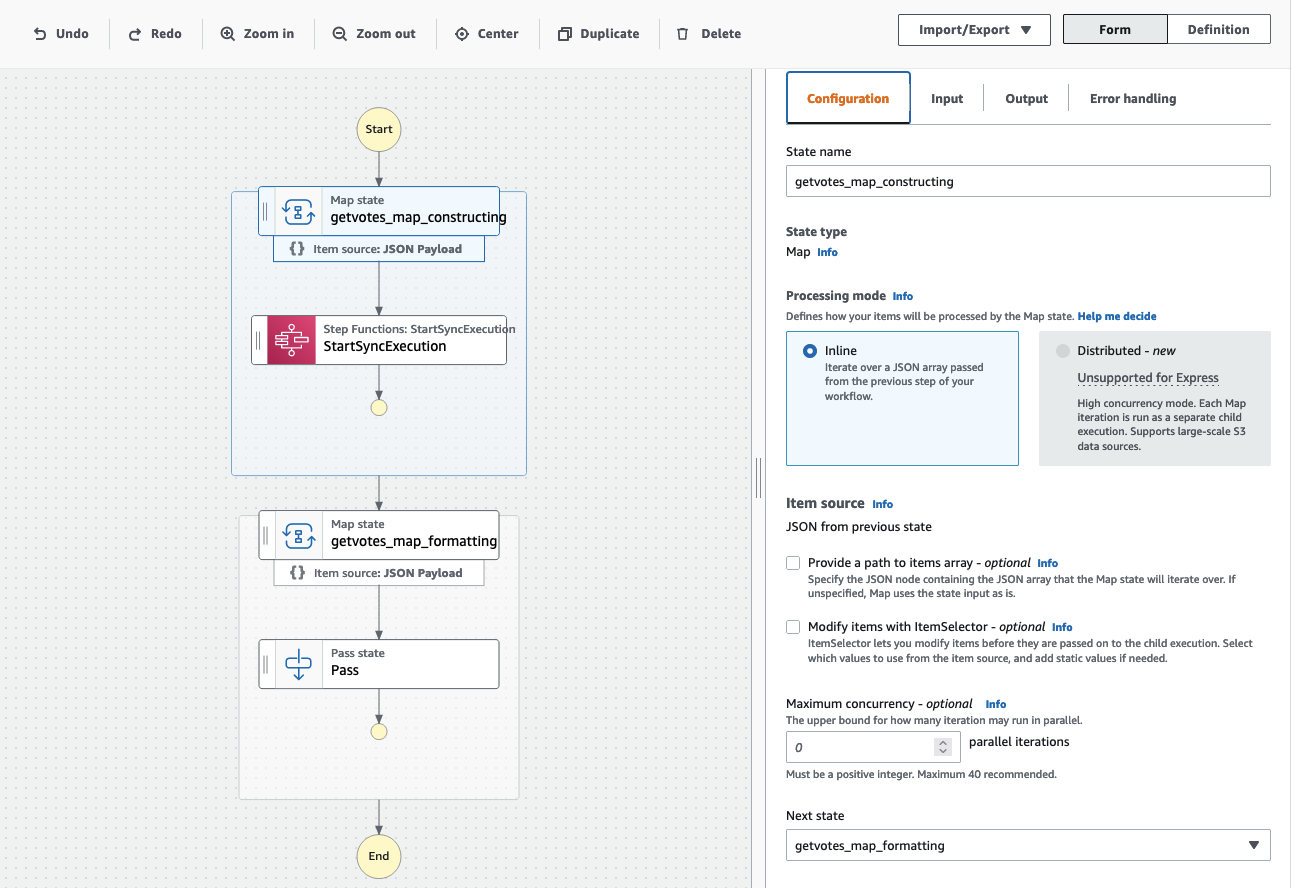
Note that you are not tied to work in a low-code setup if you don’t want to. The Workflow Studio view above generates the following ASL and you can work on either, depending on your development preferences:
1{
2 "StartAt": "getvotes_map_constructing",
3 "States": {
4 "getvotes_map_constructing": {
5 "Next": "getvotes_map_formatting",
6 "Type": "Map",
7 "Iterator": {
8 "StartAt": "StartSyncExecution",
9 "States": {
10 "StartSyncExecution": {
11 "Type": "Task",
12 "Parameters": {
13 "StateMachineArn": "arn:aws:states:us-west-2:693935722839:stateMachine:smrestaurantdbreadF1A4A8B7-85oQEzzouqE2",
14 "Input.$": "$"
15 },
16 "ResultSelector": {
17 "name.$": "States.StringToJson($.Input)",
18 "value.$": "States.StringToJson($.Output)"
19 },
20 "Resource": "arn:aws:states:::aws-sdk:sfn:startSyncExecution",
21 "End": true
22 }
23 }
24 }
25 },
26 "getvotes_map_formatting": {
27 "End": true,
28 "Type": "Map",
29 "Iterator": {
30 "StartAt": "Pass",
31 "States": {
32 "Pass": {
33 "Type": "Pass",
34 "End": true,
35 "Parameters": {
36 "name.$": "$.name.restaurant_name",
37 "value.$": "States.StringToJson($.value)"
38 }
39 }
40 }
41 }
42 }
43 }
44}
The implementation
The way I approached this refactoring was by starting from the APIs that the Yelb user interface expects to interact with (and that I have originally implemented in the Yelb application server) and work backwards from them. I wanted my Step Functions implementation to be 100% backward compatible with the Ruby implementation. In other words, I did not want to make any change to the user interface. This is at the core of a microservice architecture where each service exposes an API as a contract and that contract can’t be broken (unless all parties agree). Of course, I have access to the user interface code and I could have made changes there if I needed to, but I wanted to simulate being in a more constraint (and real-life) scenario here.
The yelb-appserver application logic exposes these 8 APIs through Sinatra (note the response format for each and example values):
1'<endpoint>/api/pageviews' -> 5
2
3'<endpoint>/api/hostname' -> ip-172-31-48-193.us-west-2.compute.internal
4
5'<endpoint>/api/getstats' -> {"hostname": "ip-172-31-5-185.us-west-2.compute.internal", "pageviews":5}
6
7'<endpoint>/api/getvotes' -> [{"name": "outback", "value": 1},{"name": "bucadibeppo", "value": 0},{"name": "ihop", "value": 0}, {"name": "chipotle", "value": 3}]
8
9'<endpoint>/api/ihop' -> 2
10
11'<endpoint>/api/chipotle' -> 1
12
13'<endpoint>/api/outback' -> 4
14
15'<endpoint>/api/bucadibeppo' -> 3
This is a breakdown of what the APIs do:
1'<endpoint>/api/pageviews': -> it increments the page view counter (+1) and returns the value (int)
2
3'<endpoint>/api/hostname' -> it returns the hostname of the system where the app server is running (string)
4
5'<endpoint>/api/getstats' -> it returns the page view counter + hostname (json)
6
7'<endpoint>/api/getvotes' -> it returns the restaurants vote counters (array of json)
8
9'<endpoint>/api/ihop' -> it increases the restaurant vote counter (+1) and returns the value (int)
10
11'<endpoint>/api/chipotle' -> it increases the restaurant vote counter (+1) and returns the value (int)
12
13'<endpoint>/api/outback' -> it increases the restaurant vote counter (+1) and returns the value (int)
14
15'<endpoint>/api/bucadibeppo' -> it increases the restaurant vote counter (+1) and returns the value (int)
Some of these APIs are not even called by the user interface (e.g. pageviews) but I wanted to implement them all for high fidelity. Also, the way these APIs have been implemented in the Ruby code is via a series of functions that I wanted to keep as consistent as possible in the Step Functions implementation (as a way to better resonate about them in both contexts rather than having two completely different implementations).
Note that the getvotes I have shown above is a state machine that executes synchronously another state machine (restaurantdbread). But how does a state machine that deals with a DynamoDB write looks like? Here is how the restaurantdbupdate ASL looks like:
1{
2 "StartAt": "restaurantdbupdate",
3 "States": {
4 "restaurantdbupdate": {
5 "End": true,
6 "Type": "Task",
7 "Resource": "arn:aws:states:::dynamodb:updateItem",
8 "Parameters": {
9 "TableName": "StepFunctionsStack-yelbddbrestaurants70424F48-1NVUR508DKKL0",
10 "Key": {
11 "name": {
12 "S.$": "$.restaurant_name"
13 }
14 },
15 "UpdateExpression": "SET restaurantcount = restaurantcount + :incr",
16 "ExpressionAttributeValues": {
17 ":incr": {
18 "N": "1"
19 }
20 }
21 }
22 }
23 }
24}
This is the core of my application logic. This is where I am doing A=A+1 (in the ASL language). Note how I am, effectively, implementing my application logic as part of IaC. In this model, there is no other code other than IaC. This application is running indeed in (as “inside”) AWS.
A complete CDK implementation of the IaC required to stand up this deployment model (which includes the DynamoDB tables, the state machines and the API Gateway) is available on the Yelb GitHub repository in the Step Functions folder.
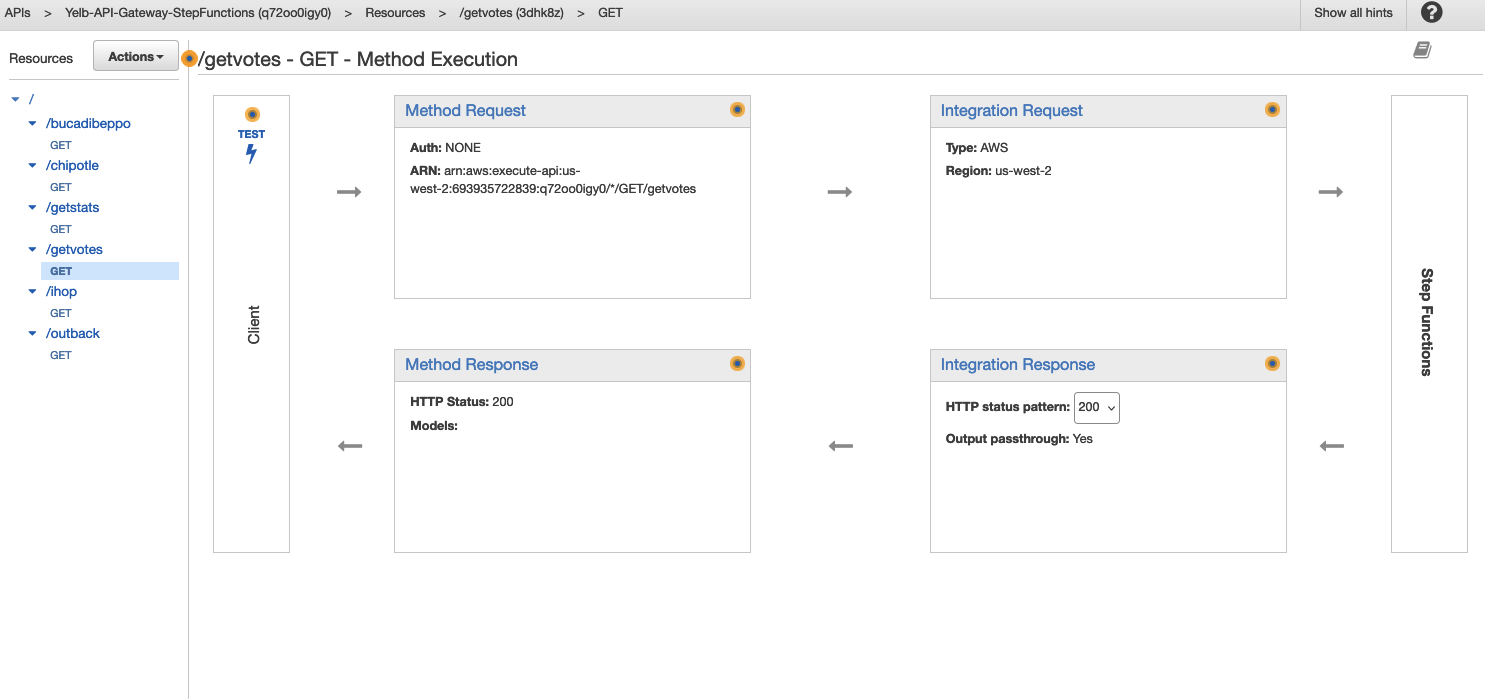
The CDK program will create the APIs (in AWS API Gateway) the Yelb user interface expects to interact with:
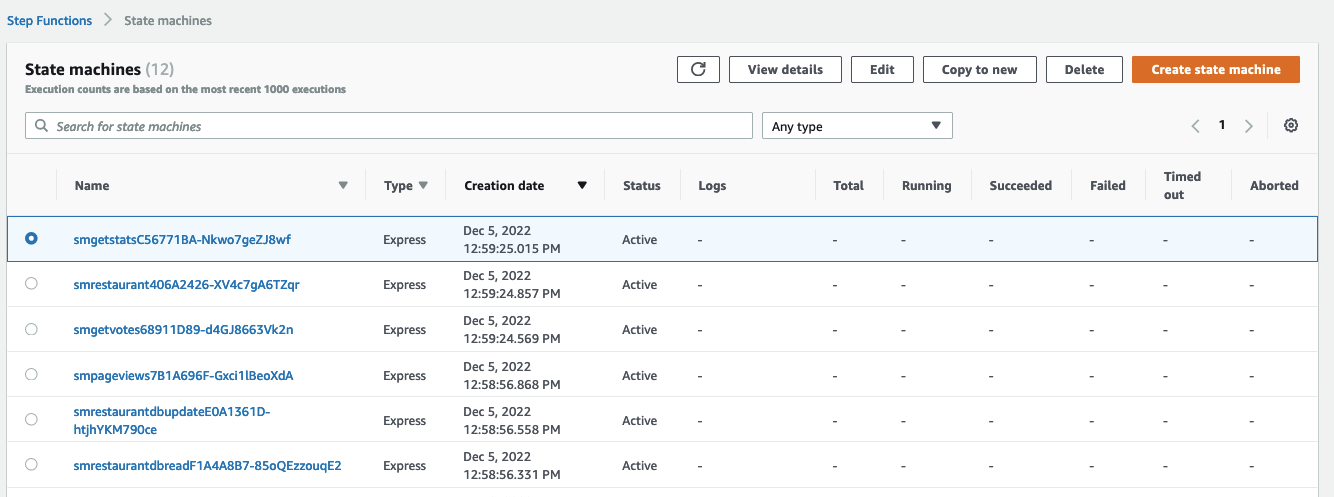
In addition, the CDK will create the state machines (in AWS Step Functions) that back the APIs above:
Fun facts and learning
The most challenging part of this exercise was manipulating the data and specifically dealing with state machines inputs and outputs. The Step Functions documentation covers in details the capabilities but one needs to get used to this new way to deal with the flow of data during states transitions (at least that was my experience).
Consider that the applicability of this approach is limited to code with simple application logic because the power of the intrinsics, conditionals and loops in ASL are not nearly as sophisticated as in traditional programming languages. Also, the astute reader may have noticed that if all you need to do is A=A+1, you have a direct integration between API Gateway and DynamoDB and you don’t need a Step Functions state machine in between. Consider the content of this blog for demonstration purposes of what you could build within the constraints of the ASL.
A fun fact related to data manipulation is what happened when I forgot to emit an int instead of a string as part of the output of a workflow. Can you spot what happened with the Total field during this intermediate test? It took me a few minutes to understand why the “math” was wrong:
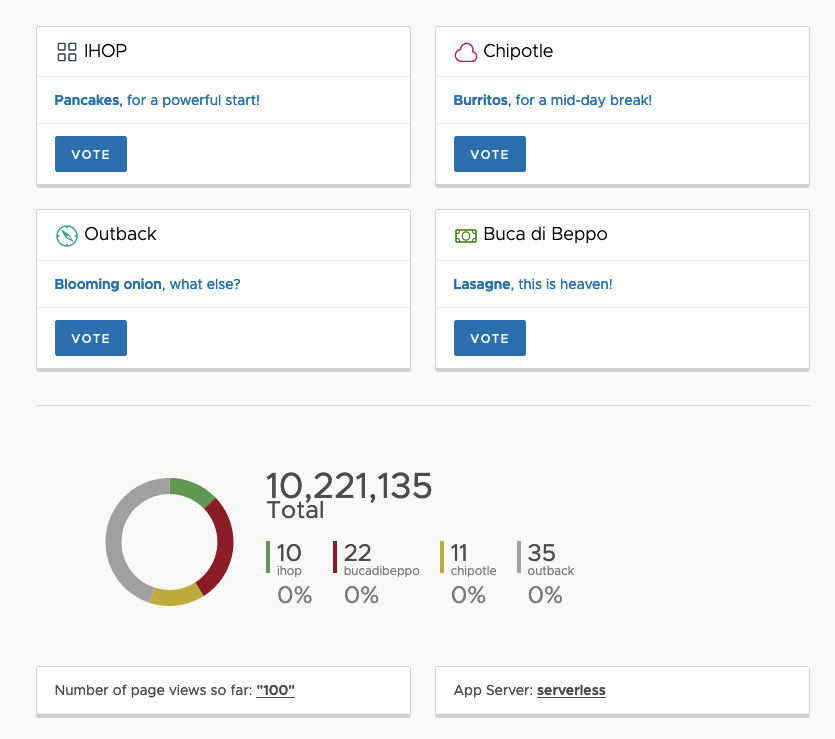
Another fun fact related to this refactor is that, originally, the Ruby program would dynamically read the name of the “host” it was running on (this could be an EC2 instance or a container depending on the deployment model). The yelb-appserver would then report it back to the user interface as part of the getstats API and the user interface would show it in the “App Server” field (bottom-right). Because with Step Functions there are no hosts whatsoever, the state machine that backs the refactored getstats API always return the string “serverless” for this field.
Conclusions
The interesting aspect of this deployment is that there is no reasons why, 5 years from now, this application would not be running in a completely secured and supported manner. This PoC was geared towards demonstrating how it is technically possible to extend the MTBU to almost infinite.
The screenshot below tries to capture the nature of what we have done: we have refactored a microservice that was deployed using a mix of application code and IaC into a set of AWS services configuration allowing us to get rid completely of the application code and moving the limited business logic into the IaC using the Amazon States Language. In essence, we have eliminated 224MB of code liability by introducing a negligible amount of ASL in the IaC.
The other interesting aspect is that this deployment model does not require any curating effort when it comes to scaling. It scales from 0 to the current, but always evolving, concurrency limits of the AWS services being used (i.e. API Gateway and Step Functions). No scaling in and out configurations, no instances or containers to deal with.
Again, if you want to play with this PoC please visit the Step Functions folder in the Yelb repository and deploy it in your account.
Performance and costs optimizations have not been taken into account while refactoring the Ruby code into ASL. Similarly, the IaC as a whole and the Step Functions state machines are far from being optimized.
Let me know what you think!
Massimo.