A generic (and highly academic) discussion around multi-tenancy
No doubt there is an explosion of complexity these days in IT. I have discussed it many times on this blog.
The avalanche of new technologies that get released at a super fast pace is astonishing. And the confusion generated is very strong, the latest survey I came across 5 minutes ago confirms.
Among the many many (many) challenges around this, in this blog post I want to focus on a slightly narrow angle of a much bigger picture: multi-tenancy and how all these technologies get “stacked up”.
Disclaimer and terminology settings
Before we move forward I need to get this out of the way: for the purpose of making technology examples one can relate to, I am going to use some VMware technology/terminology. This discussion is more architectural than “products focused” though. So don’t look at the trees, try to imagine the forest.
Also, in the diagrams and in the text I am going to allude to configurations that may architecturally make sense but that are not supported today (and may never be) by said products.
Now onto some terminology check.
Multi-tenancy means a lot of things to a lot of different people. In this blog post I am taking a somewhat loose approach and when I refer to multi-tenancy I typically refer to the capability of 1) carving out and dedicating resources to a user from a shared pool of resources and 2) allowing the user to access those resources in some self-service form or shape.
In the broader context I am exploring, “multi-tenancy” may be considered everything between something as light as “RBAC” to something as strong as “physical partitioning” of resources. It’s eventually the reader’s call to identify and determine whether a particular “multi-tenant” capability in this broad range can satisfy the requirements.
As we progress in this discussion it is also important that we keep in mind that, in a multi-tenant environment, there is a notion of a provider and a consumer.
We are often used to think about this as a simple concept (i.e. there is one provider and many consumers) but the reality is that, if an organization is enough sophisticated, there
In the context above, the provider of a given level, becomes one of the consumers of the level below. More examples of this later.
Patterns (and anti-patterns)
I have noticed lately that a common (potentially anti-)pattern in this furiously evolving industry is as follows:
- Technology A gets released and gains momentum
- You adopt technology A
- Technology B comes along and gains momentum
- You stack technology B on top of technology A
While this may make sense in some circumstances, it may just be driven by poor planning (or inertia) in others.
Interestingly a similar (potential anti-)pattern exist for the other way around:
- Technology A gets released and gains momentum
- You adopt technology A
- Technology B comes along and gains momentum
- You remove technology A from the stack and only adopt technology B
Let’s take a very practical example.
Customer ABC started deploying a hypervisor solution and then moved to a CMP (Cloud Management Platform) solution for higher level of automation and self-service. Docker came along and the customer decided to stack up Docker on top of the CMP stack (in a multi-tenant sandbox).
Customer XYZ started deploying a hypervisor solution. Docker came along and the customer decided to get rid of the hypervisor and deploy Docker directly on bare metal.
Yes, it does sound a bit schizophrenic (at first). So who’s right?
The above examples touch on so many critical aspects of your architectural, technology, operational and organizational choices that, with all respect due, I truly LMAO when I hear non sense like “use Docker on bare metal because it’s faster”. The problem is that, “being fast”, is one of the 25 aspects you need to consider.
This is not to say that you shouldn’t run Docker on bare metal. This is just to say that you really need to understand what you want to achieve, the context you are operating in and the organizational model you want to implement before you commit to any decision.
At the highest level, there is only one generic rule of thumb to decide whether to “stack up” (what Customer ABC did) or “replace” (what Customer XYZ did): since every layer introduces its own complexity, does said layer provide enough tangible value that can trade off such complexity?
A lot of the value of the many stacks we deal with is around multi-tenancy (and self-service). This is one of the 25 aspects I mentioned before.
While multi-tenancy enablement is not the only reason why you may want (or don’t want) to have a specific layer, I want to focus this post on this very specific angle.
The uber sophisticated scenario (big Enterprise)
So let’s start this discussion from one of the most complex and sophisticated (and flexible) “stacked up” scenarios I could think of right now and walk up the stack:
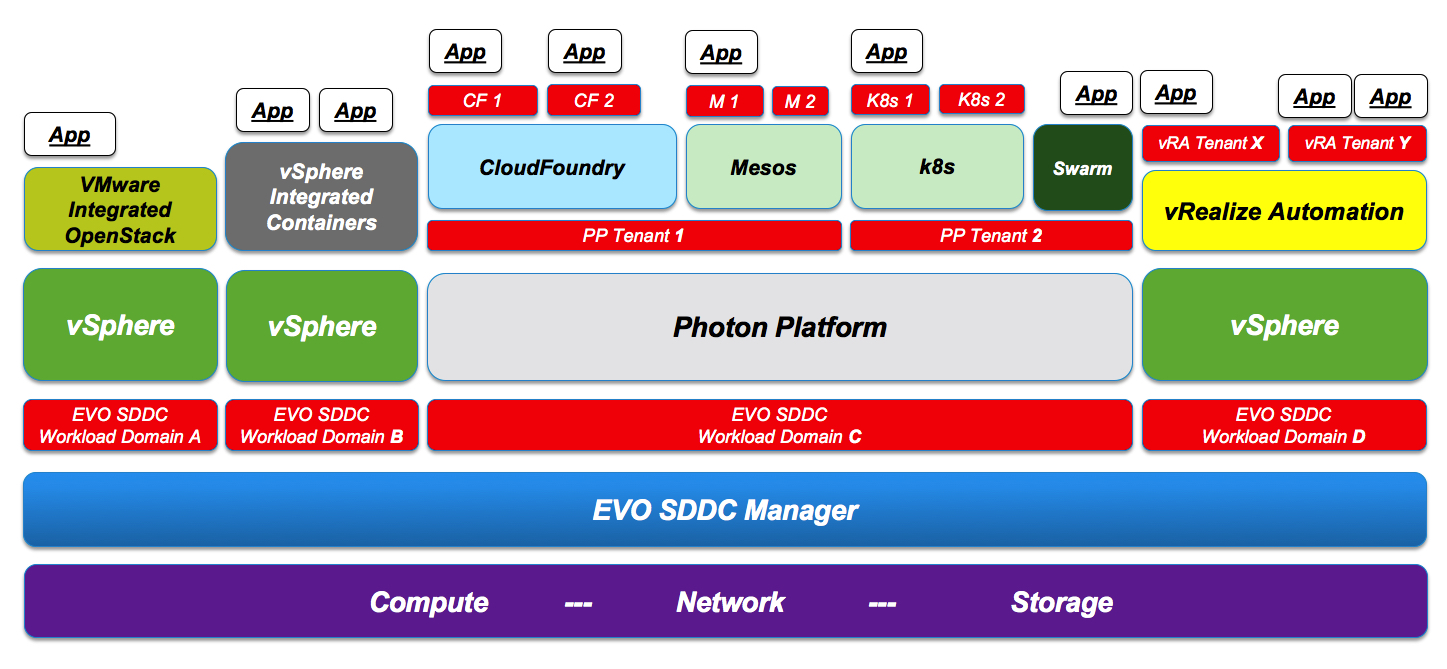
I assume the reader is familiar with vSphere, VMware Integrated OpenStack (VIO) and vRealize Automation (vRA). For the other pieces:
- EVO SDDC Manager is an infrastructure management product that allows a data center administrator to partition the infrastructure (at the physical hosts level) and create what VMware refers to as “workload domains”. If you want to know more about EVO SDDC and workload domains please read this blog post for background.
- Photon Platform is a next generation multi-tenant IaaS platform designed from scratch and geared towards third gen applications. The layout is super lean with a control plane that runs completely distributed on selected hosts. If you want to know more about Photon Platform please read this blog post for background.
- vSphere Integrated Containers is a bridge between the vSphere virtualization world and the Docker containerized world. It runs on top of vSphere: it offers to Docker users traditional Docker interfaces without changing virtual machines oriented operational practices. If you want to know more about vSphere Integrated Containers please read this blog post for background.
- CloudFoundry, Mesos, Kubernetes (k8s), Swarm are all either full-blown PaaS products or raw containers orchestration frameworks. They are usually used to operationalize brand new micro services oriented applications.
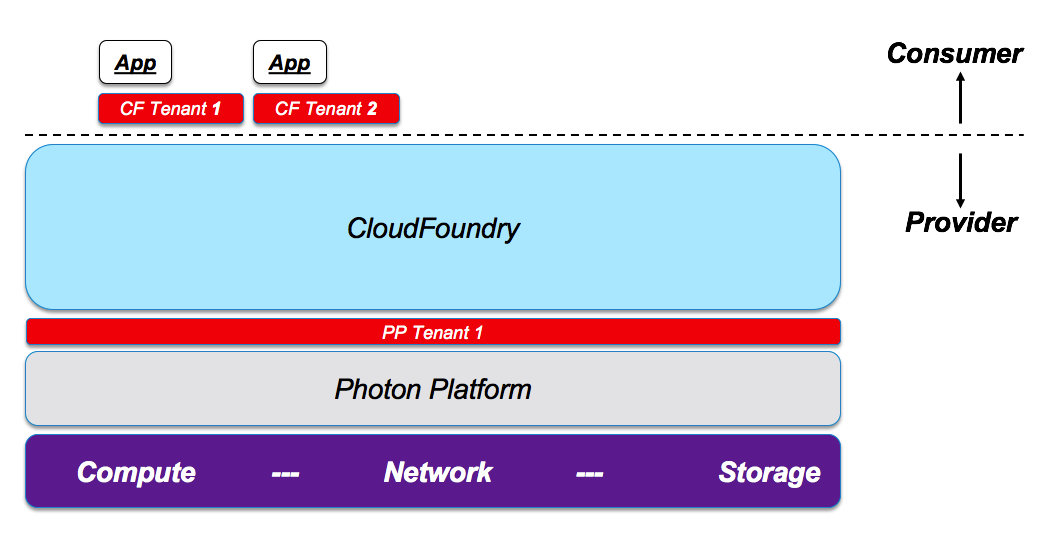
What I am showing here is a very rich and complex multi-layer multi-tenancy environment that may be suitable for a very sophisticated organization. I have highlighted the tenants (at each layer) in red.
Let’s walk through a “branch” of the previous picture to see what I mean by that. This is the path we are talking:
- Jenny is an application developer that deploys apps in a PaaS environment. She is part of a tenant (“CF Tenant I”) that has been defined on a CloudFoundry instance. This tenant has been defined by John, the CloudFoundry admin. John is a provider to Jenny.
- John is a CloudFoundry admin. He is part of a tenant (“PP Tenant 1”) that has been defined on a Photon Platform (IaaS) instance. This tenant has been defined by Mark, the Photon Platform admin. Mark is a provider to John.
- Mark is a Photon Platform admin. He is part of a sandboxed workload domain (“EVO SDDC Workload Domain C”) that has been carved out from a shared physical infrastructure managed by EVO SDDC Manager. This workload domain has been created by Margaret, the EVO SDDC Manager admin. Margaret is a provider to Mark.
If we hide all the other branches of the previously shown complex stack, this is how you can visualize this specific multi-level multi-tenant “branch”:
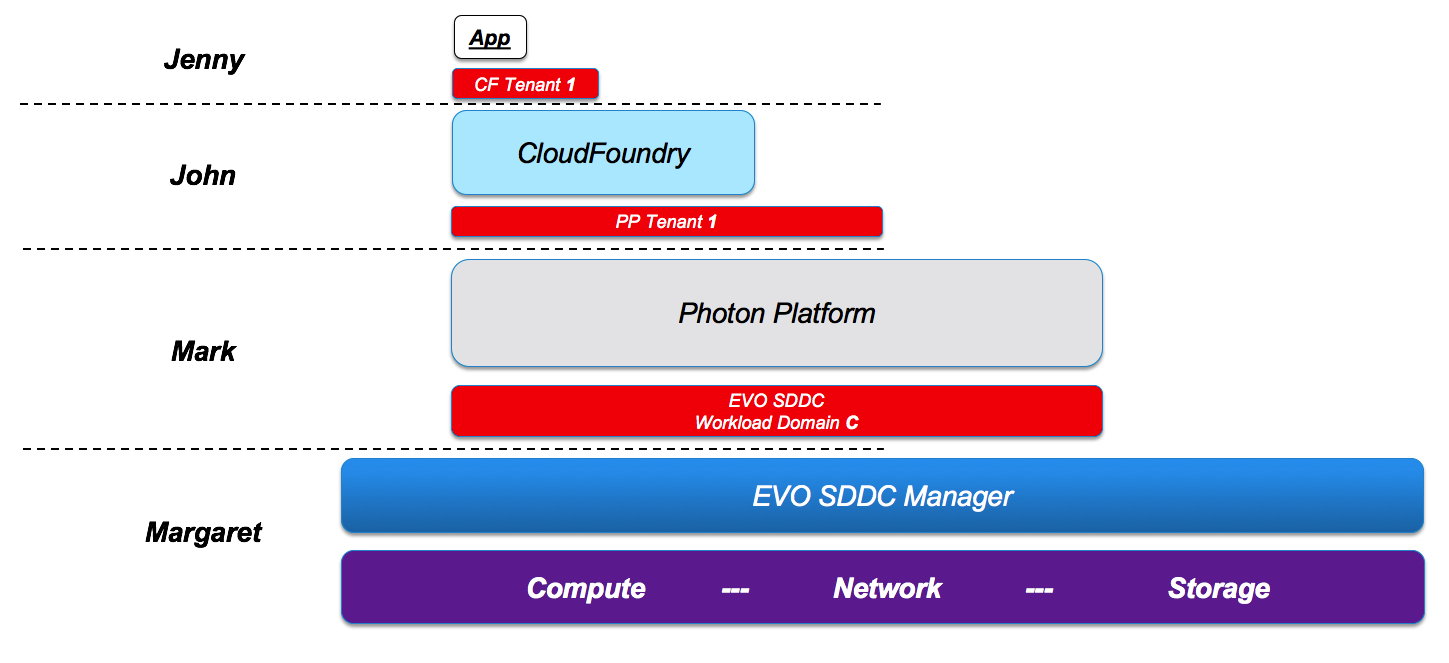
As you can imagine there are a lot of moving parts here. This only makes sense (and is actually a requirement) if you have multiple roles at multiple layers in your Enterprise organization (or if you are a Service Provider where these roles span across companies). Hence you need specific SLA contracts in place for Jenny, John, Mark and Margaret to deliver proper services at their respective levels.
Also, this only makes sense (and is, again, a requirement) if your (Enterprise) organization is using multiple and alternative technologies for different services at the same layer of the stack (e.g. vSphere and Photon Platform). This is to say that there is going to be, for example, Luke that is the vSphere / vRealize Automation administrator that works at the same level (but in a different EVO SDDC Manager tenant) of Mark, the Photon Platform administrator.
There is a myriad of other reasons for which you may need to partition and decouple your layers in a complex organization. Imagine the IT related complexities due to mergers and acquisitions. Or imagine subtler (yet very practical requirements) where you need different versions of the same stack (e.g. View requires version “abc” of vSphere whereas vRealize Automation requires version “xyz” of vSphere).
The less sophisticated scenario (small organization)
Imagine now if you were to work for a smaller organization that is not nearly as sophisticated as the previous one and only has a classic single-layer provider and consumer model. Also, let’s assume that your small organization has standardized on a single application management framework (e.g. CloudFoundry).
How would you go about it? Architecturally, from a multi-tenancy perspective, you could get rid of pretty much all of the layers given that your single-layer multi-tenancy requirement can be satisfied by the native CloudFoundry capabilities:
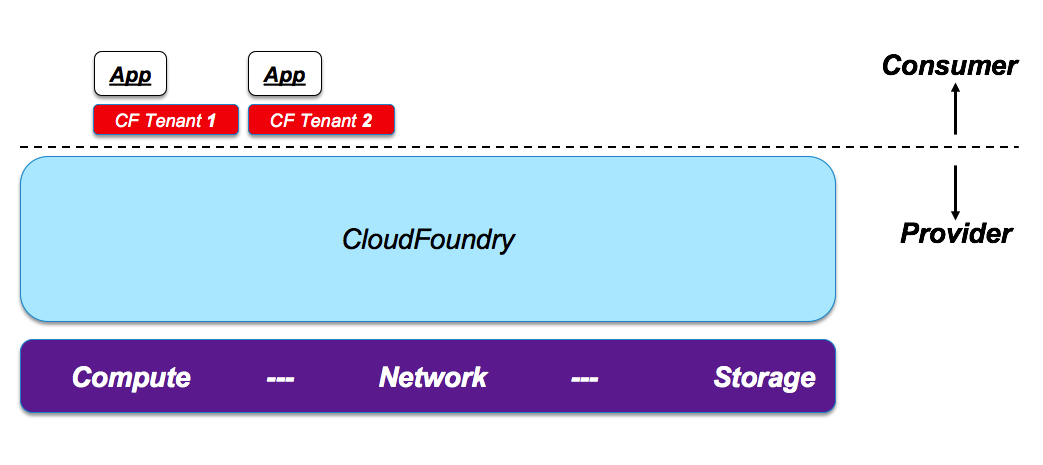
It goes without saying that, in a real life scenario, this will never happen (or at least this will hardly happen).
First of all, CloudFoundry is likely not going to be the only solution required company-wide. It will most always likely be “one of many”.
Also, multi-tenancy requirements aside, the organization may find useful to have a hypervisor for other reasons (i.e. OS image templates, ease of nodes provisioning etc).
Because of the above, you may even find the stack below a better solution for the same context:
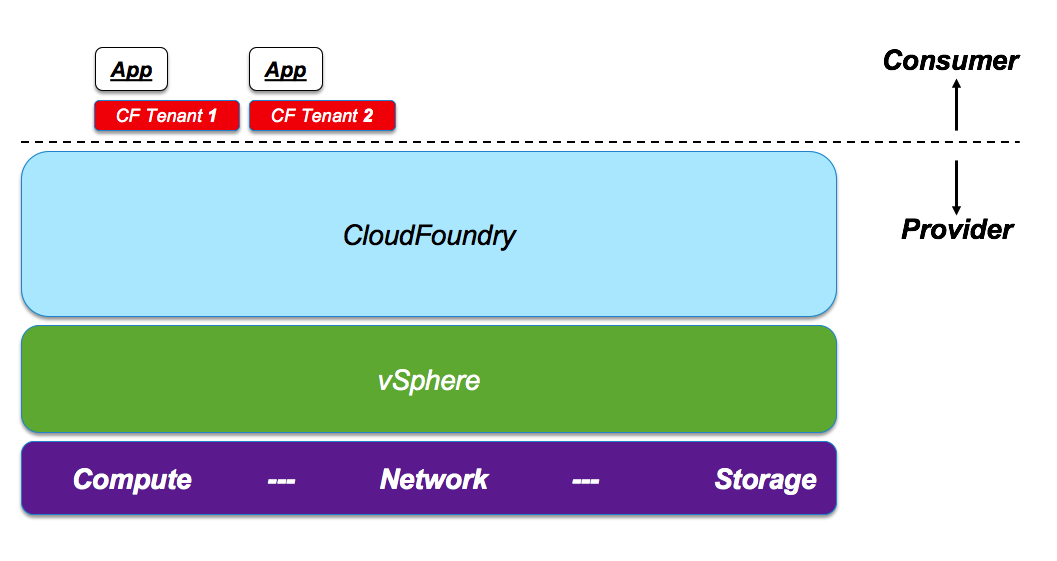
Important note: as we have said multiple times this post focuses primarily on the multi-tenancy angle. I picked vSphere to stress that it is “good enough” even without multi-tenancy support.
For other reasons and characteristics one may opt to use a different platform that could fit better 3rd generation applications patterns (e.g. Photon Platform).
In other words, something like this:
Notice how the multi-tenancy capability here is irrelevant (we can do with only one tenant); the technology choice was driven by considerations beyond multi-tenancy support.
But let’s not digress. Let’s stick on the multi-tenancy requirements and how that drives architectural choices.
Let’s assume now that your small organization wants to standardize the application framework on Docker Swarm (and not on CloudFoundry). I appreciate this is not a like for like comparison (between Swarm and CloudFoundry) but for the sake of the discussion let’s assume that your organization decided to standardize everything on it.
Docker Swarm does not provide a native multi-tenancy experience (Docker Universal Control Plane provides some Role Based Access Control but let’s assume it’s not in scope). How do you go about it?
This is where the organizational requirements and the contracts between the various roles kick in and have a say in the technology stack layout. We know (because of our assumptions) that the organization isn’t very sophisticated: to map the roles required, a single level of multi-tenancy in the technology stack will be enough.
If you remember, at the beginning, we said that the organization in subject really needs to understand what it wants to achieve before committing to architectural and technology decisions. So what does the provider of this organization needs / want to offer to the consumer.
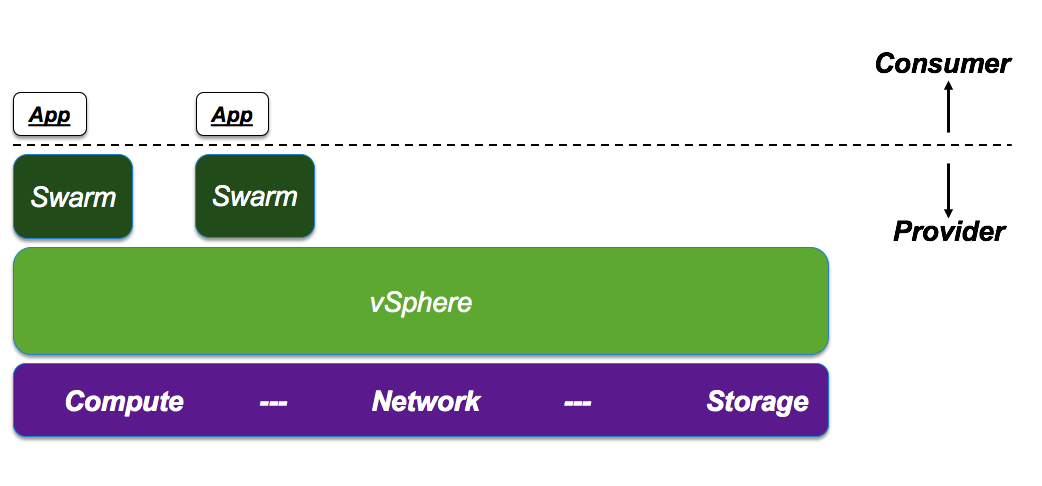
Scenario #1: If the service that the provider needs to build is of class “IaaS”, giving the consumer the responsibility to deploy the container management frameworks, then the architecture
Note in this case vSphere wouldn’t be a good fit because it doesn’t provide native IaaS multi-tenancy. However, having that said, if you really want/need to stick with vSphere and implement the same provider / consumer model, you have the option of moving the multi-tenancy / partitioning decoupling at a different layer with a different set of technologies.
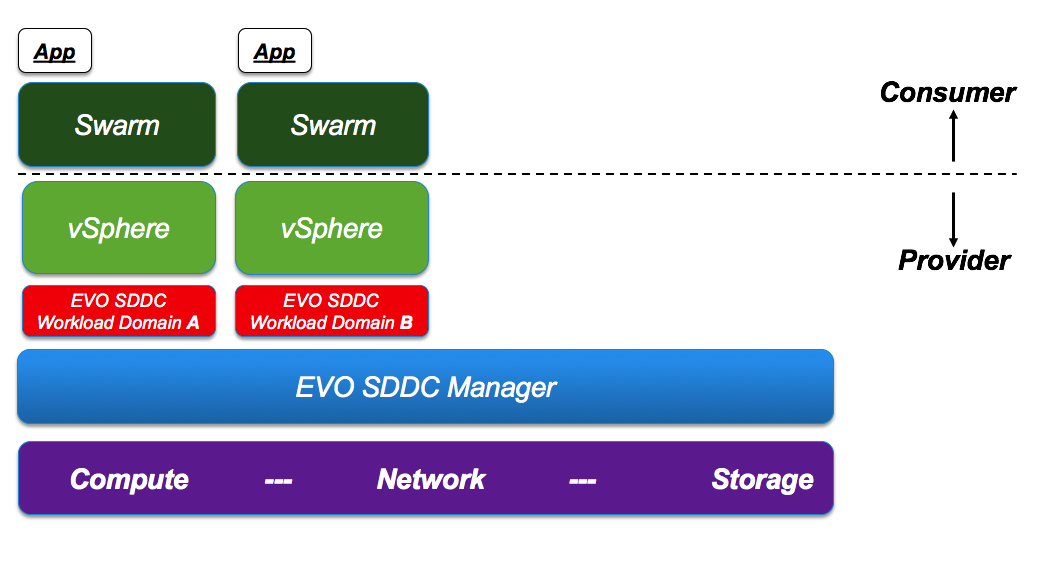
The solution below, using for example EVO SDDC Manager, would be “architecturally equivalent” to the above:
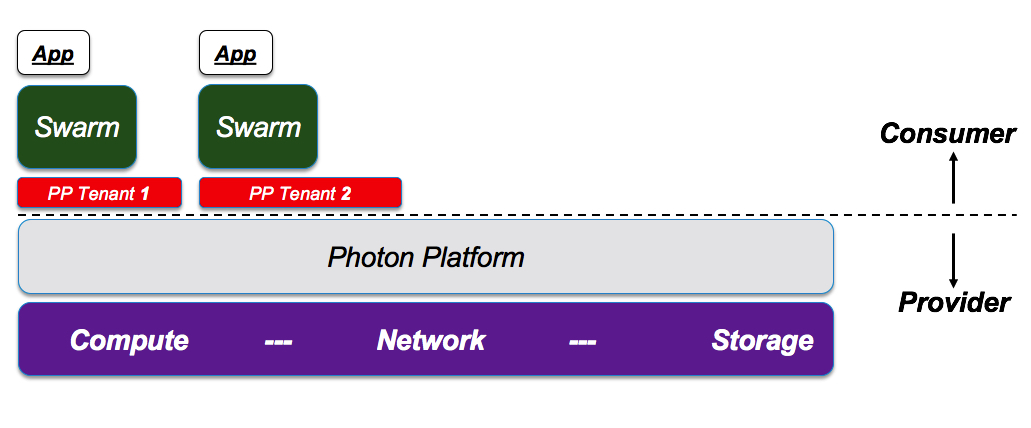
Scenario #2: If, on the other hand, the provider intends to build a service of class “CaaS” (new buzzword for “Container as a Service”) then they have the additional options of deploying the Swarm cluster on top of a non multi-tenant hypervisor:
This is (architecturally) possible because the provider will be managing the Swarm clusters and only the cluster end-points (along with the proper certificates) will be handed over to the proper consumers. So that only a specific consumer can access a specific cluster. You could even consider this sample script to be a rudimental, poor man’s CaaS if you will.
The fact that Docker Swarm does not support multi-tenancy makes it impracticable to run it directly on bare metal, especially if you have a relatively high number of tenants each consuming a relatively small amount of resources.
How does the picture change with public cloud resources?
Everything we have seen so far applies to data center deployments. Sticking with the scenario of a relatively small organization that has standardized on a given framework (e.g. CloudFoundry) the architectural view would be different because there is, by design, an additional multi-tenancy level required to access the public cloud.
Assuming the same organization model, with an (internal) provider of CloudFoundry services and (internal) consumers of said service, the layout may look like this:
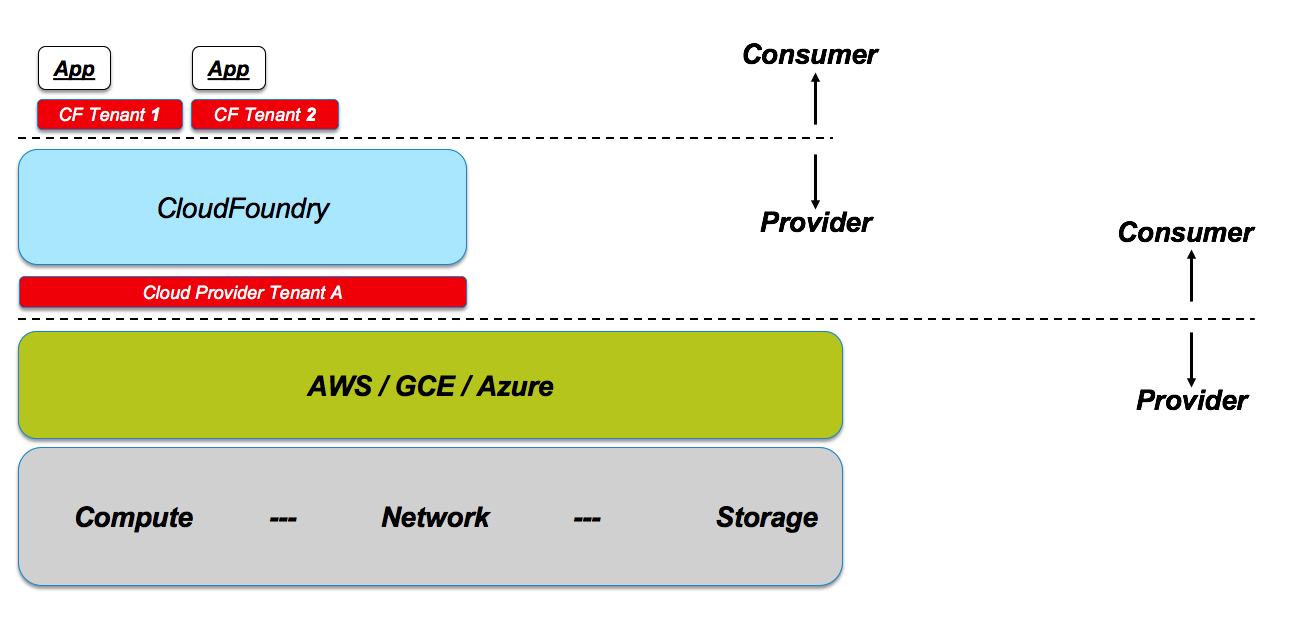
In this case you can think of this as a data center outsourcing where the organization’s provider doesn’t own data center hardware anymore but they are rather a tenant on one of the mega clouds.
This is where we see kicking in, again, the notion of multi-layer multi-tenancy (albeit this time across private and public entities). The organization provider becomes the consumer of mega clouds raw compute resources. At the same time the organization provider becomes the provider of PaaS services to the organization consumers.
Conclusions
In this blog post I focused the attention on design decisions around multi-tenant requirements and capabilities (or lack of thereof).
As your infrastructure grows and becomes more heterogeneous, complex and broad, you need more sophisticated multi-tenancy and workloads isolation (like the one EVO SDDC provides). However, you need to find the right balance between too much multi-tenancy (which may drive complexity) and too little multi-tenancy (which may drive poor operational flexibility).
As we alluded multiple times, multi-tenancy is just one of the many considerations to take into account when architecting a proper solution.
Take, for example, Kubernetes (or Mesos for that matter). Regardless of current RBAC capabilities (that may or may not satisfy your multi-tenancy requirements) there could be many other (operational) reasons for which you could deploy a single gigantic Kubernetes cluster or many smaller Kubernetes clusters.
What’s the scope of a Kubernetes cluster in your own environment? Is it company-wide? Is it BU-wide? Is it team-wide? Is it project-wide? The answer to this question (and many others) will dictate how many “decoupling points” you need to have in your stack.
The above assumes Kubernetes was the strategic and unique choice at your company. If different independent teams have elected different orchestration technologies, you are then forced to partition your infrastructure to start with.
As a final note, other abstractions exists above the end-points we discussed here. If you pile on top additional functionalities (like CI/CD pipeline orchestration tools) other possibilities open up in terms of abstractions and multi-tenancy (as we described it).
Massimo.
P.S. I’d like to thank my super smart colleagues T. Sridhar and Michael Gasch for their patient in reviewing this and for the constructive feedbacks (when they could have just gone“Massimo, WTF are you talking about?”). Thanks.