Specs, intent and the source of truth
The world is changing. Fast. I have been working in the generative AI coding tool space for about 3 years now. And it feels 70. I often joke about the fact that one year in generative AI is like three dog years and twenty-nine EC2 years. So, that checks out.
A couple of months ago, I have participated in a series of events (public and private) where I talked about my experience in these last 3 years and where I see this industry going. In this blog post, I want to explore something that is close to my heart which is the concept of "source of truth".
Before we get there, and for context, I'd like to point out the speed at which the space of coding assisting technologies has evolved over time and the acceleration it took as of late. Developers started their journey in the early days using simple editors that evolved into more powerful IDEs over time. These were eventually equipped with linters and autocomplete capabilities. Roughly 3 years ago we have started to see generative AI assistance in the form of inline suggestions capabilities (also known as autocomplete on steroids, as I call them). This is around the time when ChatGPT first came out and that changed radically the experience of this assistance for development tasks. For example, we have seen, in a very short period, the exponential value developers have started to capture inside their IDEs with integrated Questions and Answers (QA) chat capabilities that soon enabled rapid prototyping via vibe coding techniques with a more "agentic chat". Vibe coding is still cool to date for rapid prototyping but perceived by most people as too unstructured for production usage. This is why a new technique called "specs-driven development" (specs stands for specifications) has become SOTA (State Of The Art) as of today for structured generative AI assisted programming. Specs-driven development is a technique for building software with generative AI assistants (like Kiro) that leverages the description (or specification!) of what the software should be doing and how software should behave.
The diagram below offers a visual interpretation of this rapid evolution.
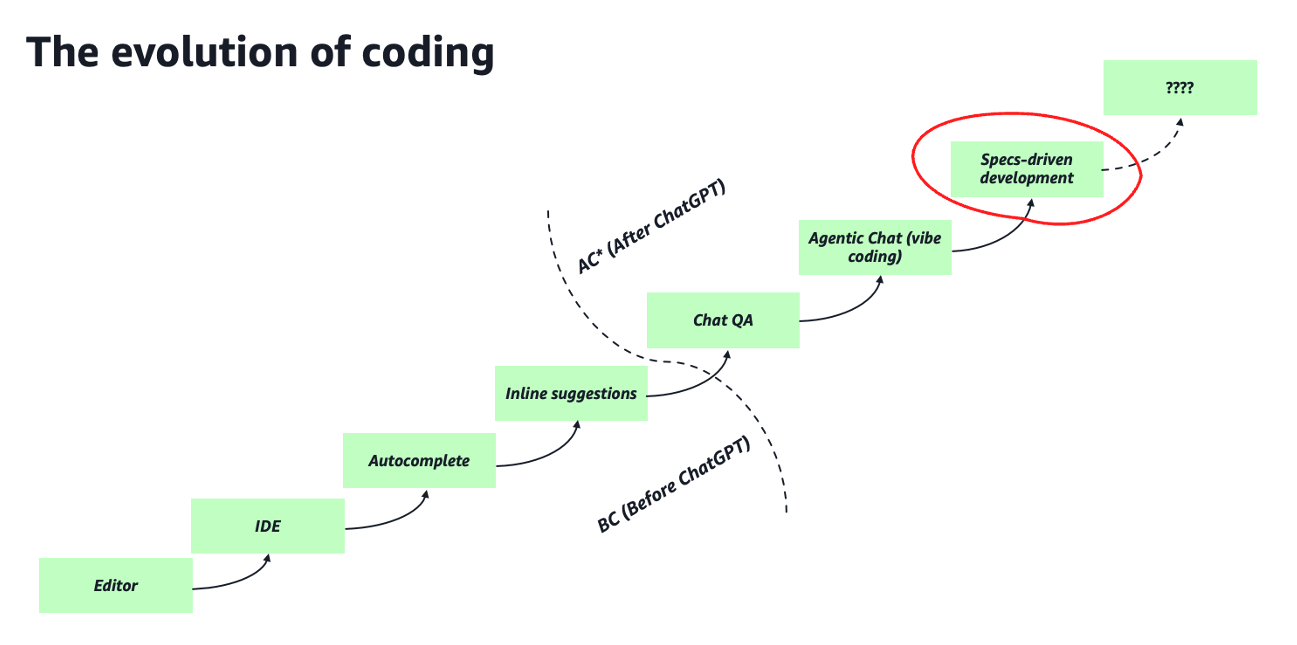
I will not spend much time to introduce vibe coding and specs-driven development but, if you are new to these concepts, the Kiro announcement blog is a good way to get up to speed. Rather, the point I want to discuss in this post is how, over time, expressing the intent (in English) of what the software developers are building is becoming a reality.
To express this past progression and how I envision it to evolve over time, I use a mental framework that centers around the concept of "source of truth". It focuses on the assets developers are producing which reflect the value of their work and their job. Today, this asset is the "source code" they generate and it's what they check in into their git repositories. But will the source code always represent the source of truth going forward?
I will offer the visual representation of this framework first, and then I will describe how I think about it:
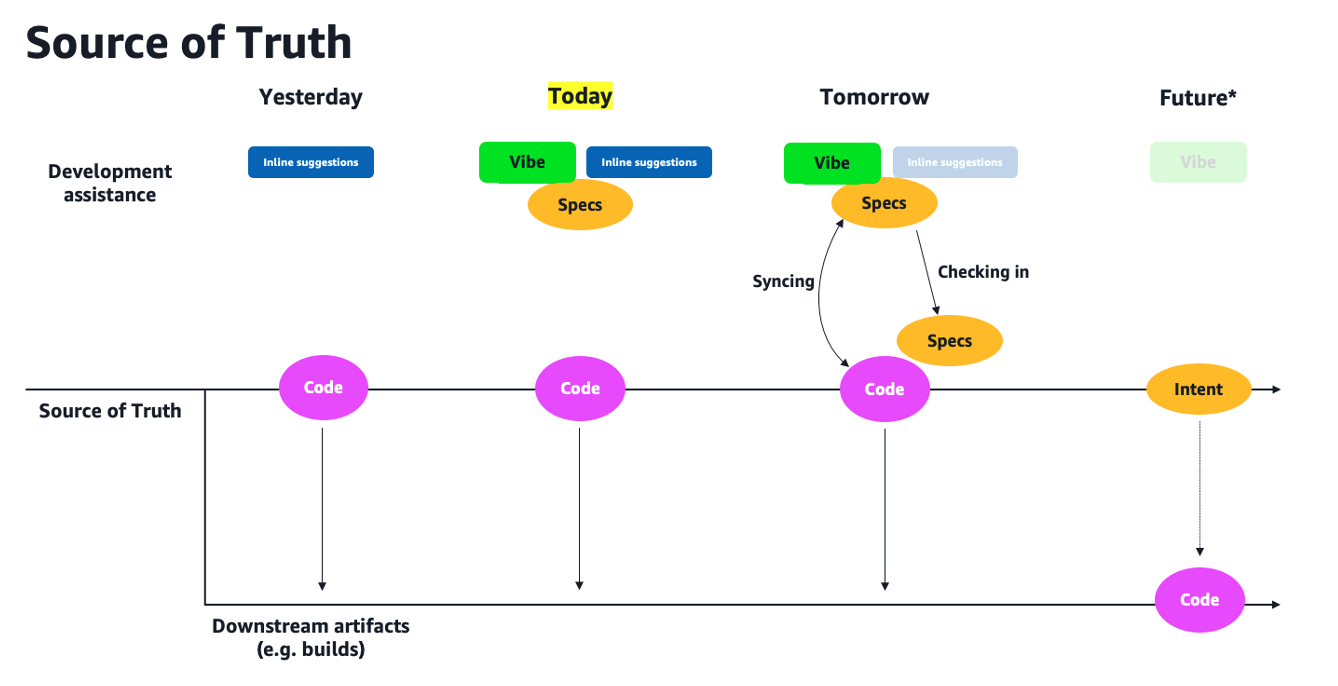
We are coming from a world (Yesterday) where the source of truth (i.e. the asset) is represented by the source code that developers generated. This could have done using some form of programming assistance techniques such as IDE linters, auto-complete and inline suggestions. At the end of the day, these techniques were a mean to an end (the code).
Today, these techniques have evolved and include things like vibe coding and specifications for specs-driven development. What hasn't changed is that these techniques are ephemeral. That is, when a developer builds something with vibe coding techniques, the process and the prompting to get to the result get lost. What remains is the code that the developer has produced (the asset that gets checked in into git).
I have already started to see some seeds of the discussions we will be having tomorrow: what are specifications? Are they important to keep track of? Are they an integral part of the code I generated? Should I keep the specs in sync with the code they produced (e.g. when I change the code editing it manually)? Should I check the specs into the git repository? These are some of the questions that I am already hearing from developers using Kiro. I suspect the next few months and years will be dominated by figuring out how to deal with these questions.
Fast-forward to a future state (which I defined in my talks as "around the time I will retire"), I imagine a world where the intent (expressed in English) may be the source of truth of the work of developers and what they will ultimately keep track of by checking it in into git repositories. Note I have said intent and not specs because I want to make this concept as general as possible (who knows what there will be in 6 or 12 months down the road? maybe specs v2 or maybe something even completely different?). If there is something this space has taught me is that no "hot topic" has survived for more than a year. But I do believe the fundamental of these abstractions (from programming languages to human languages) will not change and the importance of the intent Vs. the code that gets produced off it is here to stay with us. In this world the code may simply be treated as a downstream "build" artifact in a pipeline. Much like a CloudFormation template today is considered a downstream artifact of a cdk synthesize.
I am obviously aware that this sounds like science fiction (for now) and there is a good reason why I (half) joke that this will possibly only happen after I retire (which is, sadly, not happening any time soon). There are clear and well-known challenges around how to use the English to describe at the proper level of details the behavior of a machine program (without actually programming that behavior). There are also obvious challenges related to verification and validation that what is generated at build time of the code adheres to the intent the user has declared. On this front, there is solid work we are doing with Kiro and specs, leveraging Automated Reasoning techniques (e.g. Property-based testing) . And of course there are the canonical challenges around security.
All in all, we will not wake up one morning and perfect code will automagically generate from a PRD (err, intent) we checked in the night before. It will likely be a marathon towards that state with continuous and incremental improvements that will organically bring us all there. But given one year in generative AI is worth three dog years, perhaps this will come sooner than we all think?
Exciting times for sure.
Massimo.