AWS: a Space Shuttle to Go Shopping?
I apologize for the catchy title (I need to drive clicks, somehow). The title of this blog post should have been "considerations on some interesting AWS (Amazon Web Services) usage data I came across". Not very catchy.
A few weeks ago I saw a study done by The Big Data Group re the above. I found this extremely interesting. I am not sure how much this analysis is representative of the total AWS usage but it does cover 250.000 instances which is roughly one quarter of the total instances running on AWS, rumors say. For others, 250.000 instances could be as much as half of the entire AWS cloud. All in all, I thought this analysis from The Big Data Group must be somewhat realistic.
When I think about AWS I usually think about:
- Cloud != Virtualization
- PAYG (aka PayGo)
- Resources Consumption Optimization
- "Infinite" Scalability and Elasticity
Among other things.
As I read through that analysis, it sort of dismantled a lot of myths I had about Amazon Web Services (usage patterns). Let's go through them.
Cloud != Virtualization
This is a common theme. A lot of people claim compute virtualization (i.e. virtual machines) playing just a niche role in what a (IaaS) cloud delivers. I can't disagree but it is interesting to notice that...
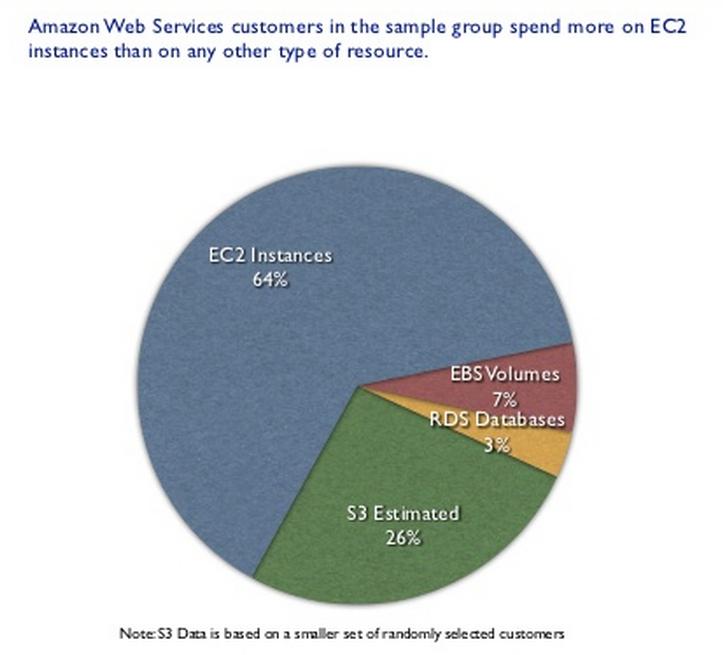
64% of all dollars spent on AWS are for virtual machines instances (with 7% on EBS which you may or may not see as part of the instance).
26% on another awesome and very successful AWS service (S3). Interestingly the remaining 3% (peanuts) for RDS makes it the total 100% spending. Not sure what that means. Are all the other 20+ services generating negligible revenue? Weird. If true, so much for "cloud is not virtualization".
Pay As You Go (PAYG or PayGo)
Another huge value of AWS, no doubt. And that's why I was floored when I read that...
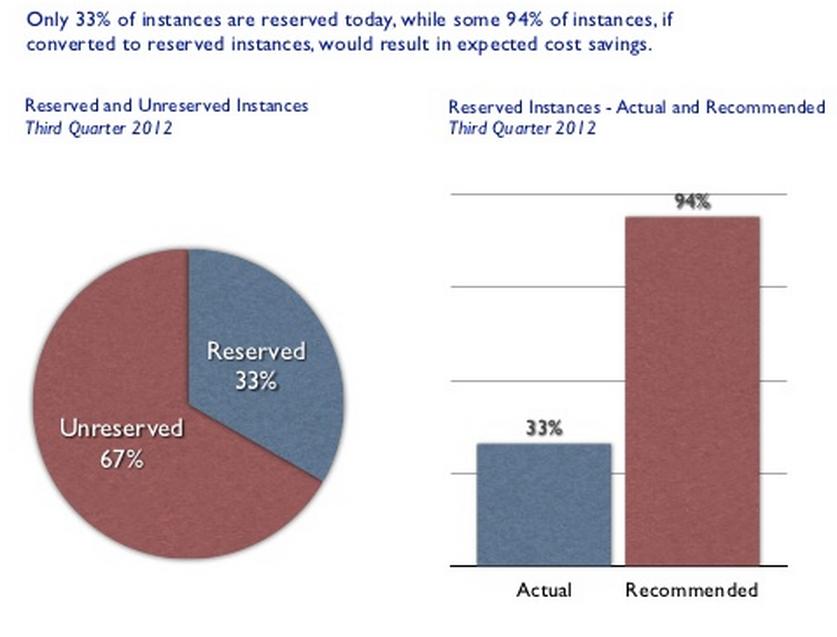
I guess people are realizing that, if you use these stuff 24/7/365 (in other words not for development), your costs are going up to the roof in a true PAYG pricing framework. 94% of those 250.000 instances should have been reserved to save money. Wow. So much for "pay for only what you use and forget about planning".
Resource Consumption Optimization
This is (or should be) a direct consequence of the above (PAYG). I was puzzled to read that...
"Many instances are underutilized. Significant storage goes unattached". (slide #4 of The Big Data Group analysis).
And again...
"Medium instances are only about 12% utilized while small instances are just under 17% utilized" (slide #9 of The Big Data Group analysis)
Wow. Did you say cloud? This sounds like IT pre-virtualization. You remember all those "your physical servers are only used 10% on average so you should virtualize them". So much for "resources consumption optimization in the cloud".
"Infinite" Scalability and Elasticity
I have once heard Adrian Cockroft defining cloud scalability as being able to instantiate 1000 VMs with 64GBs of memory in one operation. No one can beat Amazon here. Period.
Having that said, how popular and pervasive is this requirement? I found pretty interesting to read the break down of those 250 organizations in the analysis and how they are segmented in terms of instances deployed...
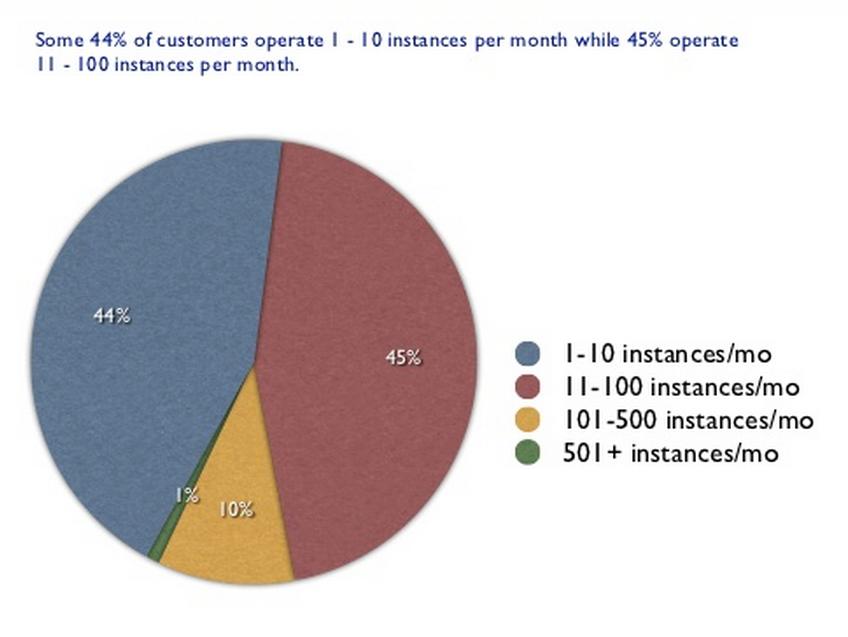
By Adrian's metric, only 1% of Amazon users should really care about cloud scalability and elasticity. Even assuming that all these customers need to deploy those instances in one click (yeah sure), 44% of them will only need up to 10 per month and 89% of them only need below 100 per month. I will make a bold statement and I'll say 9 customers out of 10 are consuming peanuts in the cloud. So much for "cloud is all about infinite scaling".
My Interpretation of the above (your mileage may vary)
- There are a lot of users that are using AWS as an off-premise traditional virtual infrastructure to spin up (few) VMs.
- Unknown to me whether the above is because doing so through IT is slow (consumers = non-IT People) or because they have chosen to extend (or not to have) local IT (consumers = traditional IT people).
- Consumers go to AWS because it's easy to start a VM, not because AWS has 30+ additional services they can leverage. Surely some do but the bulk doesn't seem to.
- Infinite cloud scalability is an interesting academic topic. The clouderati could spend a week-end discussing this on Twitter. However this topic is irrelevant for some 99.x % of real customers out there.
- 250.000 instances consumed by 250 organization 89% of which run between 1 and 100 instances: can't bother to do the math to find the formula right now but my instinct says that there are (very) few of those 250 organizations (amazon.com, Netflix, etc) consuming an insane portion of the AWS cloud while the majority of the other customers are consuming "peanuts".
- (Warning: bold / stretched statement coming) From the above perspective, AWS sounds more like a colo outsourced "virtualized datacenter" for a handful of big organizations and with thousands of small customers consuming "the remaining".
- (Warning: speculation not backed by data coming) Big customers are probably using all the AWS services richness and are designing applications properly for AWS. The remaining of the customers (majority) seems to be spinning up a few instances (it's so easy) and praying for the best.
And this leads me to the tedious design-for-fail discussion. I am not going to bore you with this one again, no worries. This concept ties back to the Pets and Cattle concept (AWS implements a cloud model that is suited for cattle).
The only question I have after reading this analysis (assuming it is representative of real usage) is... do traditional Enterprise customers and SMBs approaching and consuming AWS know what they are doing? How many of these situations do we have out there? Back to the title of this post: you can indeed use a space shuttle to go shopping if you want to, however it is important that you know how to drive and park it downtown.
On a more serious note and question, how many of these "remaining" customers are using AWS because "it's scalable, elastic, PayGo, optimized"... and how many are using AWS because "oh, is there anything else?!?"?
I am really just wondering.
Massimo.