VMware Distributed Storage – This is Where the (Cloud) World Collapses
At VMworld 2012 VMware showed something dubbed Distributed Storage. If you were in SF and you missed it, I strongly suggest you watch the recording of session INF-STO2192. The demo in particular is very cool.
I am very excited about this for a number of reasons. This post isn't going to talk specifically about the VMware Distributed Storage technology. It is rather going to talk about the philosophy behind it and the trends in the industry.
Background
A few days ago I posted an article on the evolution of x86 server architectures. Towards the end I hinted on what's happening in the storage space. I didn't double click on that there and I am not going to be exhaustive here either but let's try to point out the three major milestones I have seen in the last 10 years in this arena. They are:
-
Monolithic Storage Servers
-
Modular Storage Servers
-
Virtual Storage Appliances
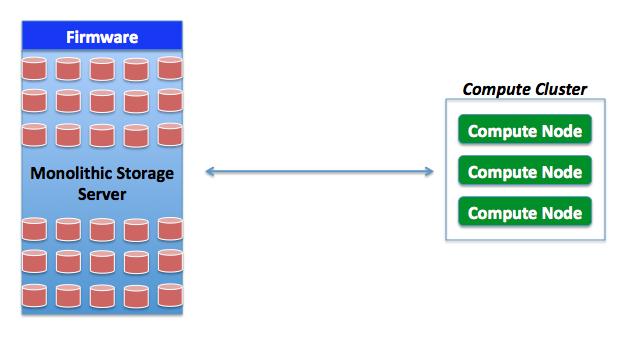
Model #1 (Monolithic Storage Servers)
This is usually built on proprietary platforms and the value is typically delivered by a mix of highly redundant monolithic hardware and low level software (often referred to as firmware). This typically only scales up. Example of this model includes, but are not limited to, products like the IBM DS8000 and the HP XP12000. A simple diagram of this model is below.
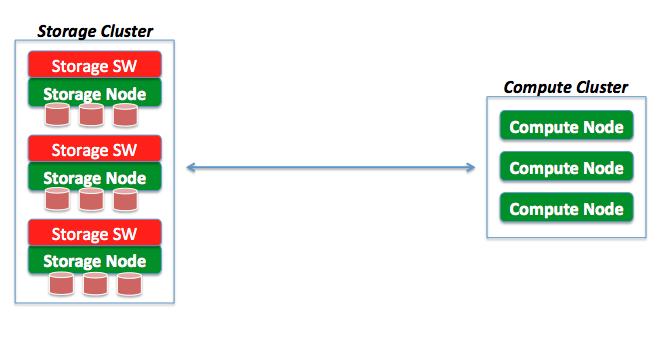
Model #2 (Modular Storage Servers)
This is usually built on x86 industry standard servers with internal hard disk drives (aka DAS - Direct Attached Storage) and the value is typically delivered by software (often Linux based) running on those servers. Examples of this model include, but are not limited to, products like HP Lefthand and Dell Equallogic. Again, a simple diagram of this model is below.
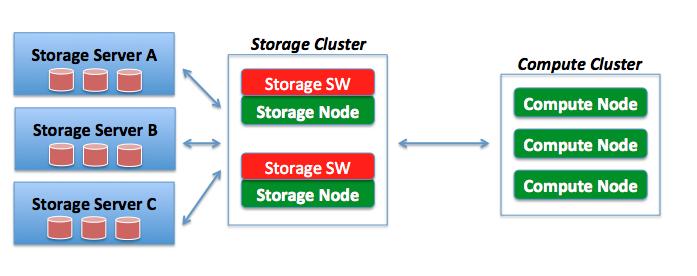
Note: I consider the so called storage virtualization solutions such as Datacore SanSymphony-V and the IBM SVC to fall into this category: they are typically software-value driven but they implement a 2-tier architecture where the software doesn't run directly on the hosts with the disks. However they are still usually implemented as a dedicated storage subsystem separated from the compute fabric. The diagram below depicts this deployment variant in model #2.
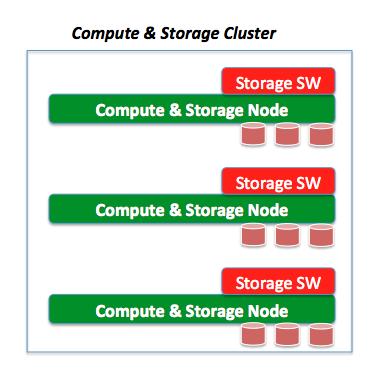
Model #3 (Virtual Storage Appliances)
This model is nothing more than the repackaging of the software mentioned above in a virtual appliance format and deployed on the fabric compute nodes consuming local hard disk drives installed there. In a way this is like collapsing the Storage and Compute layers of the data center. Examples of this model include, but are not limited to, products like the HP Leftehand Virtual SAN Appliance and VMware VSA. This is the first form of collapsing if you will, but not what's implied in the title of this article.
State of the Art in 2012
Note that what you see in model #3 isn't really anything new. I wrote about it not less than four years ago in a blog post titled Storage High Availability and DR for the masses. You may say that in 4 years this didn't get mainstream and I won't argue with you. That's a fact. It's fair to say that deployments like these are the exception and not the norm. Some of the major reasons, in my opinion, include this:
Conflict of interests. Some of the vendors offering virtual storage appliances usually sell traditional storage as well. Sometimes there is a conflict of interest where the vendor fears they could make less money with model #3 rather than continuing to push the traditional models #1 or #2. But more often it's probably laziness and inertia. People (and vendors) in the field sell, architect and implement the things that they know. I haven't seen a single (major) vendor stepping up and try to change the status-quo. Many of them have solutions that fall into the model #3 more as a "me too" rather than a serious innovation weapon.
Operational issues. Collapsing the storage and compute layers can't just be a consolidated diagram in a PowerPoint slide. Operationally speaking, even with the products implementing model #3, these were still two separate realms (storage and compute). You'd connect to the very same setup, configuration and monitoring interfaces used for models #1 and #2. For deployments per model #3 it just happens that the IP address you connect to (to administer your storage subsystem) is a VM running on the ESX host rather than a dedicated storage server or storage cluster (as in models #1 and #2). As a result, the benefits of model #3 were not fully exploited.
New Trends in the Cloud Industry. And this is where things become interesting. Four years ago the real thinking behind that blog post was that traditional storage was a given and this new model #3 could really help in specific use cases. Four years later the industry is telling us that DAS (along with some software magic - more on this later) isn't so much about solving particular use cases. In the long run it is becoming pervasive and the norm in any infrastructure deployment.
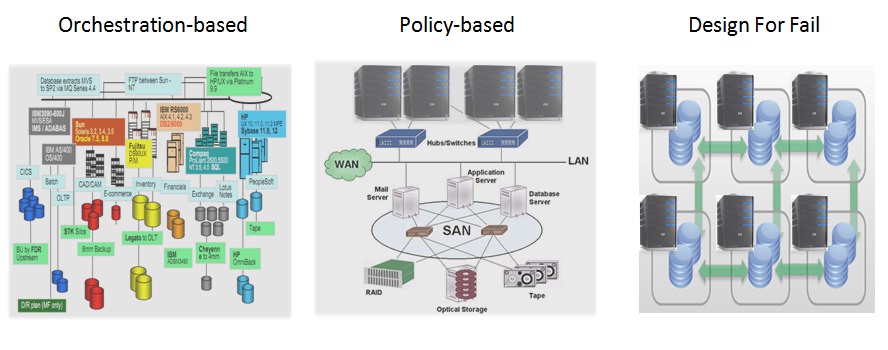
This isn't happening overnight, obviously, but a trend is a trend. I have been talking about this in my Magic Rectangle blog post and if I have to pick up a single characteristic among the many of what differentiatates a Policy Based Cloud (for lack of a better name) from a Design for Fail Cloud (ditto) that would be: Enterprise Shared Storage Vs DAS. The images and diagrams I have chosen in that article to describe the different models speak for itself:
VMware Distributed Storage is, in my opinion at least, well positioned to overcome the roadblocks I have mentioned above that have slowed the adoption of model #3 towards the trend. I would like to point out that this isn't about introducing a new storage platform in your organization. This is rather trying to make storage, and its associated problems, disappear. At least for the vSphere based infrastructure.
Also consider that VMware Distributed Storage has some very interesting implementation details that may make it very unique and appealing (e.g. low level VMkernel implementation, storage policy based management fully integrated into the vSphere stack, etc). Discussing those implementation details is beyond the scope of this blog post but you can find some nuggets in this post from Duncan Epping.
The Collapse of the Policy Based Clouds and the Design for Fail Clouds
And this is where I (really) wanted to get to. The part that really excites me more about model #3 (and particularly about VMware Distributed Storage) is the fact that it's the bridge between the two cloud types I discussed in the Magic Rectangle blog post: the Policy Based Cloud and the Design for Fail Cloud.
Many of us agree that, in the future, DAS can really become a pervasive alternative to enterprise storage even in traditional datacenters. Yes it is already heavily used today for particular use cases but I wouldn't call it mainstream to be honest. Oh and when I say "in the future" I don't mean "Tuesday next week", I am thinking something like 3+ years. Traditional storage vendors fear not.
This is what I have in my head:
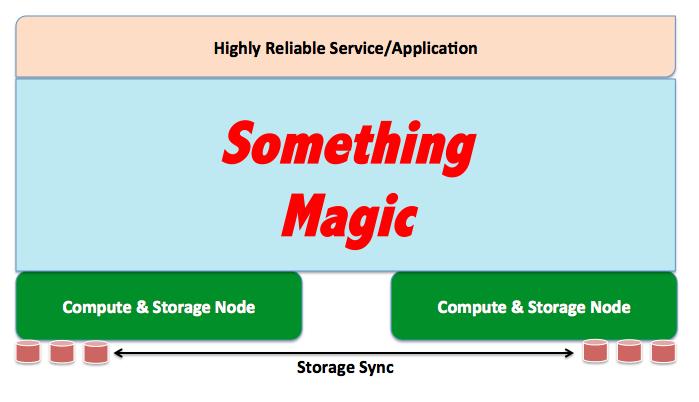
We all agree that at the bottom we have commodity hardware pieces that runs application workloads and that happens to host the storage subsystem as well. At the top of the stack a service or an application is deployed and, somehow, high availability is guaranteed (or should be guaranteed).
It's the Something Magic part of the stack that I'd like to expand a bit on now. The Policy Based Cloud and the Design for Fail Cloud have completely different phylosophies around how to implement that magic part of the stack.
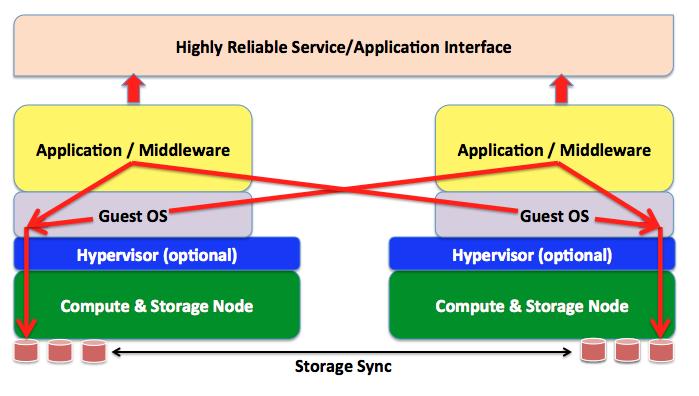
In the Design for Fail model the high availability of the application as well as the data syncronization is demanded to the middleware / application itself. There is no infrastructure related magic in all this. It's the application (and / or the middleware it runs on that enables this). The picture below is a simplistic representation of this concept.
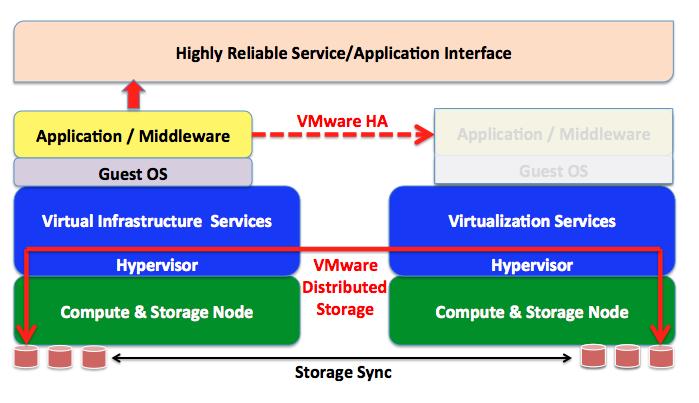
In the Policy Based (also referred to as Enterprise) Cloud model the high availability and data syncronization features are demanded to the infrastructure software. In the example below I am calling out VMware HA and VMware Distributed Storage but you can really think of any other HA or Virtual Storage Appliance solutions. In this scenario the application doesn't have to be aware of what's going around it.
Things start to become more interesting when you think about these scenarios at geo scale (rather than inside the datacenter).
In the Design for Fail approach the architecture doesn't change vastly as it's really about the application / middleware leveraging this distributed model regardless of where workloads are deployed. If interest in the concept of data spanning the globe you may found this webcast recording on a particular SQLFire use case to be very interesting. The picture below is very similar to the original Design for Fail architecture but at geo scale:
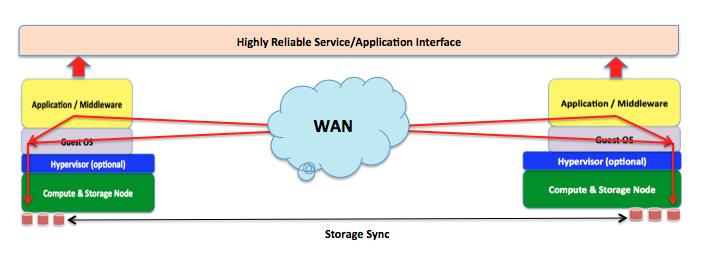
For Policy Based Clouds the implementation may vary as VMware Distributed Storage (and similar technologies in the model #3 discussed above) are more suitable to local datacenter deployments as an alternative to traditional SAN deployments. For geo replication a different set of software tools may be required.
For example VMware vSphere Replication (or any 3rd party technologies that allow VMDK replication across a WAN link. This could (and should) be complemented with automated tools for complete end-to-end DR (such as VMware SRM). Again, the application(s) deployed in this context don't need to be aware of all the replication and resiliency mechanisms implemented at the infrastructure layer.
The picture below represents a generic overview of this setup. In this example VMware Distributed Storage is used to protect local disks in the datacenter and expose them as a virtual storage area network, whereas VMware vSphere Replication is used to replicate the VMDK files in a remote datacenter via IP connectivity.
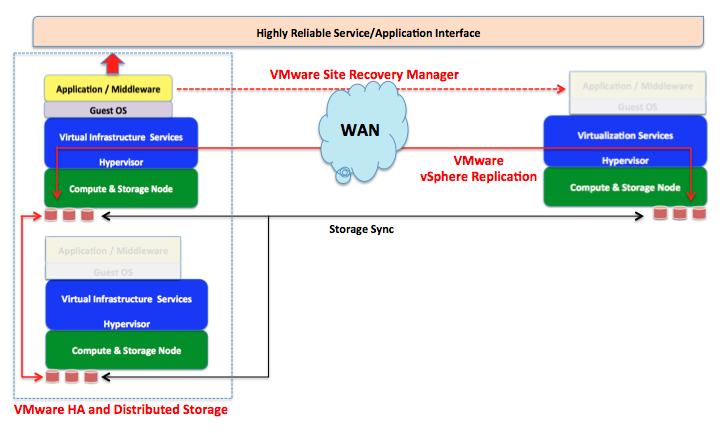
Note that I am using product names that I am more familiar with (e.g. vSphere Replication and SRM), but my ask to you is to focus on the philosophy rather than the product implementation.
This post isn't intended to be a comparison between the Policy Based Cloud Vs. the Design for Fail Cloud approaches. The Design for Fail approach is ultimately a much better way to deal with scale, elasticity and resiliency at geo distances (more information in the webcast I mentioned above). The downside of it is that it requries specific middleware and application awareness.
In contrast, the Policy Based Cloud approach is transparent to the Guest OS and doesn't require any awareness at the application layer. The downside is that that it doesn't address things like "near" real-time data replication (or transaction-based replication), horizontal scaling and application transaction granularity.
Conclusion
What I covered in this blog post is very broad but the ultimate point I am trying to make is that there is a shift from hardware-delivered value to software-delivered value (also referred to as Software Defined Datacenter).
In particular there is a shift between hardware based appliances that serve a particular (vertical) purpose inside the datacenter towards a common shared x86 infrastructure that runs all datacenter services including storage, network, security and, obviously, applications. This is where VMware Distributed Storage comes in: it represents the collapse of storage services on the converging x86 fabric.
Last but not least VMware Distributed Storage (along with other storage services such as vSphere Replication) is the mean by wich a common shared x86 fabric with Direct Attached Storage can be used for both legacy and brand-new workloads. That is the collapse of the Policy Based Cloud and the Design for Fail Cloud onto a common shared hardware x86 infrastructure. The hardware infrastructure is as simple as possible, with DAS storage and a simple but yet robust layer3 communication mechanism. On top of this infrastructure (storage, networks, etc) and application services can be created and deployed with a click of a mouse.
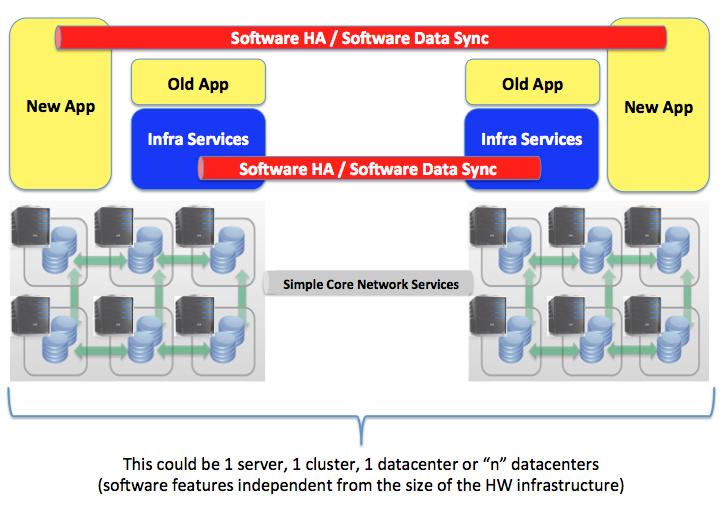
Note: in the diagram above new applications are implied to run on bare metal infrastructure. More realistically there will be a thin layer of virtual infrastructure services that will enable a better provisioning mechanism for those instances. They will however not use all of the advanced virtual infrastructure features that old applications may require.
This is where the cloud collapses: one infrastructure to rule them all!
Massimo.
Update (September 11th): The CTO office published a couple of interesting blog posts on the topic you may want to read: A preview of DistributedStorage and Storage Directions for the Software-DefinedDatacenter.