The Italian Elections and the Case for Cloudburst
A few days ago we had a big election day in Italy for renewing a good part of the public local administration. For and in itself this wasn't a big deal and something that wouldn't have generated a lot of attention among the 60M people living here. However, without getting into a lot of details, suffice to say that this turned into yet another "do you like Mr. Berlusconi? Yes or No?" type of referendum. And this of course generated a lot of curiosity around the results. So what do most of the people working in an office do at 3PM when they close the voting? They connect to their favorite on-line news web sites and have a look at the exit polls statistics. And I am no different: killed by curiosity, I opened another tab on my browser and quickly pointed it to "http://corriere.it" the internet home of the most important Italian newspaper: Il Corriere della Sera. What does this have to do with cloudburst you may be wondering? Well it does have to do with cloudburst because, after waiting a minute or so on the "waiting for corriere.it", this is what I was able to get (red emphasis and sketched question mark is mine):
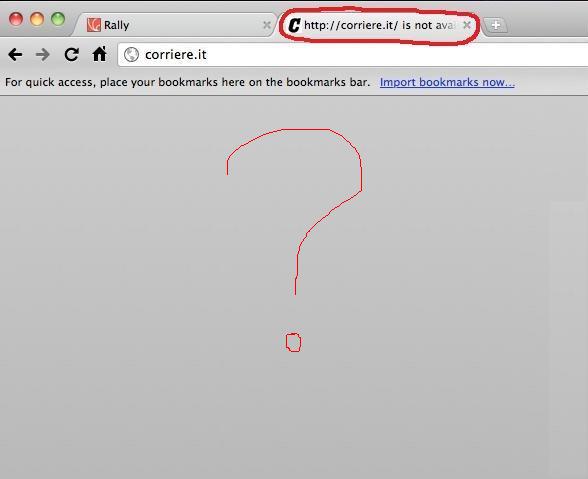
How disappointed?! By the way what I have experienced personally is not anything new. It happens very often and all the times "something interesting" happens. Look at what happened when Michael Jackson passed away for example.
Now, I know that there have been a lot of bashing regarding the concept of being able to "cloudburst" into the cloud. I believe this is due to the fact people tend to jump to extreme use cases. If you associate the term cloudburst to what it actually means in a non-IT world then yes you may think about a particular use case where your IT infrastructure may need to react in nano-seconds to an unanticipated, and somewhat catastrophic, event that may last 30 seconds or so. From Wikipedia:
"Cloudbursts descend from very high clouds, sometimes with tops above 15 kilometers...Meteorologists say the rain from a cloudburst is usually of the shower type with a fall rate equal to or greater than 100mm (3.94 inches) per hour... During a cloudburst, more than 2 cm of rain may fall in a few minutes. When there are instances of cloudbursts, the results can be disastrous."
In a world where people think that the Facebook and Google infrastructures are the norm, it doesn't surprise me that someone may also think that that's the only cloudburst scenario (and no, I am not referring to Chris Hoff here, in fact I think he is one of the most realistic people I follow on twitter).
With the "Google and Facebook are the norm" mind-set, of course you are mentally led to think that an IT cloudburst is a fully automated process where your application can immediately react upon a sudden spike of connections and it goes out, automagically, deploying on-the-fly new instances of the application, modifying load balancer configurations to grab new traffic immediately. Oh, and of course it wouldn't be a "real" IT cloudburst if, after a few sub-seconds of idle time, all of these extra resources are decommissioned, automagically, and everything returns back to normal. Yeah, dream on. I bet you are saying it's "marketing bollocks"! Of course it is!
So, if that is the meaning you are associating to the term, I agree that all this IT cloudburst talking in the industry is, most of the time, just a bunch of marketing stuff (for the moment at least). Certainly I am not selling the idea that your site could go from 300 front end servers to 1,400 in a matter of milliseconds and contract back to 300 after a 18 seconds surge. All automagically. I am not that stupid.
My concept of cloudburst is a little bit different. And practical. I am a simple guy and a pragmatic person. I don't want to re-architect applications for failure or create a chaos-monkey programs that kill production workloads to test their resiliency. Call me an old-school IT boy, but I just want to be able to see the exit polls on http://corriere.it next time.
There are a couple of concepts regarding cloudburst that we should all consider. They are the reaction time and whether the triggering event is anticipated or not. The extreme example above obviously assume a near real-time reaction triggered by an unexpected event. What I have in mind is a much longer lead time to allow you to scale the resources associated to an event you can anticipate. Something like.... an election day for example (or a programmed marketing campaign for that matter or anything that come to your mind that has those two characteristics)!
No, we are not talking about doing this with "a spacecraft equipped with a warp drive that may travel at velocities greater than that of light by many orders of magnitude, while circumventing the relativistic problem of time dilation". We are not talking about micro-seconds response times. We are not even talking about a 4M$ titanic orchestrator product (that happens to come with an 8M$ bill worth of professional services to implement it). I am talking about deploying (yes even manually! How old school am I?) a few additional web servers in the cloud to cope with the anticipated demand so that I can look at my damn exit polls!
Let me state it very clear. I have no idea about the back-end infrastructure that Il Corriere della Sera is running. The only thing I know is that they are running Apache on Linux according to netcraft.com. I can also imagine that they are using a traditional SQL backend database (SQL Server? Oracle? MySQL? DB2? Who knows!?).
I am not even sure whether they are a VMware customer (but one can always hope). Let me speculate they have 6 load balanced web servers (just off the top of my head). They could be 3 or 9, it doesn't make any difference when they are exhausted anyway! Whether they are virtual or physical I don't care; does it make a difference in the end? I don't think so. An exhausted set of virtual resources produce the same result compared to an exhausted set of physical resources in the end: a browser error! Last but not least I'd speculate that, given the nature of the on-line service they offer, the presentation tier (web along with any application logic that goes with it) is the bottleneck rather than the backend data repository or the network. So let's say their deployment looks similar to this:
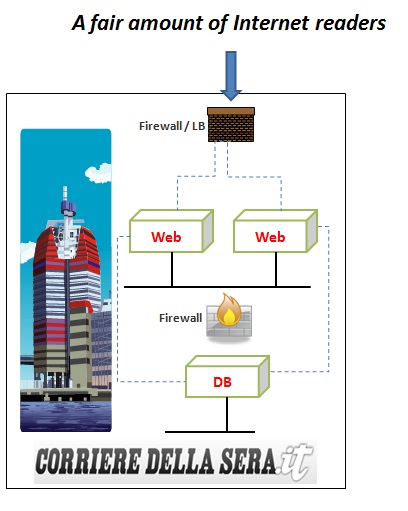
So, if my assumptions are correct (yet to be demonstrated), why not "cloudbursting"? Not in the extreme Star Trek sense above. But rather in a more pragmatic sense where you could ideally sign up with a public IaaS on-line service provider to get access to Pay-As-You-Go resources and double your front end-access just before you need it. Ideally this cloudburst should happen in a public cloud because the whole idea of this extra spike is that it is going to use resources that you don't have in house. Why not? Well, because most customers (if not all) out there are not Google nor Facebook and they may not have 40 spare servers in house at any point in time for capacity overflow! These customers may not have a critical mass of resources in house to deal with these peaks? You are not Google? You are no one! Come on, wake up folks! Life in the real data centers is not as fun as in the Google and Facebook
What I have in mind to make http://corriere.it more scalable is actually fairly simple and doesn't require them to turn into a new Google. While the scenario below could easily be implemented using different technologies (such as for example an on-premise physical deployment extended to AWS virtual servers) I am going to describe, at a high level, what you'd need to do if you were a VMware customer with a vSphere deployment on premise extending to a vCloud public Service Provider. I am just more familiar with this stack, that's why I am describing it:
- A few days upfront "the event" you subscribe with a vCloud Service Provider. This entitles you to access public resources with a PAYG model. It shouldn't take more than 104 minutes.
- Depending on the nature of the connections and related security you need to have, you can ask the provider to setup a VPN between your remote virtual data center and your own on-premise vSphere deployment. For more background on how this could be done you can read this. This may be required if the web/application servers need to connect to a back-end database that is not reachable from outside the organization firewall (very likely).
- You can then deploy new web/application server instances from vCenter; this may be as easy as a clone of an existing web/application instance or it may require slightly more manual work like if you were to start from a generic OS template . This isn't very different from what you'd need to do if you were to deploy a new on-premise instance of the same web/application server.
- When you are done with that additional virtual server deployments you can then easily either manually export/import these instances from the on-premise vSphere deployment into your remote virtual data center, or you can use vCloud Connector to move these workloads if you are a GUI aficionados. Moving stuff around compatible infrastructures is obviously a huge plus in this case as it simplify a lot of the work. This may not be the case if your source is a physical environment and/or your target is AWS.
- Last but not least you need to reconfigure the load balancer to include these new front-end instances to make them part of the http://corriere.it site.
- When "the event" is gone and the traffic is notably back to normal you can decide to reconfigure the load balancer and decommission these additional front-end instances in your remote virtual data center in the public cloud to avoid incurring into additional charges due to the PAYG model.
This is not rocket science. You can even try to optimize the process above a little bit so that if you have 3 or 4 or 7 of these "events" in a year you can commission and decommission these workloads a little bit more efficiently. This can be done either manually or with a little bit of simple scripting, still not having to spend a 4M$ tax for a "cloud" orchestrator (i.e. shooting a fly with a bazooka). Same thing for the load balancing. No I am not talking about a "global super fancy" load balancer that can provide workload balancing across sites with built-in DR algorithms, locality optimizations and the like. I am talking about the same load balancer you used to use that is now also pointing to the remote web servers via the established VPN tunnel. Sexy? Not at all but remember we are not talking about optimizing the datacenter and/or the network. We are just trying to fix a problem that is server capacity exhaustion. If your problem is network related (latency and bandwidth) then you may want to do something else (perhaps using a global super fancy load balancer, why not?). So what I am suggesting is to extend the infrastructure like this:
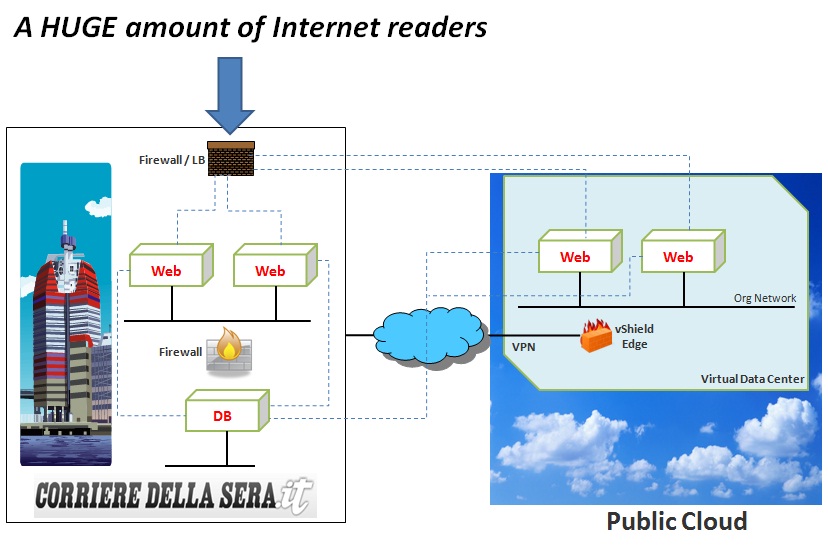
Note we have always been talking about events that can be anticipated and that can give to Il Corriere della Sera IT administrators the lead time required to provision new cloud resources. The same concept could apply for unanticipated events provided that the duration of "the event" is long enough to make the provisioning worth it. If an unanticipated big event generates insane amount of traffic for a few days (and you have a clean and structured semi-automated provisioning methodology) you may think about cloudbursting. If, on the other hand, an unanticipated event generates a lot of traffic for about 36 hours (and your provisioning is going to be manual with some lengthy customization work) it may not make a lot of sense to cloudburst. Another picture to fix the concept in your mind (hopefully).
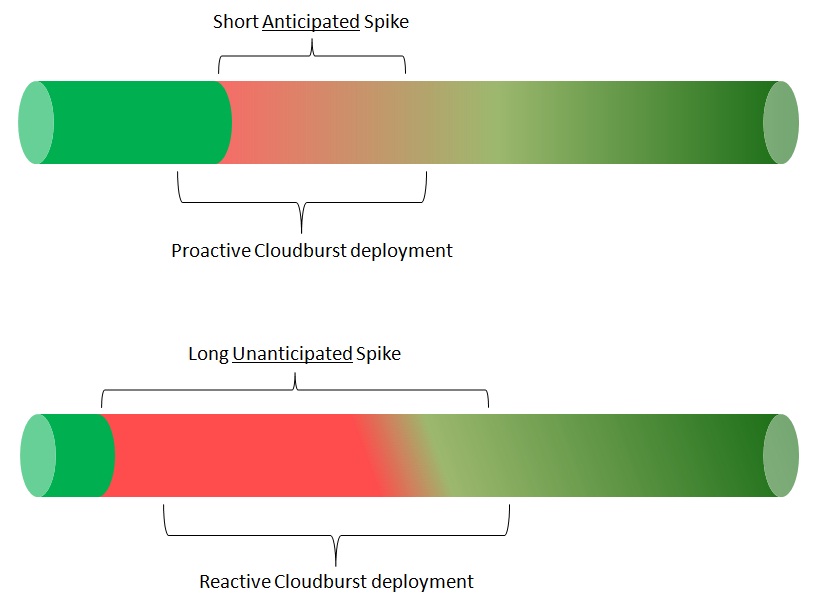
Is this the sexy sub-second type of IT cloudburst most Google-minded people think about? Probably not! But, hell, at least I will be able to see the exit polls next time. This is in fact a relatively low investment, of money and time, to produce (potentially) a significantly better on-line service. But if you are in the business of over-engineering things you may perhaps disagree with my point of view.
My next action item is to go and talk to Il Corriere della Sera now to see if this makes any sense to them! Which is the only thing that matters at this point!
Massimo.