The Cloud Spectrum and the Amazon Dilemma
Last week at VMworld 2013 in San Francisco, among various other sessions, I presented "a Parallel between vCloud Hybrid Service and Amazon Web Services" (session #PHC5123). It went overall fairly well with lots of positive feedbacks. The one that stood out for me was a tweet from Jack Clark.
I enjoyed reading that feedback because that meant I successfully managed to "...NOT doing this session... the Microsoft way". Also, since I always try to be a trusted advisor, I appreciated that my name was associated to the word "honesty".
Funny enough, It was only later that I realized who Jack is and why he was at my session. It's always a pleasure and an honor being quoted on The Register. Particularly in the same paragraph with Bezos and in the same article with Mathew Lodge and Raghu Raghuram.
However, I am very disappointed that Jack didn't pick up the strong statements and commitments I made about the Outback [steakhouse] and their blooming onion (I am still unsure how I ended up talking about those in a vCHS/AWS session, but anyway...).
Instead he decided to quote me on the serious stuff. Which is kind of boring.
Kidding aside (for a moment), I tried to spend 80% of that session discussing the technical parallels between the two services: "this is how it works in AWS, this is how the same thing works in vCHS". I tried to cover all three major areas such as compute, storage and network.
The remaining 20% of the presentation was used to provide an industry positioning of the different services. Admittedly a highly debatable topic and, arguably, an academic discussion I should have entertained on my private blog rather than in a VMworld breakout session. But it is what it is, customers (and Jack) seem to have enjoyed it so...
Now that we are here (on my private blog) I'd like to try to clarify my (personal) thoughts and expose them to my readers that were not in the session.
The first concept I described is what I call the Cloud Spectrum. This is a natural follow on to the concept I introduced in the Cloud Magic Rectangle.
Make also sure that, as a background, you read the TCP-clouds, UDP-clouds, "design for fail" and AWS blog post as well as the vCloud, OpenStack, Pets and Cattle post.
In my VMworld session, I tried to reduce / collapse the three columns I had in the Cloud Magic Rectangle into two major deployment models:
“Enterprise” (for lack of a better name)
-
Traditional Linux / Windows Applications
-
Hybrid
-
Resilient (HA, DR)
-
Built-in Enterprise Backup / Restore of VMs & Files (Pets)
-
Typically consumed with a GUI
-
Compute Instances (e.g. VM) and Storage (e.g. VMDK) usually managed as “one entity”
-
Limited number of VMs, fairly stable in number
-
More geared towards a traditional SQL model (always consistent)
-
Fixed Cost - Capacity Planning
“Design for Fail” (for lack of a better name)
-
Cloud Applications
-
Standalone
-
Resiliency built into the Application (cloud infrastructure not resilient)
-
No heavy need to backup instances (Cattle)
-
Typically consumed via an API
-
Compute Instances (e.g. EC2) and Storage (e.g. EBS, S3) usually managed separately
-
Huge amount of VMs, quickly varying in number (“we can auto scale 50.000 VMs in 5 minutes”)
-
More geared towards a NoSQL model (eventually consistent)
-
PAYG – No need to assess capacity needs
The characteristics of these models are described in more details in the posts I linked above.
At that point, I thought there was a need to visualize how different public cloud services map on a graph that represents the progression (from left to right) of an IT continuum moving from the first deployment model (Enterprise) towards the second deployment model (Design for Fail). That's in fact how I see IT evolving (over time).
Enter the Cloud Spectrum:
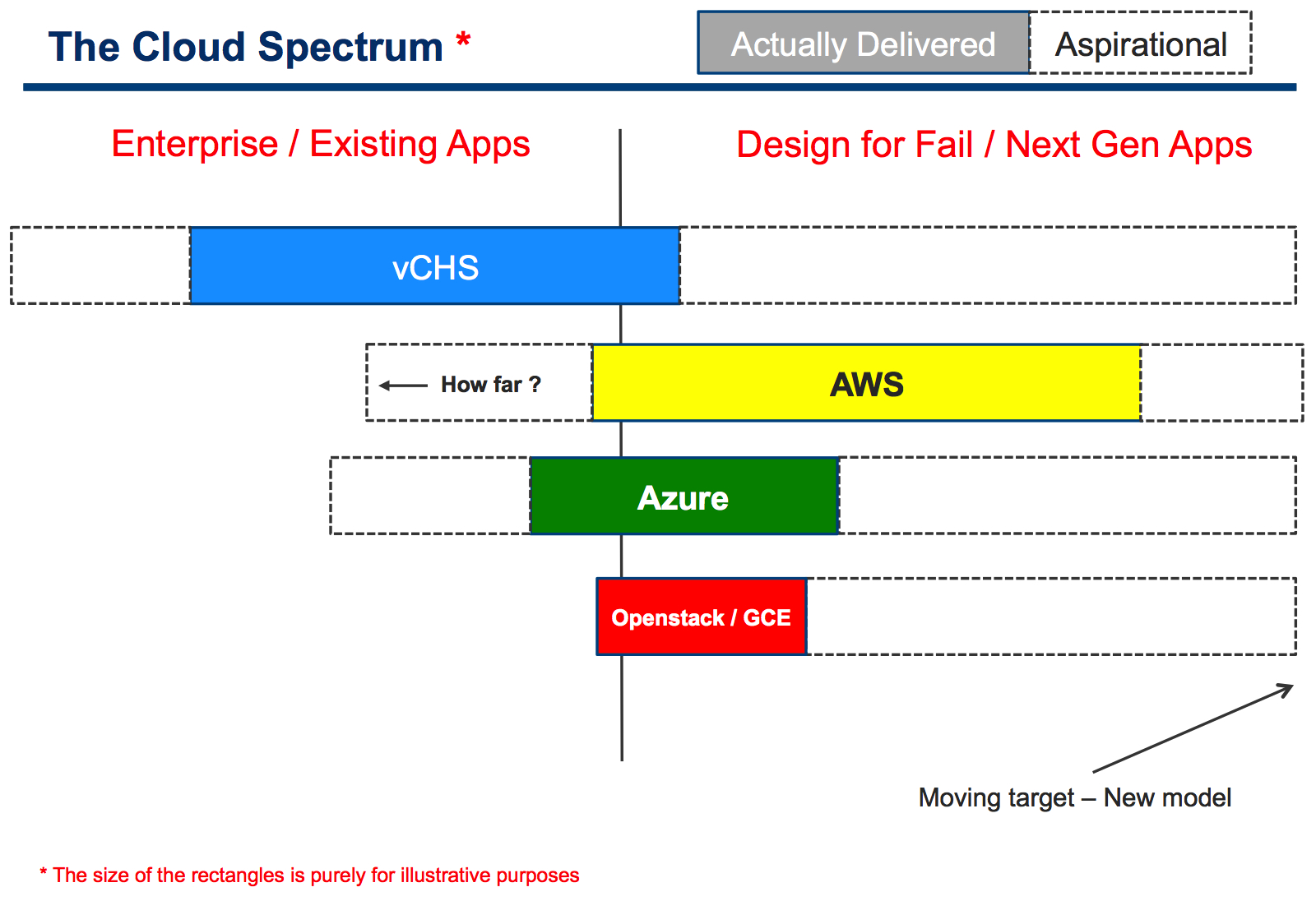
Solid colors represent where the services are currently delivering in the context of the spectrum. Dotted rectangles represent where the services are aspirationally moving to.
Note I don't seat in the board of directors in any of these companies so the ambitions I am calling out are speculative and based on common industry knowledge.
For example, I don't see GCE (Google Compute Engine) being engineered natively for scenarios involving scale up single image existing applications where the underlying platform can guarantee high availability and DR independently of the application itself (see again the the TCP-clouds, UDP-clouds blog post). You can argue that grouping together Openstack and GCE isn't right and that Openstack may be, aspirationally, trying to cover some (maybe not all) of the traditional enterprise workloads. Fair enough. Let's not start debating the details of the size and shape of those rectangles.
Apparently the IT world is moving from left to right. We all agree on that.
What we instead typically end up discussing is how fast the world is moving. My stance is that, on average, the speed is glacial. But that's me.
Pro-tip: the Netflix attitude is the exception, not the norm. I am also wondering whether this (move to the far right) will happen for everyone. One should start wondering when Google (and I mean, Google!) starts claiming that this No-SQL thing is just too hard. Quoting from the article:
"The reason Google built F1 was partly because of the frustration its engineers had found when dealing with non-relational systems with poor consistency problems".
and again:
"In all such [eventually consistent] systems, we find developers spend a significant fraction of their time building extremely complex and error-prone mechanisms to cope with eventual consistency and handle data that may be out of date."
Wow! Now, if engineers at Google can't cope with the challenges of eventually consistent scenarios, imagine the average developer Joe.
Sadly, I think Oracle will continue to suck your money for the foreseeable future. Sorry about that.
Funny enough, I just came across this interesting article from Ben Kepes. Not only pontificating on designing for fail is easier than actually designing for fail... but apparently not even AWS was able to properly design for fail their own services. That doesn't change anything about the awesomeness of the AWS services. It rather only speaks to how difficult it is to walk the talk (a problem every vendor has, VMware included).
As you can see from the slide (and as you can read from the press), vCHS has been introduced, initially, with a particular value proposition in mind. Having that said, there is no doubt there is a desire to cover many other use cases going forward, including the design for fail one and, more generally, all the space of the "new applications". The announcement that VMware will be offering CloudFoundry on top of vCHS is a step towards that direction.
In this Cloud Spectrum I am speculating that all other vendors are looking at this space but very few of them have a desire to support existing Enterprise applications that have not been designed with a "true cloud" in mind. Google is a good example of this and Microsoft not guaranteeing any SLA for single VMs is another sign of "yes I want to get Enterprise workloads but I am not doing a lot to make myself appealing for those". Your mileage may vary, consider me biased.
AWS is the 800 pounds gorilla in this discussion. Notice, in the Cloud Spectrum, that little note that says "how far?".
Enter the Amazon Dilemma:
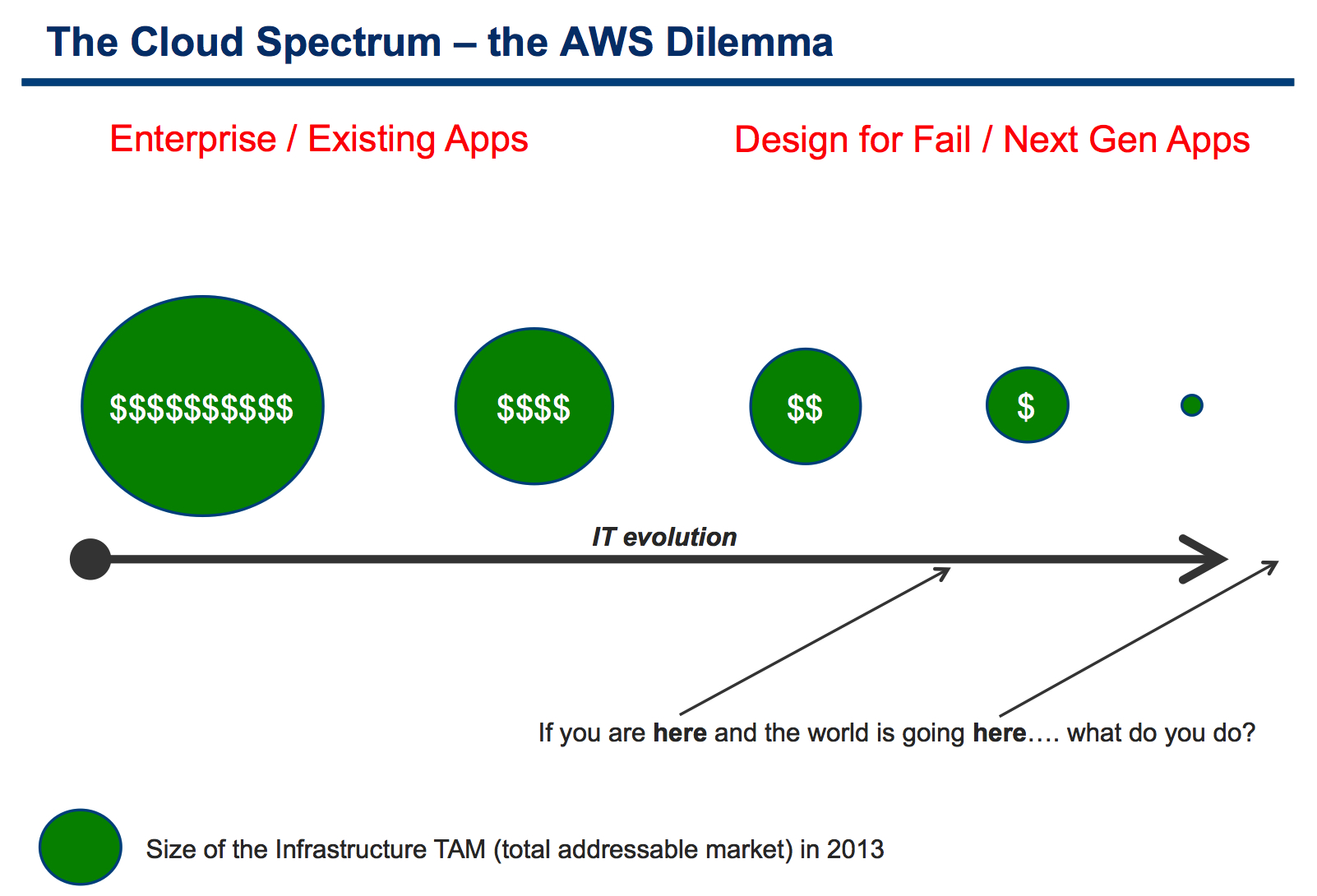
This should be self explaining and you don't need an MBA from Stanford to get it.
Consider that AWS was speculated to make roughly 2B$ in 2012. To put things in perspective, the total IT spending in 2012 was in the ballpark of 3.6T$ (trillion dollars). In other words AWS represents roughly 0.06% of the total IT spending.
Now, it is obvious that the AWS TAM isn't the entire IT spectrum (they don't have [yet] printing as a service, luckily for HP) but it would be fair IMO to say that for every dollar spent on AWS, customers spend several hundred dollars for buying comparable hardware, software and services for traditional Enterprise deployments (typically on-prem, some from traditional outsourcing).
So here I am postulating the Amazon Dilemma:
If you are here [in the design for fail space], you think the world is going there [towards the extreme of design for fail] and you know that the bulk of money to be made for the foreseeable future are there [on the far left side of the spectrum]... what do you do?*
I'd pay a ton to be in those rooms and listen to the arguments business people are making to purist cloud engineers: "We need to grab those money!". "No way! That is not cloud!".
I have speculated two years ago that AWS may be looking at introducing more Enterprise characteristics into their cloud offering. Quoting myself:
"Amazon is full of smart people and I think they are looking into this as we speak. While we are suggesting (to an elite of programmers) to design for fail, they are thinking how to auto-recovery their infrastructure from a failure (for the masses). I bet we will see more failure recovery across AZs and Regions type of services in one form or another from AWS. I believe they want to implement a TCP-cloud in the long run since the UDP-cloud is not going to serve the majority of the users out there"
This is an interesting dilemma AWS is facing. But more interesting will be to look at the faces of the clouderati if / when this happens.
Massimo.