Storage High Availability and DR for the masses
Virtualization is a disruptive technology and we all know that. With this post I want to share with you some scenarios about how server (and storage) virtualization can drastically change the landscape for "small IT shops" (aka SMB's) in the context of High-Availability and Disaster/Recovery. Up until today server "high availability" was not for everyone as it required a complexity and a cost that many IT shops could not sustain. I have already been talking about the change of paradigm that a virtual infrastructure brings in when it comes to make a service highly available. You can read this post for more info.
However that covers a small portion of the bigger picture. Particularly that post assumes that you have a number of physical servers connecting to a central storage repository so that you can restart your VM (i.e. your service) should one physical server fail. Fair enough but this obviously doesn't cover the other important subsystem which is the storage subsystem. In a scenario like this the central storage repository is a so called SPOF (or Single Point Of Failure). If you are a big Bank / Telco organization (or if you have enough money to spend anyway) you can get something decent using Midrange / Enterprise Storage arrays that support all sort of replication features so that you can literally create a fully redundant infrastructure with no SPOF. It must be noticed that while it is true that even Entry level Storage arrays might have no internal SPOF it is common referring to these boxes as a single entity (hence a potential single source of issues). This is even more evident when you think about being able to stretch your virtual infrastructure across two buildings in the same Metropolitan Area Network (such as 3 physical servers in Building A and 3 physical servers in Building B comprising a single cluster): this obviously leaves you with the only choice of putting your single Storage array in either Building A or Building B.
I don't want to get into all sort of discussions regarding how you would define a scenario like this. Someone refers to this as "DR", someone else refers to this as "Campus HA", someone else refers to this as "Continuous Availability". I am actually not interested in formal definitions. I am more interested in the fact that the vast majority of the customers I talk to (be them big Banks, big Telco's or the small SMB IT departments) would like to leverage virtualization technologies to be able to achieve this scenario in a much less complex way (typically a requirement of the big boys that have a very complex distributed IT infrastructure) or in a much less expensive way (typically a requirement of the not-so-big boys that have a tight budget). It is amazing to hear that one of the most appealing reasons for which all customers are virtualizing ... is not for consolidating the servers (sure this is important) but to provide better high availability and DR mechanisms. Virtualization is really a paradigm shift.
I have already said that for the bigs there are (expensive) technologies and products that allow you to achieve that. This is an example of a project I have been working on a few years ago. But where does this leave the "small" shops? I am talking about customers that have from 10 to 15 Windows / Linux servers and that do not have a budget that allows them to intercept Midrange Storage technologies with replication capabilities. These arrays are not enormously expensive (in fact I am assuming that who has more than 15 or 20 servers perhaps has a decent IT budget that allows them to buy these technologies). However IT departments that have up to 10 or 15 virtual instances which, by the way, could be deployed on as few as two 2-socket systems (for redundancy) based on these other assumptions I discussed in a previous post.... might not be keen on buying a Midrange Storage array just for the purpose of being able to replicate and protect the data. Don't get me wrong, the "geeks" working for IT would love to have that kit in their hands, it's the "buyer" within the organization that would question the value for the money.
That's why when I was first introduced to technologies such as those from Lefthand Networks and then Datacore I was intrigued. What these companies do in essence is storage virtualization. They do it differently and the product packaging itself is not identical but essentially, bottom line, they hide the layout of the storage arrays and the way it is presented to the hosts and their OS'es. As I said they have a different approach in how they achieve this.
Lefthand Networks sells SAN "building blocks" that are effectively x86 servers with their own software on-board. This software simply turns those network-connected x86 servers equipped with a certain amount of Direct Access Storage into a highly available and distributed SAN that the computational hosts and their OS'es can access via an iSCSI protocol.
Datacore uses a slightly different philosophy as it is sold as a software package that you would install on a Windows host (typically more Windows hosts for redundancy and high availability reasons). Storage administrators would then give visibility of heterogeneous and distributed storage resources to these hosts, typically via FC but not limited to that, so that the Datacore software could present, using various protocols such as iSCSI and FC, to the hosts and their OS'es, a virtual storage repository.
These two pictures should clarify this brief explanation of the two technologies.
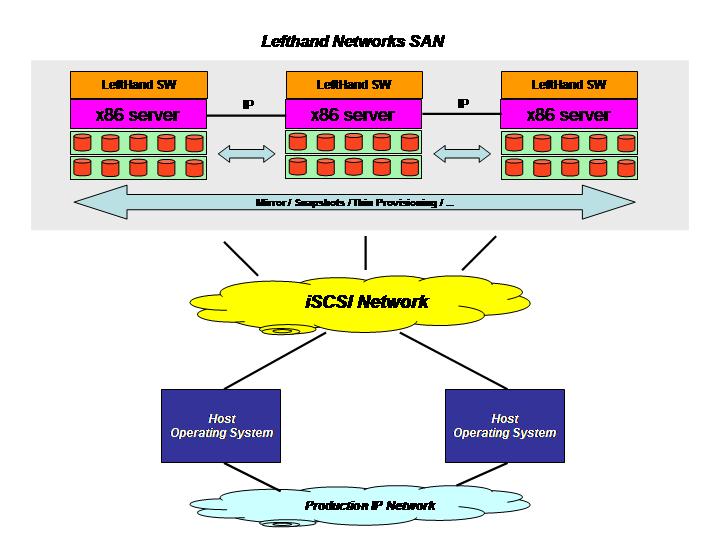
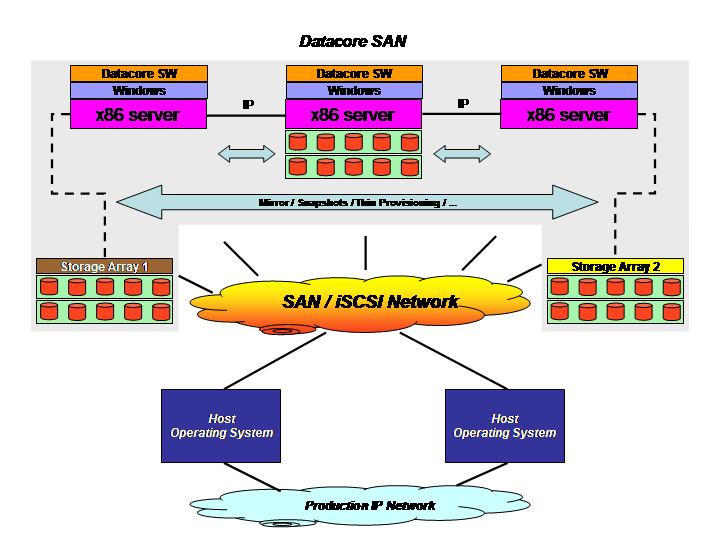
Obviously this is not intended to be an exhaustive explanation of these vendors' technologies, features and strategies. Make sure you contact them directly should you be interested in knowing more about this.
In a typical scenario as the one I have outlined in the pictures above, separated physical "storage islands" would be aggregated into a single virtual SAN by the Lefthand/Datacore software that in turns provide a robust storage repository to (yet) other physical hosts running your production applications. That is how these products are usually positioned. How all this ties into the HA and DR for the masses I was referring to? Well it turned out that it is possible (and this is how both companies are now marketing their products as well) to install the software logic within virtual machines. Imagine a new innovative deployment scenario where you would create two special purpose virtual machines on two separate virtualized hosts and each virtual machine is associated with a vast amount of locally attached storage. At that point the Lefthand/Datacore software would turn those two VM's (with a bulk of local storage space associated to them) into your virtual SAN that is going to serve, through the iSCSI protocol, the other virtual machines (supporting your own production applications) running on the same two virtualized hosts. Confused? I think a picture is worth 1000 words.
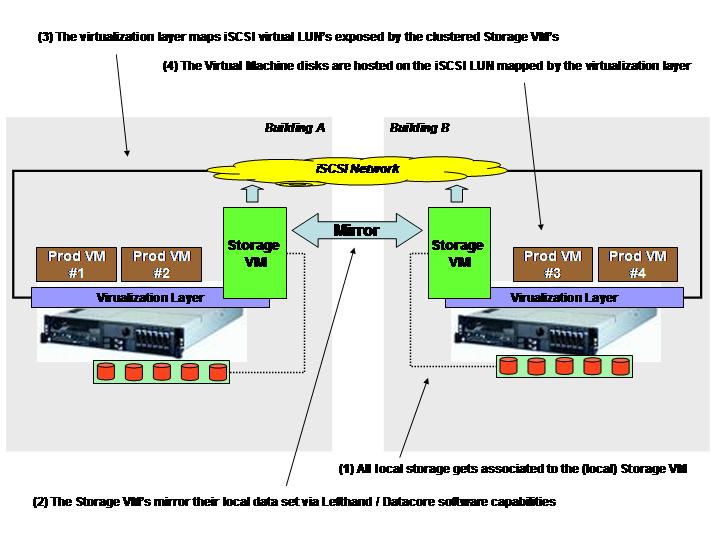
On top of all the functionalities that these software provide the most interesting, in the context of this post, is the ability to mirror the local content of the Storage VM's in order to create an active/active fully redundant iSCSI SAN. As you can depict from the picture above the logical layout is quite different from the physical layout. Let me try to explain: logically the two Storage VM's create the virtual iSCSI SAN. The virtualization layer then maps the LUN's made available by the clustered Storage VM's and use these LUN's to create VMFS volumes to host the production virtual machines to support the business. The logical perspective differs from the physical perspective in the sense that, while logically the virtualization layers connect to an "external" iSCSI SAN and use it as an external service... the actual code that instantiates the virtual iSCSI SAN runs as redundant stand-alone virtual machines on top of the same virtualization layers.
One of the key advantages of such a setup is being able to tolerate the failure of one of the two systems and continue to be able to operate. The following pictures illustrates what happens should either one of the server or an entire building go off-line for some reason.
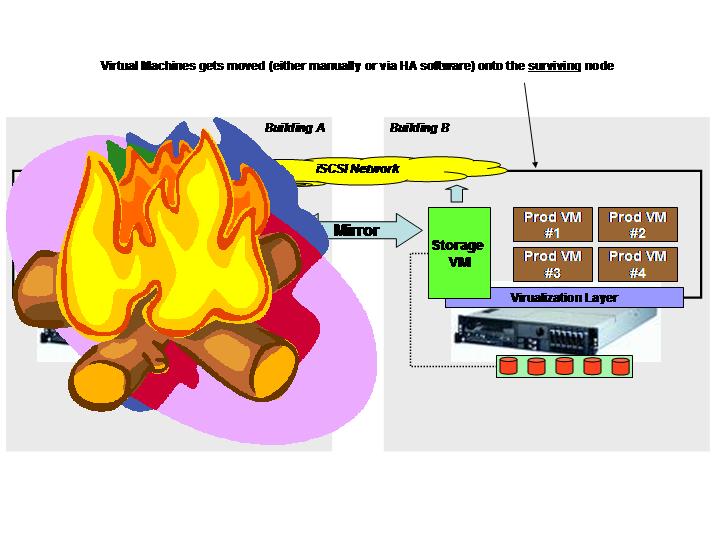
Since the Storage VM's replicate the local storage associated to them, either one of these entities can fail (be it the Storage VM itself, the virtualization layer, the physical server or the entire building) without affecting the availability of the VMFS volumes created on top of the mirror. This is transparent to the surviving virtualization layer as it could be compared to a failure of a Storage Controller within a redundant FC Storage Server. It is worth noticing that, in case of failure of the physical hosts or failure of the building, VM's can be either manually or automatically restarted on the surviving node depending on the virtualization layer being used and the feature set associated to it.
I am not getting into the details but consider that both these software support Synchronous and Asynchronous replication of the data so that you can even tune your solution based on the distance of the two buildings. In the simplest scenario both buildings are in the same Metropolitan Area Network so you would treat the two servers as if they were installed in the same rack of a single building. On the other hand if your buildings are far apart (or otherwise not LAN-like connected) you can tune it to use Asynchronous replication and build something that is closer to a Disaster/Recovery plan (well I am oversimplifying here but you get the point).
It is also worth noticing that since the Datacore software is an add-on that you (the customer or the integrator) would install on top of Windows, you can use any virtualization layer that allows you to create Microsoft Windows virtual machines making it very flexible in terms of deployment options. Lefthand on the other hand provides the Storage VM as a virtual appliance (thus making it more robust and easy to deploy in my opinion than a Windows add-on like Datacore) that is however, as of today at least, only available for VMware VI3 virtualized platforms.
This is clearly not something that you might want to look at in the context of a medim / big virtual infrastructure deployment where Midrange / Enterprise Storage arrays with their native virtualization and replication techniques offer a great deal in terms of performance, scalability and reliability. I don't want to downplay Lefthand and Datacore but I think there is a positioning that needs to be taken into account when comparing these products with Midrange / Enterprise class Storage arrays features. But in the context of the small IT shops, using the technologies described in this post you can achieve similar features at a small fraction of the costs and it might make sense doing so.
Let's try to do the math. A couple of System x 3650 configured with 2 x Intel Quad-Core processors, 16GB of RAM, "a bunch" of local disks and network adapters might cost around 10.000$ each (list price). This makes a 20.000$ total (list price) for the hardware.
I am not an expert on Lefthand and Datacore pricing (nor I want to become one) but as far as I have seen it would be fair to assume that, in a context and scope like this, the software to enable each Storage VM would cost around 5.000$ (list price). This makes a total of 10.000$ for the virtual SAN with remote replication capabilities.
Then it comes the virtualization layer. Here there are a number of options (both from a vendor perspective as well as from a feature set perspective within the same vendor). Clearly if you want to use MS technologies to enable the virtual infrastructure solution (i.e. Hyper-V with Systems Center Virtual Machine Manager) the cost would be pretty low. On the other hand if you want to use VI3 Enterprise to enable it the costs would be higher (so would be the feature set). Obviously one should also take into account lower costs VMware VI3 alternatives (such as VMware VI3 Foundation) as well as alternative virtualization vendors such as Citrix and VirtualIron. All in all I think it would be fair to assume that one could spend, on average, 5.000$ to enable both physical systems with a virtual infrastructure software (again it might be as low as 0$ or as high as 10.000+$ depending on what you want to achieve).
All numbers we have mentioned (and assumed) are list prices and I will let you do the math on the average discounts you can achieve on each of those items (for example I know Lefthand has some bundle offerings that lower considerably the price). In general it would be fair to assume that, for a "low 2 digit thousands of US dollars" (what a great way to not tell you what I think a potential discount could be) you can get the following:
- A physical Server and Storage infrastructure capable of supporting up to 10 or 15 virtual images
- Integrated Server and Storage high availability and redundancy
- Compatible with all server virtualization enterprise features (live partition mobility / high availability for virtual machines / etc)
- Without the costs associated to a SAN environment
- With acceptable performance and good-enough scalability (in the context of small IT shops)
All this at a fraction of the costs compared to achieving similar characteristics using high end Enterprise class components and products. As I said this is not meant to be for everyone; Midrange / Enterprise Storage Server arrays should continue to be intended as the preferred choice for High Availability and Disaster/Recovery scenarios in many circumstances. This is however a great way for customers with limited budgets to achieve similar levels of features at a fraction of the price. This is not about cannibalizing the Midrange and Enterprise products market, but it is rather making similar level of features available to the masses (masses that would not be able to get the same features otherwise).
In closing this thread I'd like also to point out that virtualization is not, as many still think, (just) the capability to carve a number of software partitions out of a single physical system (aka server consolidation). Virtualization is really a paradigm shift within the data center that allows to re-architect the entire stack (hardware, software, management) in a completely different (and better) way. It allows customers and vendors to look at the typical problems from a completely different angle, thinking out-of-the-box if you will. It allows to solve problems in a way that a few years ago one could not even think it would have been possible.
Massimo.