Site Recovery Manager: what is it (going to be) good for?
VMware, at VMworld 2007, announced that next year they will provide an out-of-the-box solution/product for Disaster/Recovery scenarios. It is called Site Recovery Manager (SRM for short) and it is supposed to orchestrate and facilitate system administrators to create a D/R plan for their organizations. It is important not to confuse this product with a "stretched HA cluster" or a "Geocluster" configuration. This is a "red-button" type of product where a human being, with high-level responsibilities within the organization, will assess the situation and, in case, will declare a "disaster" which in turn means that someone will push that red-button and restart the IT organization onto the DR site. This is not usually something that an operator decides at 3AM because he/she can't ping a host or, even worse, something initiated by an automated IT trigger/sensor.
Essentially SRM will be a sort of automated and programmed workflow. This product won't add any cool low-level new technology, it will "just" provide a workflow engine that you can program to execute the very manual steps you would execute today in a disaster scenario. This is a summary of what it should be able to do for you:
- Integration of storage replication for minidisk synchronous/asynchronous alignments (Production site <-> DR site)
- Automation of startup sequence / suspend at the remote site of virtual machines (this includes management of QoS / SLA's)
- Network reconfiguration of virtual machines to comply with the (potentially) new IP schema in the DR site
- Creation of a "sand-box" environment at the remote site in order to test you DR plan(s)
In case a disaster strikes, once you push that famous red-button described above, SRM will activate the mirrored LUN's at the remote site, it will restart the virtual machines on the DR site based on the programmed sequence and it will adjust (optionally) the IP settings of the vm's to fit into the new network schema (if it is different). Additionally SRM will allow you to "play" the plan on a regular basis for test purposes creating a snapshot of the production vm's and activating them in a sort of "network sand-box". I have over-simplified here a bunch of very complex activities.
Believe it or not these are two charts I have been presenting to my customers since 2002/2003 (you can tell it from the Windows 2000 virtual machine and the good old xSeries 440 and Shark pictures) to describe a sample DR architecture.
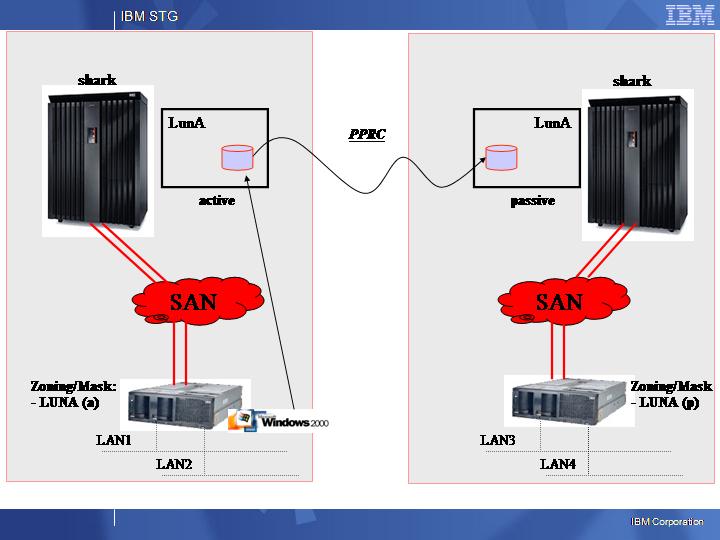
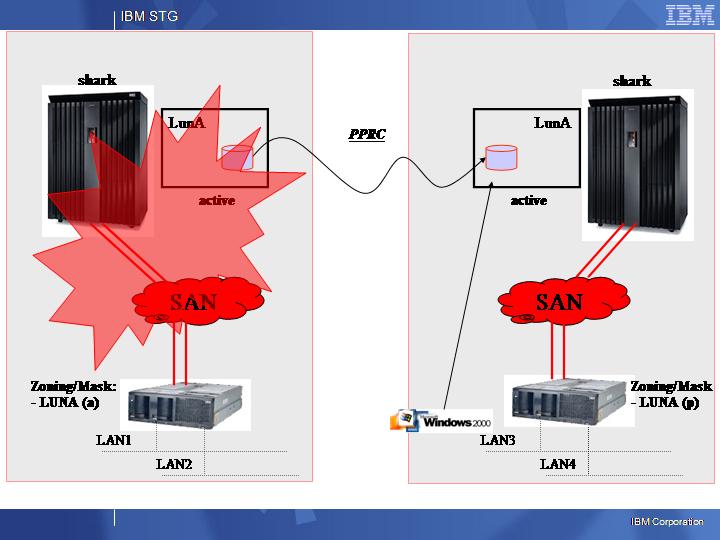
They seem pretty similar to what VMware is showing today for SRM. And in fact they are similar, simply because, as I said, SRM is just something that adds up a clever / programmed workflow to automate what we used to do manually in 2003 (up until today actually).
This sounds cool (and I can tell you it is cool). However I have been working with a few customers recently to discuss DR plans for their VMware deployments; a few points got my attention and made me think: is SRM going to be a good fit for these customers and specifically for their production / DR requirements?
I must say upfront that I am not an expert on this product (which is still currently in pre-beta as far as know) and I doubt that there are any experts out there at the moment (other than its Product Managers and the developers working on it). All I know is from presentations I have seen on the technology and a few informal discussions with VMware people.
I am currently talking to some enterprise customers looking for a holistic DR plan for their infrastructure where VI3 plays a big role but it is not the only platform that needs to
This is not simply because they want a single consistent process to kick everything at once. This is mostly due to some multiplatform requirements they have and they need to cope with. Let's go through some of them and touch the points where SRM might (possibly) fall short... at least as far as I can read from the documentation.
- One of the constraints these customers have is the following. As soon as a disaster is declared they need to switch consistently everything onto the DR site. This practically means that, for the disk subsystem configuration, they need to stop the whole synchronization link (for all platforms) and reactivate all LUN's on the DR site at once. They can't afford to have each platform implement a different mechanism and triggers to reactivate LUN's on the remote site. They want someone/something to do this (1) at the very same point in time and (2) for the whole IT cross-platform environment. Having each platform do this "on their own" is probably more cumbersome to manage and could possibly lead to potential data inconsistencies. Reading through the SRM documentation it seems that storage integration is a key component of what it does as a product. So the question I have right now is... will SRM be able to "run through the plan" assuming the storage replica has already been managed (reactivated etc) by another "big-brother" above it? Or will it require to deal with everything end-to-end?
- Assuming the point above can be managed somehow, one of the other roadblocks I see is the multi-platform dependencies. With these complex IT environments nowadays a given "IT service" could be provided by multiple software components possibly running on heterogeneous hardware platforms (typical example would be the usual 3-tier web/appl/db architecture). It might very well be that, for some enterprise customers, there are inter-platform dependencies so that in order to activate a given "service" an infrastructure application running on a physical x86-Linux server needs to start first, then a Unix database needs to be turned on and subsequently another application running in a Windows virtual machine can start. This is just a mere example and the situation can become more and more complex, especially as the server population and the number of services to be reactivated increase. I do understand that within SRM you can create sort of check-points where you stop the "plan-run" so that external events can occur but in a complex situation this might not be easy to manage as you need to create so many break points that they invalidate the whole concept of having a single red-button that will work through the entire plan. At first look it seems to me that SRM has been designed to be a very compelling VMware-centric workflow engine even though in a complex multi-platform environment being too much singleplatform-centric has never proven to be a good thing. I am pretty sure that SRM is going to be a life-saver for potential VMware-only shops (some SMB accounts?) or for those that have a simple multi-platform deployment but...is it going to be a good fit for many complex enterprise multi-platform scenarios where a higher level of orchestration might be required?
There would be other "potential weaknesses" that one could point out looking at the SRM ver 1 specifications (i.e. missing capability to monitor the actual application status within the virtual machines as triggers for the recovery plans) but these would be more enrichments/enhancements of a technology that is supposed to be already useful at day 0. The two points outlined above however are more "design considerations" that might result in a difficult fit of the product for some enterprise accounts. At least those I have been talking to.
Having this said I am sure VMware has done a diligent analysis when thinking about the specifications so it might very well be that these have been taken into account already. All in all it seems to be a promising technology and certainly a great step forward for the VMware business (and those of their customers).
Massimo.